Are you struggling with maintaining database consistency when multiple transactions happen at the same time? Worried about how concurrent transactions might mess up your data?
We have all experienced this. Conflict serializability is a very important concept when it comes to databases.
Conflict serializability in DBMS is one of the fundamental factors that ensure consistency and correctness in our database despite concurrent transactions. Let’s dive into what it is, how it works, and why it’s important.
Defining Conflict Serializability in DBMS
Conflict serializability sounds complex, but it’s quite simple. It’s a way to ensure that the outcome of transactions running at the same time is the same as if they had run one after the other.
Imagine standing in line in a coffee shop. Even if two people order at the same time, their orders are processed in a way that does not lead to confusion. This is what conflict serializability does for our database.
When transactions happen simultaneously, they can interfere with each other, causing conflicts. If we can rearrange the operations of these transactions to remove conflicts without changing the final result, then the schedule is conflict serializable.
In essence, it means that despite the order of operations, the end result remains consistent.
Get curriculum highlights, career paths, industry insights and accelerate your technology journey.
Download brochure
Identifying Conflicting Operations in Transactions
To understand conflict serializability in DBMS, we first need to identify conflicting operations. These are pairs of operations that can’t happen at the same time without causing issues.
Here’s how we spot them:
They belong to different transactions.
They operate on the same data item.
At least one of them is a write operation.
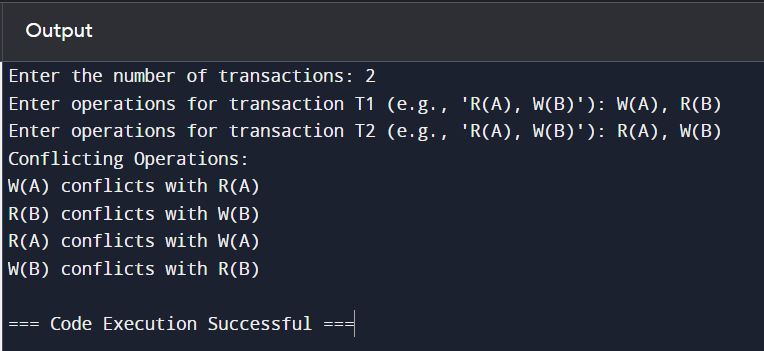
Let’s break this down with an example. Suppose we have two transactions:
Transaction T1:
Read1(A)
Write1(A)
Transaction T2:
Write2(A)
Read2(A)
In this case:
Read1(A) and Write2(A) are conflicting because they happen on the same data item A, and one is a write.
Write1(A) and Read2(A) are also conflicting for the same reason.
Write1(A) and Write2(A) conflict because they both write to A.
Example Table of Conflicting and Non-Conflicting Operations:
Operation 1
Operation 2
Conflict Status
Read1(A)
Read2(A)
Non-conflicting
Read1(A)
Write2(A)
Conflicting
Write1(A)
Read2(A)
Conflicting
Write1(A)
Write2(A)
Conflicting
Read1(A)
Write2(B)
Non-conflicting
To make it clearer, let’s consider a unique example:
Practical Coding Examples of Conflict Serializability with Unique Scenarios
Ever wondered how to spot and handle conflicts in your database transactions? Let’s dive into some unique examples to clarify conflict serializability in DBMS.
Example Scenario 1:
Transaction T1:
Write1(B)
Read1(C)
Transaction T2:
Read2(B)
Write2(C)
In this scenario:
Write1(B) and Read2(B) are conflicting because they both deal with B, and one is a write.
Read1(C) and Write2(C) are conflicting because they both deal with C, and one is a write.
By identifying these conflicts, we can work on rearranging the operations to ensure our transactions don’t interfere with each other in harmful ways.
Let’s look at a simple code snippet that helps us identify conflicts in a transaction schedule. This code takes user input for transactions and checks for conflicts:
def get_transactions():
transactions = []
num_transactions = int(input("Enter the number of transactions: "))
for i in range(num_transactions):
transaction = input(f"Enter operations for transaction T{i + 1} (e.g., 'R(A), W(B)'): ")
transactions.append(transaction.split(', '))
return transactions
def check_conflicts(transactions):
conflicts = []
for i, trans1 in enumerate(transactions):
for j, trans2 in enumerate(transactions):
if i != j:
for op1 in trans1:
for op2 in trans2:
if (op1[0] == 'W' or op2[0] == 'W') and (op1[1:] == op2[1:]):
conflicts.append((op1, op2))
return conflicts
def main():
transactions = get_transactions()
conflicts = check_conflicts(transactions)
if conflicts:
print("Conflicting Operations:")
for conflict in conflicts:
print(f"{conflict[0]} conflicts with {conflict[1]}")
else:
print("No conflicts found.")
if __name__ == "__main__":
main()
Sample Output:
This code helps us identify where conflicts occur, making it easier to understand and manage our transaction schedules.
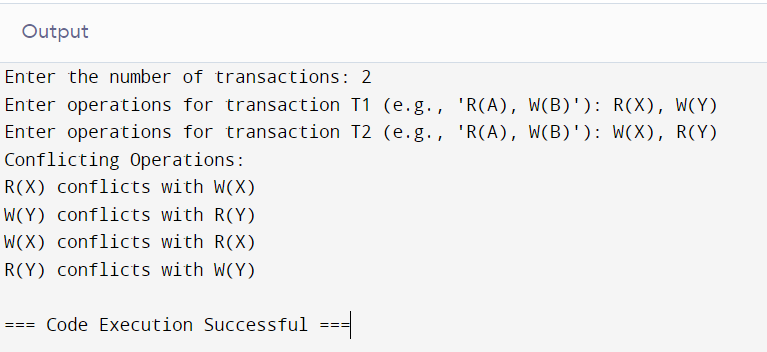
Example Scenario 2:
Imagine we have two transactions:
Transaction T1:
Read1(X)
Write1(Y)
Transaction T2:
Write2(X)
Read2(Y)
In this case:
Read1(X) and Write2(X) are conflicting.
Write1(Y) and Read2(Y) are also conflicting.
Here’s how we can write a Python script to check these conflicts:
def get_transactions():
transactions = []
num_transactions = int(input("Enter the number of transactions: "))
for i in range(num_transactions):
transaction = input(f"Enter operations for transaction T{i + 1} (e.g., 'R(A), W(B)'): ")
transactions.append(transaction.split(', '))
return transactions
def check_conflicts(transactions):
conflicts = []
for i, trans1 in enumerate(transactions):
for j, trans2 in enumerate(transactions):
if i != j:
for op1 in trans1:
for op2 in trans2:
if (op1[0] == 'W' or op2[0] == 'W') and (op1[1:] == op2[1:]):
conflicts.append((op1, op2))
return conflicts
def main():
transactions = get_transactions()
conflicts = check_conflicts(transactions)
if conflicts:
print("Conflicting Operations:")
for conflict in conflicts:
print(f"{conflict[0]} conflicts with {conflict[1]}")
else:
print("No conflicts found.")
if __name__ == "__main__":
main()
Example Output:
Using Precedence Graphs to Check Conflict Serializability
How do we confirm if a schedule is conflict serializable in DBMS? We use precedence graphs. These graphs help us see if transactions can run in a specific order without conflicts.
Steps to Create a Precedence Graph:
Identify Nodes: Create a node for each transaction.
Draw Edges: For every conflict, draw a directed edge from one transaction to another.
Check for Cycles: If there’s no cycle, the schedule is conflict serializable.
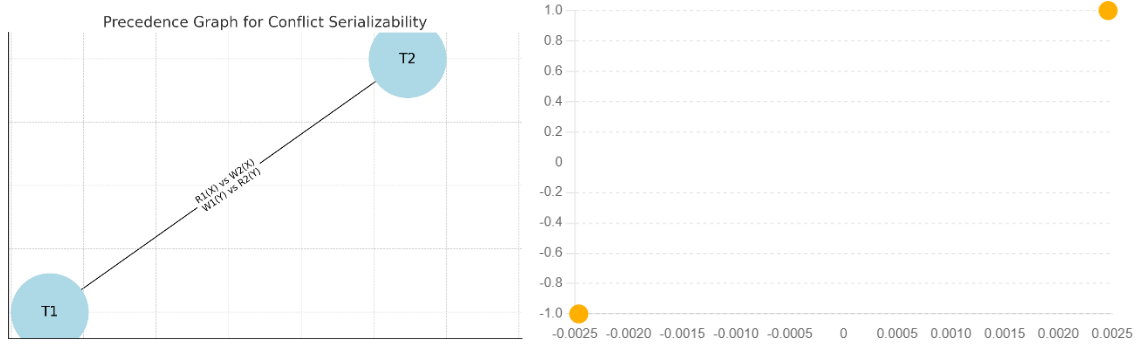
Example Graph:
Let’s take our first example and draw its precedence graph.
Transactions:
T1: Read1(X), Write1(Y)
T2: Write2(X), Read2(Y)
Conflicts:
Read1(X) vs Write2(X) (Edge from T1 to T2)
Write1(Y) vs Read2(Y) (Edge from T1 to T2)
The graph shows a clear path with no cycles, indicating its conflict is serializable.
Understanding Conflict Equivalence in DBMS
Why does conflict equivalence matter? It helps us see if we can rearrange transactions to avoid conflicts without changing the outcome.
Key Points:
Same Transactions: Both schedules must involve the same transactions.
Order of Operations: Conflicting operations must maintain the same order.
Example:
Schedule S1:
T1: Read1(A), Write1(A)
T2: Write2(A), Read2(A)
Schedule S2:
T2: Write2(A), Read2(A)
T1: Read1(A), Write1(A)
In S1, T1’s operations come before T2’s, and in S2, T2’s operations come first. If we can swap non-conflicting operations to transform S1 into S2 (or vice versa), they’re conflict equivalent.
By understanding conflict equivalence, we can ensure our database operations run smoothly and consistently.
Practical Coding Example:
Here’s a Python code to check if two schedules are conflict equivalent:
def are_conflict_equivalent(schedule1, schedule2):
conflicts1 = set()
conflicts2 = set()
def find_conflicts(schedule, conflicts):
for i in range(len(schedule)):
for j in range(i + 1, len(schedule)):
if schedule[i][1:] == schedule[j][1:] and (schedule[i][0] == 'W' or schedule[j][0] == 'W'):
conflicts.add((schedule[i], schedule[j]))
find_conflicts(schedule1, conflicts1)
find_conflicts(schedule2, conflicts2)
return conflicts1 == conflicts2
schedule1 = ['R1(A)', 'W1(A)', 'W2(A)', 'R2(A)']
schedule2 = ['W2(A)', 'R2(A)', 'R1(A)', 'W1(A)']
if are_conflict_equivalent(schedule1, schedule2):
print("Schedules are conflict equivalent.")
else:
print("Schedules are not conflict equivalent.")
Enhanced Concurrency: Allows multiple transactions to run without conflicts.
Disadvantages:
Complexity: It can be complex to implement.
Reduced Performance: Might introduce delays due to conflict resolution.
Limited Concurrency: Sometimes limits the number of concurrent transactions to avoid conflicts.
Conclusion
Conflict serializability in DBMS is essential for maintaining the integrity and consistency of transactions. By identifying conflicts, using precedence graphs, and checking for cycles, we can ensure our transactions run smoothly.
In this blog, we explored conflict serializability in DBMS. We learned to identify conflicting operations, create and analyse precedence graphs, and understand conflict equivalence. We also discussed the advantages and disadvantages of conflict serializability.
By mastering these steps, we can maintain a reliable and efficient database system, ensuring smooth and conflict-free transaction processing.
FAQs
What is the difference between conflict serializability and view serializability?
Conflict serializability focuses on the order of conflicting operations. View serializability ensures the final result of transactions is the same, regardless of order.
How does a precedence graph help determine conflict serializability?
A precedence graph shows the order of transactions. If there are no cycles, the schedule is conflict serializable.
Can a schedule be conflict serializable but not view serializable?
No, if a schedule is conflict serializable, it is always view serializable. The reverse is not always true.
What are non-conflicting operations?
Non-conflicting operations either act on different data items or involve at least one read operation on the same item.
Why is conflict serializability important in DBMS?
It ensures transactions run correctly and the database remains consistent. It helps prevent conflicts that could corrupt the database.