Have you ever wondered why your database sometimes gives inconsistent results? We all have faced this issue when dealing with multiple transactions running at the same time.
This is where serializability comes into play. It ensures that our database remains consistent, no matter how many transactions occur simultaneously.
In simple terms, serializability checks if a schedule (the order of transactions) produces the same result as some serial order of the same transactions.
Now, there are two types of serializability: conflict serializability and view serializability. While conflict serializability is easier to check, it’s not always sufficient.
That’s where view serializability in DBMS steps in, providing a more flexible approach.
Now, let’s dive into view serializability. View serializability ensures that the result of a concurrent schedule is the same as a serial schedule. It means that even if transactions overlap, they produce the same output as some serial order.
Key Differences Between Conflict and View Serializability
Ever wondered why sometimes the database fails even though you checked for conflicts? We all want our databases to run smoothly, but sometimes conflict checks aren’t enough. That’s where view serializability in DBMS comes into play.
Conflict Serializability:
Check if a schedule can be transformed into a serial schedule by swapping non-conflicting operations.
Uses precedence graphs.
If no cycles are found in the graph, the schedule is conflict serializable.
View Serializability:
Goes a step further than conflict serializability.
Ensures the final output is the same as a serial schedule.
Handles cases where conflict serializability fails due to cycles in the graph.
Why do we need both? Sometimes, conflict serializability can’t determine if a schedule is consistent when cycles exist. View serializability fills this gap by checking the actual data values read and written by transactions.
Get curriculum highlights, career paths, industry insights and accelerate your technology journey.
Download brochure
Conditions for View Equivalence
Now, let’s break down the three conditions for view serializability in DBMS: These conditions help us ensure that the concurrent schedule produces the same result as a serial one.
Initial Read Condition:
The first read of a data item in both schedules must be the same.
Example:
Schedule S1: T1 reads A.
Schedule S2: T1 also reads A first.
Updated Read Condition:
If a transaction reads a value written by another transaction, it must read the same value in both schedules.
Example:
Schedule S1: T2 reads A updated by T1.
Schedule S2: T2 reads the same A updated by T1.
Final Write Condition:
The final write of a data item must be the same in both schedules.
Example:
Schedule S1: T3 writes A last.
Schedule S2: T3 also writes A last.
Example of View Serializability
Let’s look at an example:
Schedule S1:
T1: read(A), write(A)
T2: read(A), write(A)
Schedule S2:
T1: read(A), write(A)
T2: read(A), write(A)
In S1, T1 reads and writes A first, followed by T2. In S2, the order is the same. Both schedules are view equivalent because they meet all three conditions.
Step-by-Step Process to Check View Serializability
Checking for view serializability in DBMS might sound tricky, but it’s straightforward if we follow these steps.
Method 1: Checking View Equivalence
1. List Operations by Transaction:
Write down all operations for each transaction in the schedule.
Example:
Schedule S1:
T1: read(A), write(A)
T2: read(A), write(A)
2. Compare Initial Reads:
Ensure the initial reads in both schedules match.
Example:
S1: T1 reads A.
S2: T1 reads A.
3. Check Updated Reads:
Verify that transactions read the correct updated values.
Example:
S1: T2 reads A after T1 updates it.
S2: T2 reads the same updated A from T1.
4. Confirm Final Writes:
Ensure the final writes are the same in both schedules.
Example:
S1: T3 writes A last.
S2: T3 also writes A last.
Method 2: Utilizing Precedence and Dependency Graphs
1. Create a Precedence Graph:
Draw nodes for each transaction.
Add directed edges based on read-write dependencies.
Example:
T1 -> T2 (T1 writes B, T2 reads B).
2. Check for Cycles:
Look for cycles in the graph.
If no cycles exist, the schedule is conflict serializable.
Example:
Graph without cycles: Conflict serializable.
Graph with cycles: Move to dependency graph.
3. Create a Dependency Graph:
Add nodes and edges based on actual data dependencies.
Example:
T1 reads X, T2 writes X.
T3 writes Y, T2 reads Y.
4. Analyse the Graph:
Ensure no cycles exist in the dependency graph.
If no cycles, the schedule is view serializable.
Example:
No cycles in the graph: View serializable.
Cycles in the graph: Not view serializable.
Example Using Method 2
Let’s create a real example:
Schedule S3:
T1: read(B), write(B)
T2: read(B), write(B), read(C), write(C)
T3: read(C), write(C)
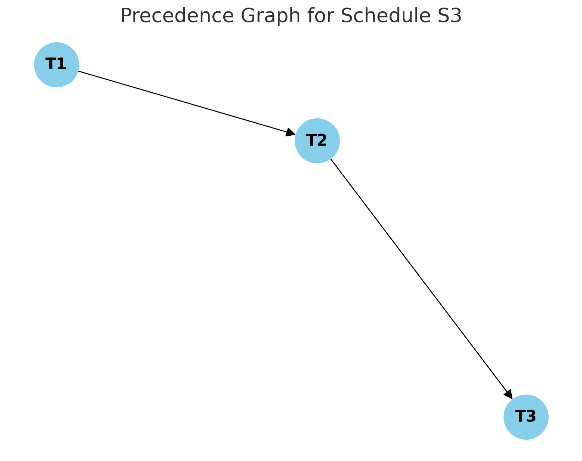
We can create a precedence graph:
T1 -> T2 (T1 writes B, T2 reads B).
T2 -> T3 (T2 writes C, T3 reads C).
Check for cycles:
If there are no cycles, it’s conflict serializable.
If cycles exist, use a dependency graph.
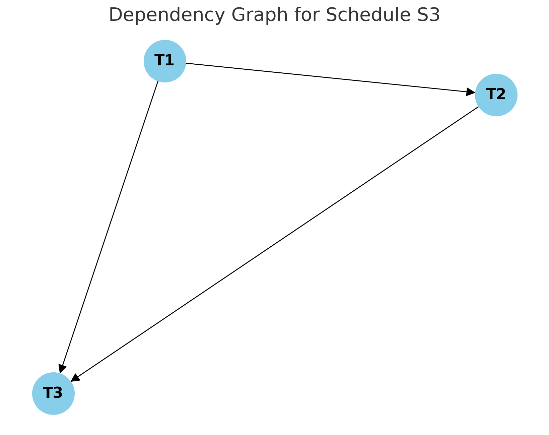
Next, create a dependency graph:
T1 reads B, T2 writes B.
T3 reads C, T2 writes C.
Check the graph for cycles:
If none exist, the schedule is view serializable.
In this example, there are no cycles, so the schedule is view serializable.
The precedence graph illustrates the relationships between transactions based on their read-write dependencies.
The dependency graph shows the execution order of transactions based on their dependencies.
Examples of View Serializability with Unique Schedules
Ever wondered if your schedule is view serializable or not? Let’s dive into some examples to see how we can figure this out. We’ll use simple and unique schedules to make this clear.
Example 1: Simple Schedule
Let’s consider the following schedule:
Schedule S1:
T1: read(A), write(A)
T2: read(A), write(A)
Is this view serializable? We need to check the three conditions: initial read, updated read, and final write.
Initial Read: T1 reads A first in both schedules.
Updated Read: T2 reads A after T1 writes A in both schedules.
Final Write: T2 writes A last in both schedules.
Since all conditions are met, S1 is view serializable.
Python Code Example:
# Function to check view serializability for simple schedules
def check_view_serializability_simple(transactions):
initial_read = {}
final_write = {}
reads = {}
for t in transactions:
for op in t:
action, item = op[0], op[1]
if action == 'r':
if item not in initial_read:
initial_read[item] = t[0]
if item not in reads:
reads[item] = []
reads[item].append(t[0])
if action == 'w':
final_write[item] = t[0]
for item in reads:
if initial_read[item] != final_write[item]:
return False
return True
# Example schedule
transactions_simple = [
[('r', 'A'), ('w', 'A')],
[('r', 'A'), ('w', 'A')]
]
# Check view serializability
is_view_serializable_simple = check_view_serializability_simple(transactions_simple)
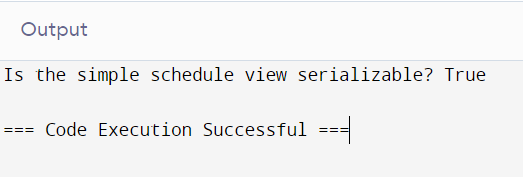
print(f"Is the simple schedule view serializable? {is_view_serializable_simple}")
Output:
Example 2: Slightly Complex Schedule
Now, let’s look at a more complex schedule:
Schedule S2:
T1: read(B), write(B)
T2: read(B), write(B), read(C), write(C)
T3: read(C), write(C)
To check if this is view serializable, we’ll follow the same steps.
Initial Read: T1 reads B first.
Updated Read: T2 reads B after T1 writes it, and T3 reads C after T2 writes it.
Final Write: T3 writes C last.
Since these conditions hold, S2 is view serializable.
Python Code Example:
# Function to check view serializability for complex schedules
def check_view_serializability_complex(transactions):
initial_read = {}
final_write = {}
updated_read = {}
# Track initial reads, final writes, and updated reads
for t_id, t in enumerate(transactions):
for op in t:
action, item = op[0], op[1]
if action == 'r':
if item not in initial_read:
initial_read[item] = t_id
if item not in updated_read:
updated_read[item] = {}
if t_id not in updated_read[item]:
updated_read[item][t_id] = t_id
if action == 'w':
final_write[item] = t_id
# Check initial read condition
for item in initial_read:
if initial_read[item] != list(updated_read[item].keys())[0]:
return False
# Check updated read condition
for item in updated_read:
for t_id in updated_read[item]:
if t_id != initial_read[item] and t_id != final_write[item]:
return False
# Check final write condition
for item in final_write:
if item in updated_read and final_write[item] != list(updated_read[item].keys())[-1]:
return False
return True
# Example schedule
transactions_complex = [
[('r', 'B'), ('w', 'B')],
[('r', 'B'), ('w', 'B'), ('r', 'C'), ('w', 'C')],
[('r', 'C'), ('w', 'C')]
]
# Check view serializability
is_view_serializable_complex = check_view_serializability_complex(transactions_complex)
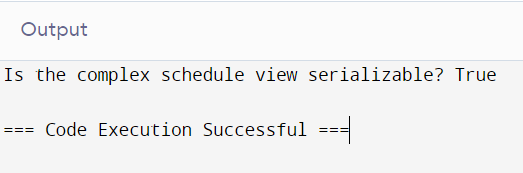
print(f"Is the complex schedule view serializable? {is_view_serializable_complex}")
Output:
Importance of Blind Writes in View Serializability
What are blind writes? And why should we care?
A blind write happens when a transaction writes a data item without reading it first. This can impact view serializability in DBMS. Let’s see how.
Blind Write Example
Consider this schedule:
Schedule S3:
T1: write(A)
T2: read(A), write(A)
Here, T1 writes A without reading it. This blind write can cause issues in determining if the schedule is view serializable.
Python Code Example:
# Function to check view serializability with blind writes
def check_view_serializability_blind_write(transactions):
initial_read = {}
final_write = {}
reads = {}
blind_writes = {}
for t in transactions:
for op in t:
action, item = op[0], op[1]
if action == 'r':
if item not in initial_read:
initial_read[item] = t[0]
if item not in reads:
reads[item] = []
reads[item].append(t[0])
if action == 'w':
final_write[item] = t[0]
if item not in blind_writes:
blind_writes[item] = []
blind_writes[item].append(t[0])
for item in reads:
if initial_read[item] != final_write[item]:
return False
return True
# Example schedule with blind write
transactions_blind_write = [
[('w', 'A')],
[('r', 'A'), ('w', 'A')]
]
# Check view serializability
is_view_serializable_blind_write = check_view_serializability_blind_write(transactions_blind_write)
print(f"Is the schedule with blind write view serializable? {is_view_serializable_blind_write}")
Output:
Conclusion
View serializability in DBMS ensures our schedules produce consistent results. It helps us manage overlapping transactions effectively.
In this blog, We examined key differences between conflict and view serializability and the conditions needed for view equivalence. Through detailed examples, we learned how to check for view serializability using methods like precedence and dependency graphs. We also highlighted the impact of blind writes.
By mastering these concepts, we can maintain robust and reliable databases, ensuring smooth and consistent transaction processing.
FAQs
What is the difference between conflict serializability and view serializability?
Conflict serializability focuses on swapping non-conflicting operations. View serializability checks the final output against a serial schedule.
Why is view serializability important?
It ensures consistency even when transactions overlap, which conflict serializability can miss.
How can we determine if a schedule is view serializable?
Check the initial read, updated read, and final write conditions. Use precedence and dependency graphs.
What are blind writes, and why do they matter?
Blind writes occur when a transaction writes without reading first. They can complicate the process of checking view serializability.
Can a schedule be view serializable but not conflict serializable?
Yes, if it meets the view equivalence conditions but has cycles in the precedence graph.