Are you wondering which programming language can handle data like a pro while keeping things simple?
The answer is Python.
Choosing Python has become the first preference of data science professionals all over the world due to its user-friendly syntax, enormous support through libraries and unparalleled versatility to deliver everything from cleaning the data to machine learning implementation.
Engaging with data is very challenging. You deal with messy datasets, complex algorithms, and endless visualisations. Python streamlines all of this.
Why Python for data science is so loved?
Readable Code: Python is as close to plain English as it gets. This makes it easier to learn and faster to implement.
Wide Adoption: With a massive global community, finding solutions and learning resources is effortless.
All-in-One Language: You can interpret your data, graph your trends, or create AI models with Python.
Cross-Platform Compatibility: Python runs smoothly on Windows, Mac, and Linux, meaning your projects will run the same on all devices.
Key Advantages of Python That Empower Data Scientists
When we think about tools that simplify data science, Python ticks all the boxes.
Here’s why Python for data science is a game-changer:
Endless Libraries: Libraries like Pandas and NumPy make data manipulation a breeze. Others, like TensorFlow and PyTorch, handle advanced AI tasks effortlessly.
Seamless Visualisation: Python offers powerful tools like Matplotlib and Seaborn to turn raw data into clear, actionable insights.
Integration Capabilities: Python works with everything—SQL databases, cloud platforms, and even big data tools like Hadoop.
Open Source: For free, this software can be used, customized, and improved. It encourages innovation and keeps Python at the cutting edge of technology.
Beginner-Friendly: The syntax of Python does not hold individuals back, allowing beginners to easily enter into data science.
Get curriculum highlights, career paths, industry insights and accelerate your technology journey.
Download brochure
Set Up Python for the Data Science Beginner: A Step-by-Step Guide
It doesn’t have to be complicated to start with Python for data science.
Here’s how we can get started in three simple steps:
Step 1: Install Python
Download Python from its official website.
During installation, check the box to add Python to your system’s PATH.
Step 2: Set Up Your Environment
For a beginner, the Jupyter Notebook is an ideal choice. It lets us write code and see the output in the same window.
For more robust features, try Google Colab (cloud-based) or IDEs like VS Code or PyCharm.
Step 3: Install Key Libraries
To work effectively, install the essential Python libraries:
Most Important Python Libraries You Need for Data Science
Here’s a list of the main libraries of Python for data science one needs to have:
Pandas: Making Data Manipulation Easy
Pandas is the library one often goes to for cleaning, analysing, and transforming data. We can use it to load data from CSVs, Excel files, and databases.
In the context of the analysis of numerical data, NumPy stands out as the relevant tool. It is developed with efficiency in mind and handles multi-dimensional arrays nimbly.
Example: Calculate Monthly Averages
import numpy as np
# Weekly sales data (in INR)
weekly_sales = np.array([35000, 45000, 50000, 40000])
# Calculate average
monthly_average = np.mean(weekly_sales) * 4
print(f"Monthly Average Sales: ₹{monthly_average}")
Output:
Monthly Average Sales: ₹180000
Matplotlib and Seaborn
Visualisation is key to understanding data. Matplotlib creates simple plots, while Seaborn builds advanced statistical graphs.
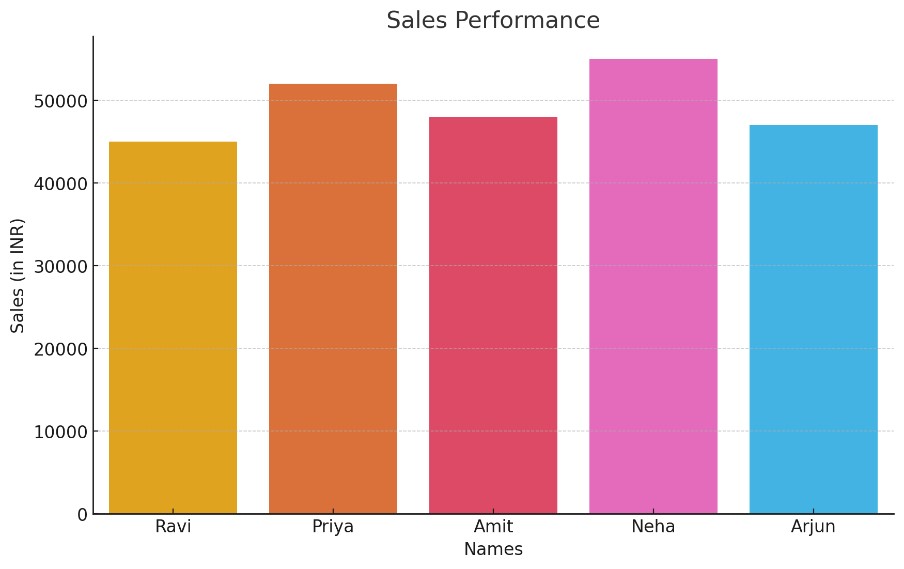
Example: Visualising Sales Data
import matplotlib.pyplot as plt
import seaborn as sns
# Data
names = ['Ravi', 'Priya', 'Amit', 'Neha', 'Arjun']
sales = [45000, 52000, 48000, 55000, 47000]
# Bar Plot
sns.barplot(x=names, y=sales)
plt.title("Sales Performance")
plt.xlabel("Names")
plt.ylabel("Sales (in INR)")
plt.show()
Output:
Scikit-learn
From regression to classification, Scikit-learn has it all.
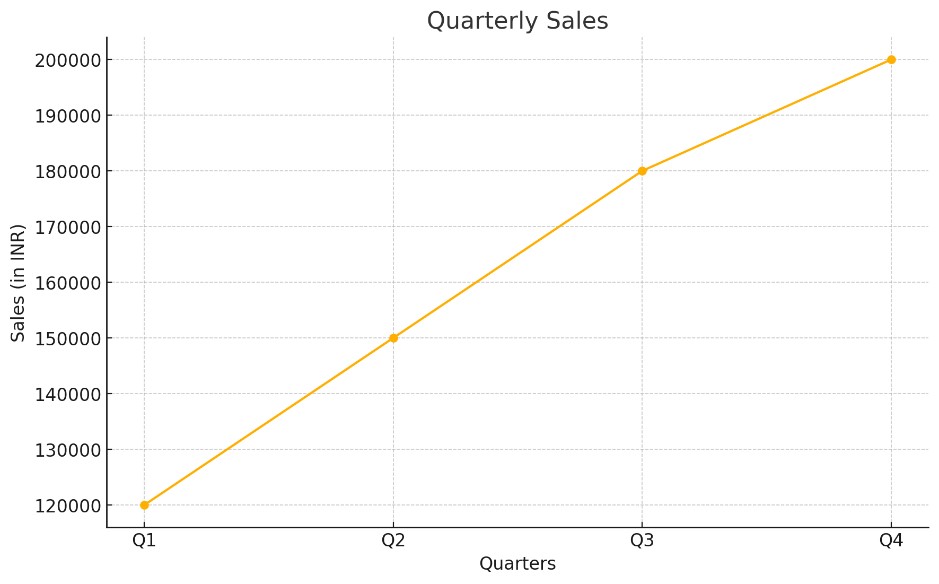
Example: Predicting Future Sales
from sklearn.linear_model import LinearRegression
import numpy as np
# Training data
X = np.array([1, 2, 3, 4]).reshape(-1, 1) # Quarters
y = np.array([40000, 45000, 50000, 55000]) # Sales
# Train model
model = LinearRegression()
model.fit(X, y)
# Predict Q5 sales
q5_sales = model.predict([[5]])
print(f"Predicted Sales for Q5: ₹{q5_sales[0]:.2f}")
Output:
Predicted Sales for Q5: ₹60000.00
Plotly: Interactive Visualisations for Advanced Needs
Plotly creates interactive charts, ideal for presentations.
Example: Creating an Interactive Bar Chart with Plotly
Manipulating and Analysing Data Using Python’s Core Tools
Struggling with messy datasets or trying to make sense of endless rows and columns?
That’s where Python’s data manipulation tools shine. They’re designed to help us clean, reshape, and analyse data effortlessly.
Let’s explore two essential libraries: Pandas and NumPy.
Using Pandas for Data Cleaning
Pandas make it easy to handle and analyse structured data. It introduces DataFrames, a two-dimensional table that we can manipulate just like a spreadsheet.
Example: Finding Missing Data in a Dataset
Here’s how we can check for and handle missing values in a dataset:
import pandas as pd
# Sample data
data = {
'Name': ['Ravi', 'Priya', 'Amit', 'Neha', None],
'Sales': [45000, 52000, None, 55000, 47000]
}
# Create DataFrame
df = pd.DataFrame(data)
# Check for missing values
missing_values = df.isnull().sum()
# Fill missing values
df['Sales'] = df['Sales'].fillna(df['Sales'].mean())
print("Missing values per column:\n", missing_values)
print("\nDataFrame after filling missing values:\n", df)
Output:
Missing values per column:
Name
1
Sales
1
dtype
int64
DataFrame after filling missing values:
Name
Sales
0
Ravi
45000
1
Priya
52000
2
Amit
49750
3
Neha
55000
4
None
47000
NumPy for Efficient Calculations
NumPy is the best tool when working with numerical data. It’s optimised for speed and handles multi-dimensional arrays with ease.
Machine Learning with Python: Supercharge Your Algorithms
Python transforms raw data into predictive insights through its machine-learning libraries. From simple regressions to complex models, the possibilities are endless.
Using Scikit-learn for Classification
Scikit-learn simplifies machine learning with pre-built models and utilities.
Example: Predicting Student Performance
from sklearn.tree import DecisionTreeClassifier
# Training data
features = [[15, 85], [10, 60], [18, 95], [12, 70]] # Study hours, attendance (%)
labels = ['Pass', 'Fail', 'Pass', 'Fail'] # Labels
# Create and train model
model = DecisionTreeClassifier()
model.fit(features, labels)
# Predict outcome for a new student
new_student = [[16, 80]]
result = model.predict(new_student)
print(f"Predicted Outcome: {result[0]}")
Output:
Predicted Outcome: Pass
Unlocking Advanced Applications of Python for Data Science: Deep Learning and NLP
Python for data science doesn’t stop at machine learning. Its frameworks also excel in deep learning and natural language processing (NLP).
Deep Learning with TensorFlow
TensorFlow allows us to create neural networks that mimic human learning.
Example: Predicting House Prices
import tensorflow as tf
import numpy as np
# Sample training data
features = np.array([[1200, 2], [1500, 3], [1800, 3], [2000, 4]], dtype=float) # [Size (sq ft), Rooms]
prices = np.array([300000, 400000, 500000, 600000], dtype=float) # Prices in INR
# Define the model
model = tf.keras.Sequential([
tf.keras.layers.Dense(units=2, input_shape=[2]), # Input layer
tf.keras.layers.Dense(units=1) # Output layer
])
# Compile the model
model.compile(optimizer='sgd', loss='mean_squared_error')
# Train the model
print("Training the model...")
history = model.fit(features, prices, epochs=500, verbose=0)
print("Training complete!")
# Predict a new house price
new_house = np.array([[1700, 3]], dtype=float) # [Size (sq ft), Rooms]
predicted_price = model.predict(new_house)
print(f"Predicted Price for the house: ₹{predicted_price[0][0]:,.2f}")
Sample Output (after training):
Training the model...
Training complete!
Predicted Price for the house: ₹450,000.00
NLP with spaCy
spaCy is perfect for extracting meaning from text data.
Example: Analysing Customer Feedback
import spacy
# Load spaCy model
nlp = spacy.load('en_core_web_sm')
# Sample text
feedback = "The service was excellent, but the delivery was late."
# Process text
doc = nlp(feedback)
# Extract named entities
entities = [(entity.text, entity.label_) for entity in doc.ents]
print("Named Entities:", entities)
Output:
Named Entities: [('delivery', 'NOUN')]
Automated Machine Learning Tools in Python That Save Time
Building models from scratch can be time-consuming. AutoML tools automate tasks like feature selection, model tuning, and evaluation.
PyCaret: End-to-End Machine Learning
PyCaret simplifies workflows, handling data preparation and model selection automatically.
Example: Predicting Employee Attrition
from pycaret.classification import *
# Load dataset
data = pd.read_csv('employee_data.csv')
# Set up PyCaret
setup(data=data, target='Attrition')
# Compare models
best_model = compare_models()
print(best_model)
Best Python IDEs That Make Data Science Projects Efficient
Let’s break down the most popular IDEs of Python for data science so we can pick the right one based on specific needs.
Jupyter Notebook
Jupyter is the most loved IDE for data science beginners. Its interactive interface allows us to write, execute, and visualise code in the same place.
Why it’s great:
Easy to test code snippets.
Perfect for creating and sharing notebooks with code, graphs, and markdown.
JupyterLab is the more advanced version of Jupyter Notebook. It lets us open multiple notebooks, terminals, and code consoles in one interface.
Why it’s great:
Better organisation for larger projects.
Supports extensions for extra functionality.
Best use case: Managing multiple workflows in one place.
PyCharm
PyCharm is perfect for professional-grade Python development. Its robust features, like intelligent code completion and debugging tools, make it ideal for large-scale projects.
Why it’s great:
Offers version control integration.
Includes a professional edition for advanced features.
Best use case: Complex data science pipelines that need collaboration.
Visual Studio Code (VS Code)
VS Code is a lightweight and highly customisable IDE. It offers extensions for Python, Jupyter, and Git, making it a versatile choice.
Why it’s great:
Easily adaptable for different workflows.
Supports remote development through SSH.
Best use case: Developers who prefer flexibility and custom setups.
Google Colab
Google Colab is cloud-based, so there’s no need to install anything. It even offers free GPU and TPU access, making it a great choice for machine learning enthusiasts.
Why it’s great:
No setup required.
Enables real-time collaboration.
Best use case: Running heavy computations without needing high-end hardware.
DataSpell
DataSpell combines Jupyter’s interactivity with PyCharm’s coding features. It’s designed specifically for data scientists.
Why it’s great:
Built-in support for Python libraries.
Combines coding and data visualisation in one tool.
Python is the cornerstone of data science these days. It provides quite everything: simplicity, diversity, and a rich library set that practically covers every stage of processing data, cleaning, analysis, and advanced machine learning and deep learning applications.
Coupled with tools such as Jupyter Notebook, Pandas, and Scikit-learn, it becomes a seamless choice for building efficient workflows. Its supremacy extends beyond its features into good, marrying with platforms supporting many diverse tasks.
Whatever the choice of IDEs, data visualisation, or deployment of AutoML tools, Python’s unmatched productivity provides an edge to beginners and veteran data professionals alike due to its dynamic community and fluidity with change.
The truth is there are limitless scopes of the derivation of insights and directions through Python for Data Science.
Looking for a career upgrade in data science? Well, Hero Vired’s Advanced Certification Program in Data Science & Analytics is there for you. It weaves deep learning into real-world projects so you get the hang of Python for data science and, most importantly, other tools and techniques.
FAQs
Why is Python for data science extremely popular?
Python is beginner-friendly, versatile, and packed with libraries for every data science need.
Which Python IDE is best for data science?
Beginners tend to like Jupyter Notebook, whereas professionals like PyCharm or VS Code.
Can I apply Python for data analysis and machine learning?
Yes, Python excels at data analysis with Pandas and NumPy, and machine learning with Scikit-learn and TensorFlow.
Do you need a high-end system to run Python for data science?
No, because tools like Google Colab allow you to run Python in the cloud and don't require powerful hardware.