
Sequence of operations from one transaction to the next is referred to as a schedule. Scheduling is an act of queuing up transactions and then proceeding to execute them one by one. In case there are numerous transactions operating at the same time and the operation order must be decided so that the operations do not interfere with each other, scheduling has been done and the transactions are now timed in such a way. In this blog, we’ll discuss many types of scheduling.
Scheduling as a process
Scheduling is the process of keeping the sequence of events consistent between concurrent transactions while they are being carried out. A schedule is a sequence of operations from one transaction to another transaction.
Transactions are a sequence of commands that work on databases. If there are multiple transactions running at the same time, we need a sequence of how the operations have to operate on the Database since at any time the operation for the database can only be done by one operation. The process of Scheduling is that, the sequence of these operations is just Scheduling, and this Series of operations is known as Schedule. Undefined arrangement of multiple transactions may cause many problems, which we call concurrency problems. These problems have to be solved using the scheduling through which we can overcome them.

POSTGRADUATE PROGRAM IN
Multi Cloud Architecture & DevOps
Master cloud architecture, DevOps practices, and automation to build scalable, resilient systems.
Types of Scheduling processes
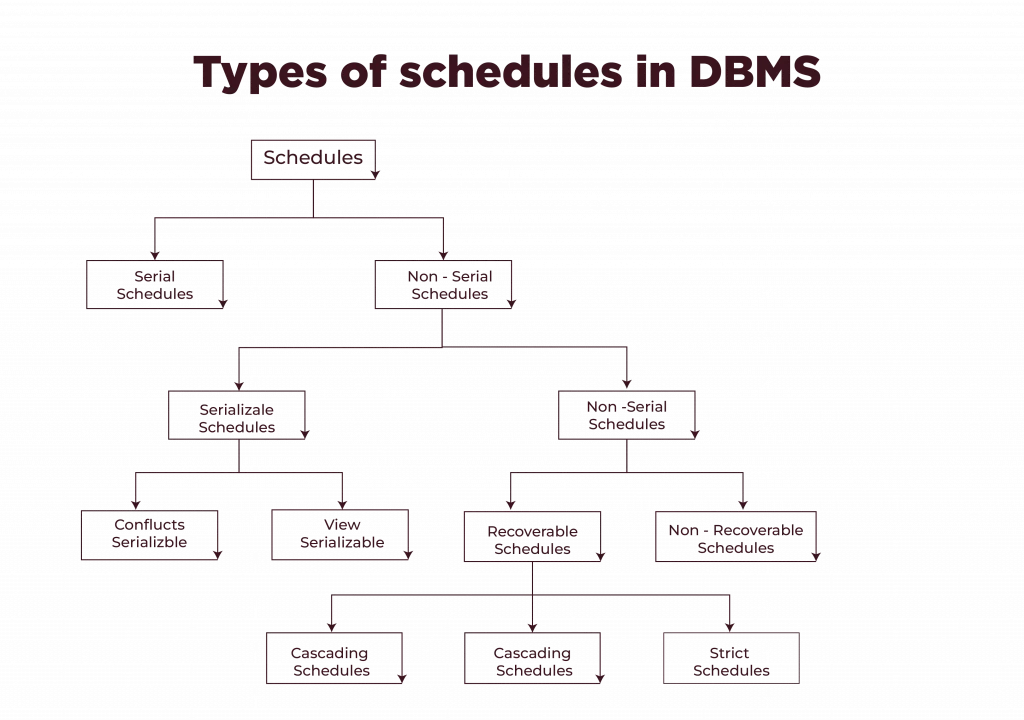
There are mainly two types of scheduling process and their further sub-types:
- Serial Schedule
- Non-serial Schedule
- Serializable
- Conflict Serializable
- View Serializable
- Non-Serializable
- Recoverable Schedule
- Cascading Schedule
- Cascadeless Schedule
- Strict Schedule
- Non-Recoverable Schedule
- Recoverable Schedule
- Serializable
Further, they are divided into their subcategories, as shown below.
Serial Schedules
A serial schedule is a schedule in which the individual executions of the transactions are executed non-interleaved, that is where no transaction starts until a running transaction has terminated. In such a Serial Schedule we have two Transactions, T1 and T2. T2 begins its operation on variable Z before T1 finishes executing a series of operations completely to read and write data for its variables X and Y. This will ensure that T1 doesn’t mess up T2 and that one action is not executed before another.
Non-Serial Schedules
Scheduling is a kind of Scheduling where the operations of multiple transactions are interleaved. Such a rise may then cause an increase of the concurrency problem. The transactions are performed in a non-serial way, preserving correctness and final result and matching with serial schedule. While in the serial schedule, one transaction must wait for the other transaction to finish its operation completely, in the non serial schedule the other transaction runs away without waiting for the other transaction to complete.
Such a schedule gives no advantage to concurrent transactions. In contrast to a Non serial Schedule, T1 and T2 are running simultaneously. Let me assume T1 could read and write variable X, and T2 could read from Y and write to Z. From a T, we have T1 and T2 interleaving their operations, in fact allowing parallel transactions to execute concurrently, raising datathons balance data consistency problems.
There are two types of schedules, one that is Serializable and one that is not Serializable. A further division is made between the Non-Serial Schedule and two types:
Serializable
It does so to keep the database in an inconsistent state. The way it is used mainly is to check if the scheduling would cause any inconsistency. However, in the case of serial schedule, it doesn’t require serializability since a transaction proceeds only when its previous transaction is over. The serial schedule consists of all serial schedules or the non-serial schedules are in a serializable schedule as only the non serial schedules are equivalent to the serial schedules for n number of transactions. With concurrency allowed in this case therefore, multiple transactions can run concurrently. It improves both CPU throughput and resource utilization by means of a serializable schedule. The conditions for having a Serializable Schedule are that the operations are interleaved but produce the same final outcome as the serial execution of the schedule. For instance, suppose that T1 reads and writes to P, and that T2 does the same with Q, reading P afterwards, and the effect is the same as if T2 were to run afterwards than T1, i.e., T2 runs after T1, maintaining consistency.
Also read: Recoverability in DBMS
These are of two types:
Conflict Serializable
A schedule is conflict Serializable if it can be transformed into a Serial Schedule by swapping non Conflict operations. Transactions are reordered in Conflict Serializable schedules. One example (among others) is when T1 reads and writes to variable M, and T2 also reads and writes to M, we can rearrange non conflicting operations such that the entire schedule can be transformed into a serial one without altering the end result. Two operations are said to be conflicting if all conditions satisfy:
- Transactions will be completely different.
- They work on the same data item.
- One of them is a write operation at least.
View Serializable
A Schedule is said to be viewed as serializable if it is viewed equal to a serial schedule (no overlapping transactions). A view serializable view serializable does not conflict serializable conflict serialize if the serializability contains blind writes and a conflict schedule is a serializable. A View Serializable schedule guarantees that if the operations are interleaved, we still have a valid result. For example if T1 reads A and writes B, and then T2 writes A and reads B the outcome stays the same as if T1 carried out the whole transaction before T2 keeping the integrity of the transactions.
Non-Serializable
In a Non-Serializable Schedule T1 may now write to A while T2 reads A and also writes to B. This is a situation which could produce inconsistencies because T2 relies on uncommitted data in T1, which are potentially erroneous outcomes. Recoverable and Non recoverable schedule is chosen by the non serializable schedule.
Recoverable Schedule
And schedules in which transactions can commit only after all transactions whose changes they read have committed are called recoverable schedules. In a Recoverable Schedule, T1 reads and writes to A and T2 does the same, but commits afterward. T2 can only commit if T1 has already done so, hence here. This guarantees that if T1 were to fail, or to even abort T2 will effectively roll back its own changes to ensure data consistency.
There can be three types of recoverable schedule:
Cascading Schedule
Also known as Avoids cascading aborts/rollbacks (ACA). If the failure of one of the transactions causes the rollback or aborting of another dependent transaction, we call such scheduling Cascading rollback or cascading abort. In case of a Cascading Schedule one transaction’s outcome affects another. For instance, if T1 commits it may write to A and T2 would read A and write A again. T3 may read A may need to abort if it reads A and perhaps other transactions, might need to roll back their changes, with the effect cascading across multiple transactions.
Cascadeless Schedule
Cascadeless schedules are schedules in which transactions read values after all transactions whose changes they read commit. It avoids the consequence of a single transaction abort causing some or all a series of transaction rollbacks. To prevent cascading aborts is to prevent a transaction to read the uncommitted changes from another transaction in the same schedule. For a Cascadeless Schedule, T1 reads and writes to A, commits, before T2 reads and writes to A. This structure prevents any cascading rollbacks because T2 only reads committed data in T1, so that if T1 should fail then T2 can continue without interruption.
Strict Schedule
A strict schedule ensures that if a transaction writes a value, other transactions can only read or write that value after the first transaction has committed or aborted. This prevents conflicts between overlapping transactions. With a Strict Schedule, you make sure no data can be read or written until another transaction has completed. The first example is T1 writes to A and commits before T2 reads from and writes to A. It ensures that T2 only deals with finalized data, and that data integrity is maintained.
Non-Recoverable Schedule
A schedule is referred to as non-recoverable if a transaction reads the value of an operation from an uncommitted transaction and commits before the transaction from which it reads the value. In the event of a system failure, we might not be able to restore the database to a consistent state if the schedule is non-recoverable. In a Non-Recoverable Schedule, we can finally clock T1 to write A and T2 can read from and commit to A. T2 has left in an unrecoverable state because it relied on uncommitted data from T1. It illustrates the risks in poor scheduling in transactions.
Conclusion
Schedules are used in DBMSs, to manage the ordering of operations among transactions so as to ensure consistency. Non serial schedules allow concurrent execution and serial schedules execute transactions one by one. Conflict serializability provides that a schedule can be reorders to a serial schedule without conflicts and view serializability that a schedule is equivalent to a serial schedule. This has proven to be very important for ensuring transaction correctness in concurrent systems and both are necessary.
What’s the reason we need schedules in DBMS?
What is the concurrent schedule in DBMS?
When can a schedule be considered serial?
What are the merits and demerits of scheduling?
Updated on October 9, 2024