
DBMS is the key to proper management of large amounts of data in an organised way. As the database size increases, the time taken to retrieve data becomes critical. This is where indexing is important. Indexing in DBMS is a powerful method used for optimization in record retrieval from a database, drastically decreasing the time needed for search operations.
In this article, we will cover what is indexing in DBMS and its various types, mechanisms, benefits, and challenges so that you can have a good understanding of how indexing improves database performance.
What is an Index?
An index is a data structure that facilitates fast access to particular rows of data in a table, optimising database query performance. Using indexes, data in a database may be easily found and accessed without needing to be searched through each row of a table each time a database query is executed. The working of an index is also simple. It works by copying the data in a particular order, which facilitates finding particular data rows.

POSTGRADUATE PROGRAM IN
Multi Cloud Architecture & DevOps
Master cloud architecture, DevOps practices, and automation to build scalable, resilient systems.
What is Indexing?
Indexing in general refers to the process of optimising the performance of the database queries. It is a fundamental concept where the user can retrieve any data faster compared to any other method. Formally, indexing is a DBMS approach that optimises a database query’s searching time by utilising data structures like index. Indexing creates an index table internally, hence reducing the number of disks needed to retrieve a certain piece of data.
For instance, a database index greatly enhances query efficiency by enabling the DBMS to find data without having to search through the entire table, much like an index in a book. A smaller, independent data structure called an index keeps track of the actual data in a database table.
How do we use Indexing in DBMS?
Indexing can be done by creating a simple Index. It is also known as the Index table. Being a table, it consists of two columns called a key-value pair.
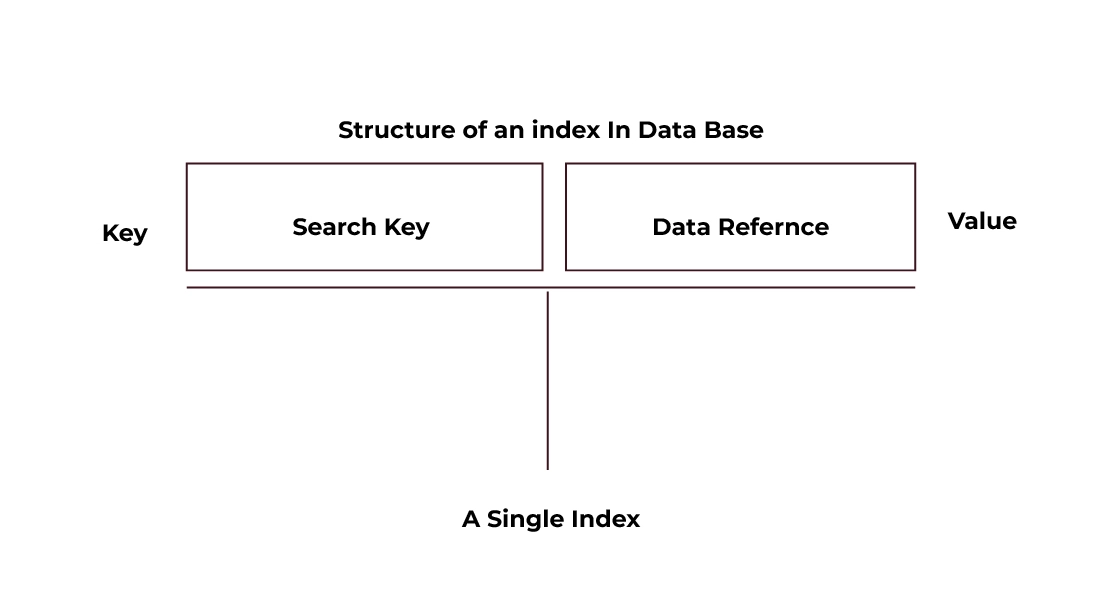
- The search key is the first column in the database that is a duplicate of the relation’s primary or candidate key.
- The data reference appears in the database’s second column. It consists of a collection of pointers that store the location of the disk block containing the value of the specified key.
Why use Indexing?
Now the question comes: why use indexing in DBMS? The answer to this is simple, it makes your query retrieval process much faster, reducing the time & cost, and making the data retrieval process efficient. Without indexes, the database management system would have to go through every table row to locate the information that satisfies the query parameters. When a table has a lot of rows, performance may become slow, especially when dealing with big datasets.
By enabling the database to rapidly locate the precise rows of data sought in a query without having to search the entire table, indexes enhance query performance. Indexes streamline search processes, facilitating quicker and more effective data retrieval – a crucial feature in systems with high read-to-write ratios. We will cover the importance of Indexing in detail later in this article.
Types of Indexes
Indexes in DBMS are categorised mainly into three types i.e., Primary index (Clustered Indexing), Secondary index (Non-clustered Indexing), and Multilevel index. Selecting the appropriate indexing approach for a given use case is made easier by having a thorough understanding of the various index types. We will cover these in detail with examples.
Primary Index (Clustered Index)
Primary index refers to the index created using the primary key of the relational table. Primary indexing is a type of clustered indexing that contains the sorted data and a primary key. The primary index offers immediate access to records because each record is uniquely identified by its primary key. Due to this, the search operation performance increases.
The primary index is typically a clustered index, which means that the index entries and the physical order of the data in the table match.
Features:
- The table’s entries can only be kept in a single order, each table can only have one clustered index.
- Since the data is stored in the index’s order, searching, retrieving, and sorting it can be done more quickly.
For example, if an employee database contains a clustered index on a column called EmpID, the table’s rows will be arranged according to EmpID in ascending order.
Primary index is categorised into two types i.e., Sparse Index and Dense Index.
- Dense Index
Every record in the database table has an index entry in a dense index. This indicates that every unique value has an index entry that corresponds to it and points straight to the relevant disk record. Similar to primary indexing, however, each search key has its own record. Denser indexes take up more storage space but are more effective for lookups.
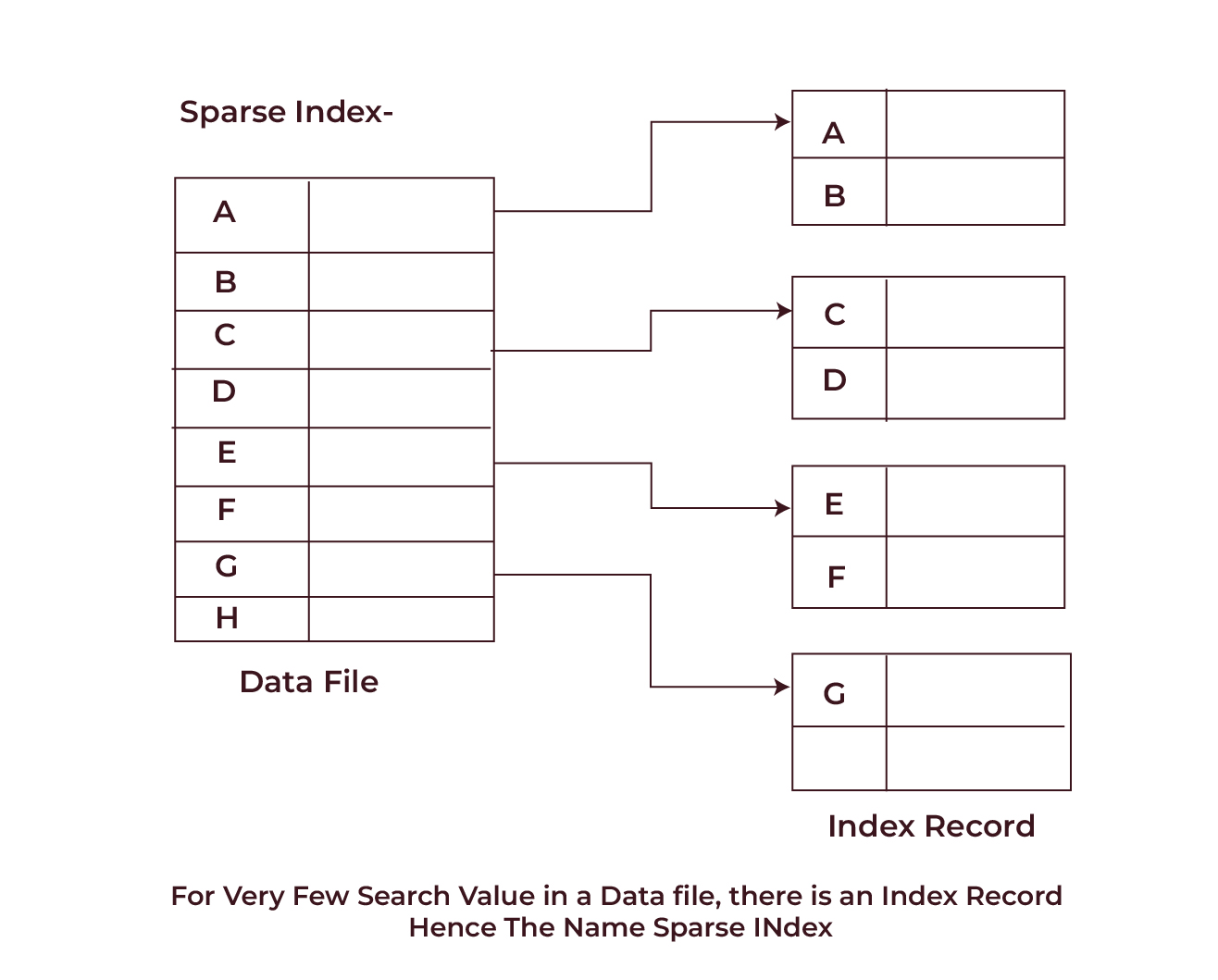
- Sparse Index
Sparse indexing offers a more optimal approach as it creates index entries only for some of the records. Although we save a search key that leads to a block, we do not include a search key for each entry in a sparse index. A set of data is also contained in the pointed block.
When using sparse indexing, the size of the mapping increases along with the table’s growth. Typically, these mappings are stored in the main memory to facilitate faster address fetches. Having the advantage of sparse indexes using less space, it could take more lookups to locate the requested record.
Secondary Index (Non-clustered Index)
The Secondary index is built using a non-primary key attribute. By offering a different way to access information, secondary indexes facilitate data retrieval based on non-primary key columns. Secondary indexes are usually non-clustered, in contrast to primary indexes.
We have seen in the sparse index which is a type of primary index, the size of the mapping increases as the table grows. These mappings are stored in the primary memory which makes the address fetching faster but searching for actual data through these addresses by the secondary memory makes it slower. Therefore it becomes an inefficient approach.
The Secondary Index is a more efficient approach than the primary index. This is because it creates a different level of columns to reduce the size of mappings and increase the search process faster. Compared to the clustered index, it takes longer since more work needs to be done to extract the data by following the pointer further. When an index is clustered, the data is in front of the index itself.
Features:
- A table may have several non-clustered indexes, which increases query flexibility.
- A copy of the indexed columns and references to the real data rows are present in non-clustered indexes.
For example, a table having a FName column in your database has a non-clustered index, you may easily search for records using just the first name in the index structure without changing the row order of the table.
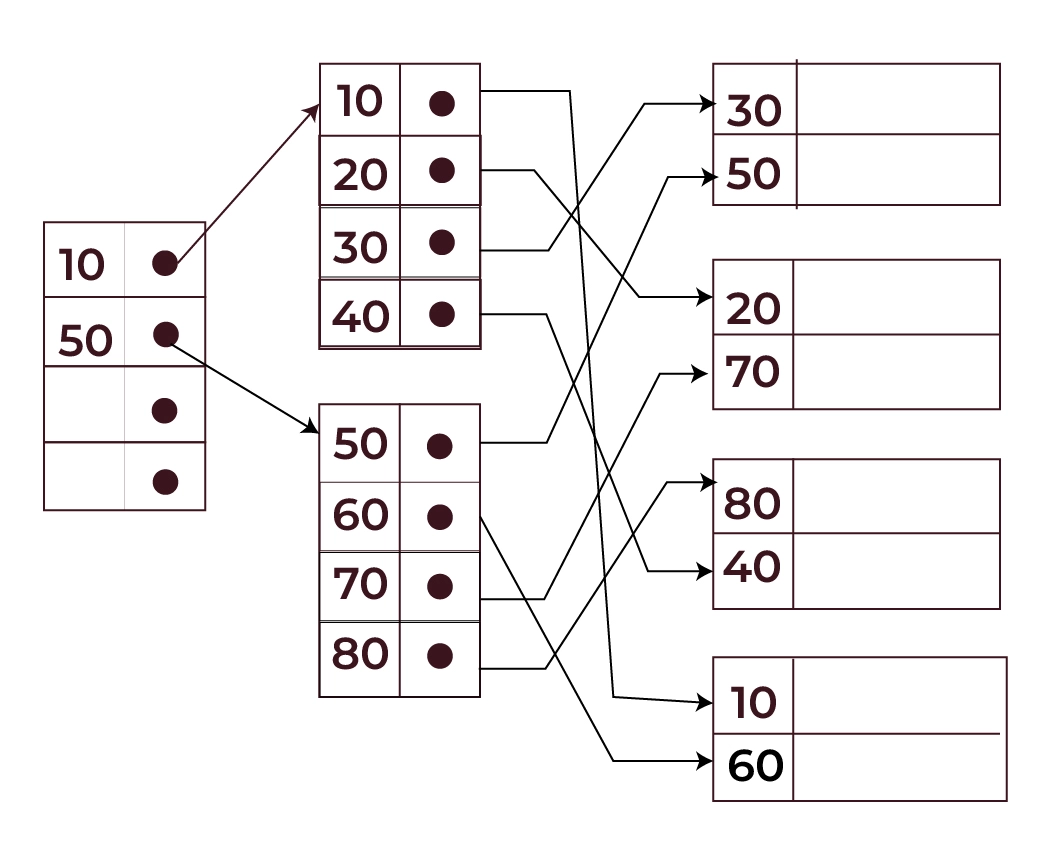
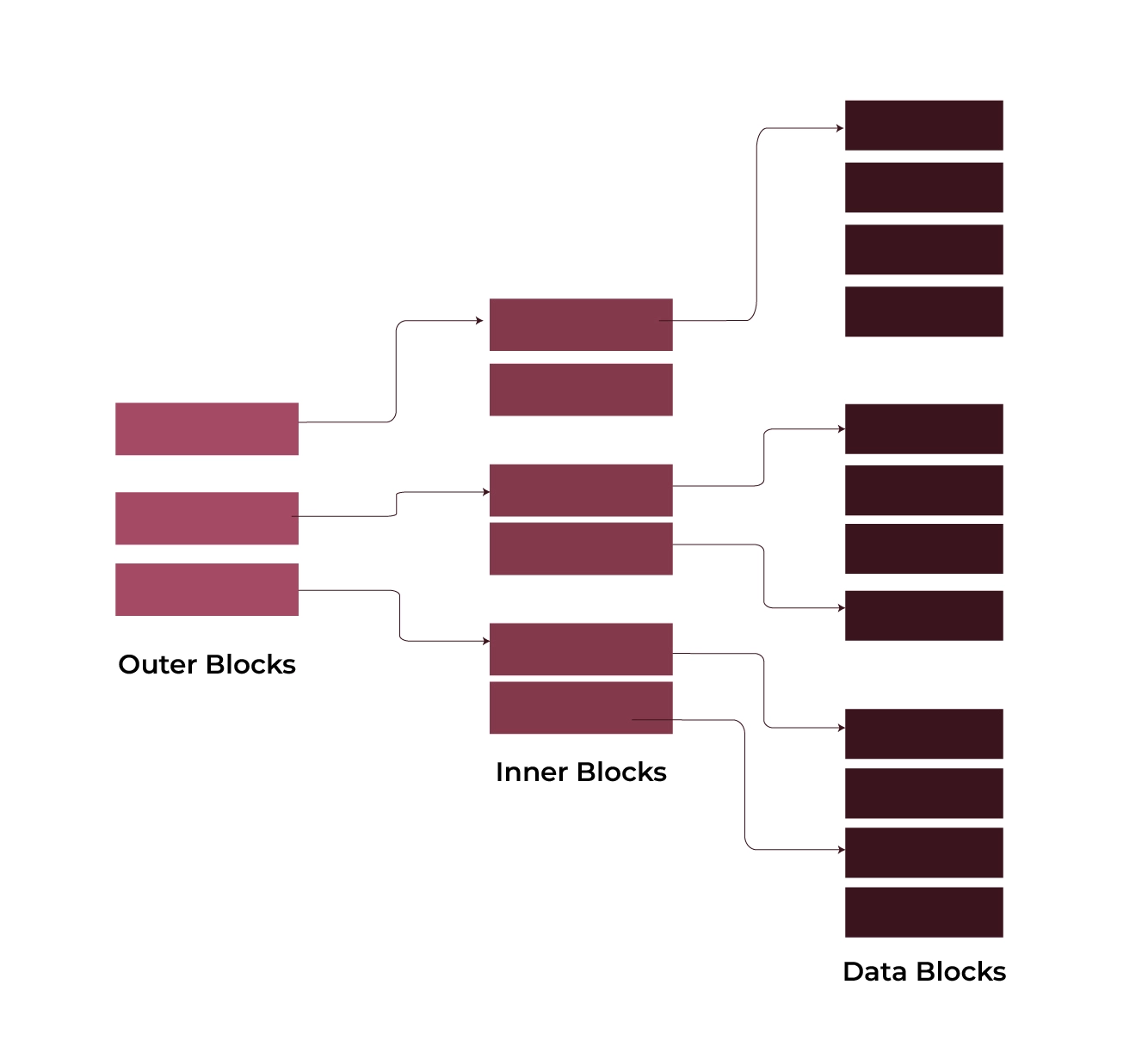
Multilevel Index
Multi-level indexing makes it possible to manage big indexes more effectively. In this index type, it involves breaking up the primary data block into smaller blocks. As a result, the index table’s outer block is now short enough to fit in the main memory.
Features:
- It has several tiers of indexes, with the first tier pointing to the second, and so on, until it reaches the real data.
- By using this method, fewer disk requests are needed to locate a specific record.
For example, consider a B+ tree where the leaf nodes holding pointers to the real data are reached through intermediate nodes that are pointed to by the top-level nodes.

82.9%
of professionals don't believe their degree can help them get ahead at work.
Indexing Mechanisms
Now that we have understood the different types of Indexes, let’s see how we create and manage them in DBMS. In DBMS, many indexing mechanisms are utilised for index creation and management. The type of data, query patterns, and database system being utilised are some of the elements that influence the mechanism chosen.
Below are some of the indexing mechanisms in DBMS:
B-Trees Indexes
One of the most commonly used indexing mechanisms in DBMS is B-Tree indexes. A B-Tree is a self-balancing tree data structure maintaining sorted data that supports efficient insertion, deletion, and search operations. In a B-Tree, each node holds more than one key, and the tree is kept balanced for its depth to be minimised.
B+ Trees Indexes
B+ Tree indexes are widely used in database systems as an extension of B-Trees. In a B+ Tree, all the data pointers are stored in the leaf nodes; internal nodes only store keys and pointers to other nodes. This feature enables B+ Trees to deal with both point queries (searching for a specific value) and range queries very efficiently.
B+ trees are used as a part of Multi-level indexing. Also, because B+ Trees allow access to data sequentially, they are good for queries on ordered data retrieval.
Hash Indexes
Hash indexes employ a hash function in mapping search keys to particular locations within the index. The efficiency of hash indexes is very high for equality searches (for example, finding a record with a specific key) because they provide constant-time access to the data.
They are not so good for range queries because, generally, hash functions do not preserve order. Therefore, wherever there is a requirement for ordering or sorting, they are typically not recommended. Typically, hash indexes are found in environments where speed is of the essence and equality search is their main type of query.
Bitmap Indexes
Bitmap indexes represent the values of presence or absence in a table by using bitmaps. A bitmap is taken for every distinct value in the indexed column, with each bit relating to a row in the table. Bitmap permits faster data retrieval of certain data, hence they are used over B-trees.
Queries that include filter conditions on multiple columns with low cardinality are very efficient using bitmap indexes. They have good query performance in a scenario where the database is read-heavy because frequent updates make them less efficient.
Full-Text Indexes
Full-text indexes are designed to handle full-fledged text search queries. They permit rapid search on extended textual fields such as whole documents or web pages. Search features supported by full-text indexes include proximity of words, phrase search, and even relevance ranking.
Indexing in Modern Databases
Indexing is not only used in relational databases that have been used for years but is also common in modern databases including No-SQL and NewSQL databases. Let’s see how indexing helps in performance or query optimization in modern databases.
Indexing in Relational Databases
Relational databases are the traditional databases in which indexing is more commonly used. Some of the most often used indexes in relational databases are B-Tree and B+ Tree. Primary, secondary, clustered, and non-clustered indexes are among the many indexing options offered by relational databases such as PostgreSQL, Oracle, and MySQL. The query patterns and the application’s particular requirements will determine which index is best. Indexing is used to optimise the overall performance of the database and increase query optimization.
Indexing in NoSQL Databases
Indexing in NoSQL databases is also used for better query optimization. Databases like MongoDB, Cassandra, etc., often use the indexing.
- MongoDB uses B-Tree-based indexes to ensure that queries are efficiently executed, with support for compound, geospatial, and text indexes.
- Cassandra uses its partition key and clustering key for indexing, thus being able to retrieve data quickly across distributed environments.
- Redis uses in-memory data structures to maintain the index, and the retrieval of key-value pairs is very fast.
Indexing in NoSQL databases should be carefully done to cater to the special features of these systems – like eventual consistency, flexible data models, and horizontal scalability, among others.
Indexing in NewSQL Databases
NewSQL databases try to marry the positive aspects of relational and NoSQL databases by providing the scalability and performance available in NoSQL systems while retaining the ACID properties of relational databases. In NewSQL databases such as Google Spanner and CockroachDB, indexing is achieved by combining traditional B-Tree indexing along with distributed indexing techniques, which is also how they do it for large-scale data that is distributed globally.
Indexing and Query Optimization
Indexing is a powerful technique to optimise the queries running in the database. It is important for query optimization because it reduces the number of searches in the database as it only scans those specific data with the help of indexes.
The Role of Query Optimizers
A key component of database management systems (DBMS) is query optimization, which looks at several query execution methodologies to find the most effective way to run a particular query. The DBMS’s query optimizers examine SQL queries to ascertain the most effective way to execute them.
It is the optimizer that all SQL statements employ. To create the best query plan, the optimizer takes into account several variables, including the distribution of data, the query’s structure, and the indexes that are currently accessible. Because they make it possible for the optimizer to find pertinent information fast and reduce the need for full table scans, indexes are essential to query optimization.
Using Indexes in Query Plans
A series of actions used to access data in a SQL relational database management system is called a query plan, also known as a query execution plan. This is a particular instance of the access plans idea seen in relational models. For instance, the query optimizer may decide to use an index to obtain the relevant records when one exists for a column that is used in a query condition.
This is especially helpful for queries involving sorting, filtering, or merging large datasets. Composite indexes are another option available to the optimizer for queries with numerous columns in the WHERE clause. The purpose of the query optimizer’s generation of query plans is to produce the most effective and affordable query plan feasible.
Index/Query Hints in SQL
Sometimes, especially in complicated settings with numerous indexes, the query optimizer might not select the best index for a query. To address this, SQL gives developers the option to designate the index to use for a given query by using index hints or query hints.
Query hints indicate that the given hints are to be used inside the parameters of a query. Every operator in the sentence is impacted by them. When optimising query performance, index suggestions might be helpful, especially if the optimizer’s default selection is not the best one.
Importance of Indexing
1. Faster and Efficient Data Retrieval
With the help of the indexing technique, the database queries are performed very quickly to find any type of data just using an index. Having an index significantly reduces the time to execute the DB queries. Apart from this, the indexes also optimise the search for specific records in the relation. This efficient approach in optimising the search is very useful in large databases where searching the whole DB is impractical.
2. Efficient Sorting
Data may be effectively sorted using indexes, negating the need for additional sorting steps. This is particularly useful for clauses like ORDER BY where DBMS may directly obtain data from the index in the desired order, and GROUP BY where it enables the DBMS to swiftly access and group data based on indexed columns using SQL.
3. Efficient Data Access
Indexing can improve the efficiency of data access by reducing the quantity of disk input/output needed to obtain data. Effective range searches, such as those that locate entries within a specific value range, are made possible by indexes. Applications that often query data inside defined ranges – like dates or numerical values – should pay special attention to this.
4. Uniqueness and constraints support
Indexes use constraints like PRIMARY KEY and UNIQUE to ensure that each value in the indexed column is unique, maintaining the data integrity and no data inconsistencies.
5. Optimised Joins
Join procedures between tables are sped up by indexes. The DBMS can find and match data more quickly when combining two tables by using indexes on the join columns, which saves time and resources. If indexes are used without having JOINS, it may increase the cost and require a lot of memory and computing resources. By reducing the size of the data set before the join, indexes help to reduce these expenses.
6. Reduced I/O operations
We know that Indexes limit disk input/output processes, which are frequently a significant source of database performance bottlenecks, by reducing the requirement for complete table scans. Indexes save system resources by only requesting access to the data that is required.
7. Scalability
Scaling is a part of the best system design for every architecture. Therefore, Indexes are essential for scaling databases to handle large volumes of data. As the size of a database grows, indexes become increasingly important for maintaining query performance and ensuring that the database can handle the load.
8. Consistent Performance
Even as the volume of data in the database increases (which is when the system is scaled), indexing can help guarantee that the database operates consistently. When a table’s number of rows increases, queries could take longer to execute without indexing, but indexing keeps query execution times relatively constant due to its mechanism of searching through indexes.
Challenges and Limitations of Indexing
- Indexing in large databases brings out its unique challenges in storage and maintenance. Large indexes can take up a lot of disk space, and their maintenance might bring about overhead during data modifications.
- In distributed database systems, consistency and coordination of indexes running across several nodes can be quite demanding. In real-time, therefore, distributed systems have to guarantee that changes in data come about with the corresponding modification on indexes which makes the whole issue a bit latent and complicated. Distributed indexing, together with eventual consistency, should be handled with care to ensure that indexes do not lose their proper and effective way of representation.
- As data is added, removed, or changed in a table, index maintenance is required, which could increase database maintenance overhead.
- Performance may not be always consistent as the system’s resources may change frequently or even may not be available when indexing is required to perform.
- Since the index data structure needs to be updated whenever data is modified, indexing may result in decreased insert and update performance.
- Efficient indexes are hard to keep in highly dynamic data environments where records are very often inserted, updated, and deleted. The more modifications on the data, the higher the chances of having our indexes fragmented – which will force us to rebuild these indexes as part of their regular maintenance.
Conclusion
In this article, we have learned in-depth about Indexing in DBMS. Indexing ensures effective data retrieval and optimises query performance. Indexing is done using an index table that consists of a search key and a reference pointer. We have learned that indexing is of mainly three types: Primary index (Clustered or single level), secondary index (Non-clustered), and multilevel index. We have also seen the mechanisms for Indexing including B-Trees, B+ Trees, Full-text, Hash, and Bitmap indexes. They all are sometimes called indexing attributes.
Developers and database managers can efficiently use indexing to create high-performance database systems by knowing the various index types, key considerations for index design, and associated trade-offs.
What is Indexing in DBMS?
What is the difference between Primary and Secondary Indexing in DBMS?
What are the types of Indexing in DBMS?
What are the real-world examples of Indexing?
How does Indexing help in Scalability in DBMS?
Updated on October 10, 2024