B+ Tree is one of the most basic structures used in a database management system (DBMS). It assists in the optimal arrangement and administration of colossal data sets. However, one may wonder what a B+ Tree is and why one should bother with it.
A B+ Tree is derived from the B Tree, which is a self-organising search tree. In the B+ Tree structure, all the leaf nodes are at the same level, meaning that search operations are faster, simpler and more predictable. While B Trees have data stored internally as well as in the leaf nodes, B+ Trees allow data storage only in the nodes of the tree. This differentiation makes B+ Trees all the more applicable when it comes to indexing databases since speedy access to data is paramount.
B+ Trees have a long history and were developed over the years as more complicated databases emerged. They are actively used in modern databases, including traditional relational ones and NoSQL systems. Due to their balanced structure and effective data access, these tree structures add efficiency and scalability to databases.
Structural Properties of B+ Trees
A background knowledge of how B+ Tree in DBMS is structured is important in comprehending the functionality of the structures. Now, it is essential to understand the parts of their composition:
Node Types and Their Roles
In a B+ Tree in DBMS, we encounter two types of nodes: internal nodes and leaf nodes.
Internal Nodes: These nodes contain keys and serve as references to obtain exact data values. They also keep track of other nodes of the tree so that the system can navigate it easily.
Leaf Nodes: These are where the raw data on people or events can be found and processed. The nodes at the final level have keys and links to stored records or data.
B+ Trees have been structured to ensure that the roles of managing large amounts of data and the ability to access these data within the shortest time are performed independently.
Linking of Leaf Nodes
The linking of leaf nodes is one special property found in B+ Trees. On the one hand, each leaf node contains a pointer that holds the address of the next leaf node, therefore making it a linked list. This structure permits a range of queries and sequential access to data, which is helpful and quick in accessing records. For example, if we have a requirement to search all records of a specific range, the linked leaf nodes enable us to traverse this tree faster.
Height and Balance
One benefit is that the B+ Tree in DBMS usually has a balanced height. The nodes do not link to another node in the tree, keeping all leaf nodes at the same level and maintaining tree balance as the data is entered or removed. The balance is important in this regard because it maintains the efficiency of the search operations and ensures a steady rate at which the discoveries are made.
For instance, assume a B+ Tree has been employed to index a vast database. The height of the tree does not change while the number of records increases, which means that the tree always maintains a balanced height. This balance translates into search times that are balanced and efficient—something that is desirable when designing high-performance databases.
Get curriculum highlights, career paths, industry insights and accelerate your technology journey.
Download brochure
Reasons B+ Trees are Essential for Databases
What is specifically peculiar about B+ Trees, and why do we use B+ Trees for databases? The answer lies in their capability to balance information storage for optimal data/information access with the utilisation of high performance. Now let’s ponder into details on the reasons.
Efficient Data Storage and Retrieval
B + Trees are exceptional at sorting large data sets. They always use techniques that help organise data so that access to it is fast. Since all data is incorporated in the leaf nodes, and these nodes are interconnected, the process of looking for a record or a particular set of records is the least complex.
Let us suppose that we have to search or retrieve customer profiles or any other records in a database. With the help of a B+ Tree in DBMS, one can easily identify the corresponding number and then find all the interconnected records following the tree structures. This efficiency is even more desirable for heavy-duty applications involving large amounts of data and requiring constant user access.
Cache-Friendliness and Disk Orientation
One of the key facts that must be considered is that B+ Trees are cache-friendly. They use caching techniques as a fundamental aspect to enhance computer performance when accessing data. The structure of B+ Trees is beneficial to keep the data being accessed frequently into the caches and thus want to bring in data from slower media or disk storage from cache or memory.
Also, B+ Trees are disk-oriented; they are used for disks rather than RAM. They are especially important when data must be accessed and stored in the disks within a system that is cheap to build. Due to fan out, each node of a B+ Tree has many children, which helps to minimise the tree’s height. This reduction implies that the disk I/O operations available to Flex-2 are reduced, resulting in faster access and efficient data retrieval.
Detailed Explanation of B+ Tree Operations
Understanding B+ Tree operations is crucial for leveraging their full potential in database management. We will explore how B+ Trees handle searching, inserting, and deleting records. Each operation ensures the tree remains balanced and efficient.
Searching in B+ Trees
Searching in a B+ Tree in DBMS is straightforward and efficient. We start at the root node and navigate through internal nodes until we reach the correct leaf node. Each internal node acts as a guide, helping us find the right path based on the keys it contains.
Start at the Root: Begin the search at the root node.
Navigate Internal Nodes: Follow the pointers in the internal nodes based on the search key.
Reach Leaf Node: Continue this process until arriving at the appropriate leaf node.
Locate Data: Once at the leaf node, locate the specific key and access the data.
Example: Suppose we need to search for a customer record with an ID equal to 105. Initially, start with any node chosen as the root node. If the root node is a leaf node with keys 50, 100, and 150, one has to follow the pointer between 100 and 150. Proceed in this manner to the next internal node and then skip to the next node where the leaf node with the ID 105 is located. It allows for a fast and effective search since the order of the words does not affect the search results.
Inserting Records in B+ Trees
Inserting a record into a B+ Tree in DBMS involves several steps to maintain balance. Let’s break down the process.
Find the Leaf Node: Locate the correct leaf node where the new key belongs.
Insert the Key: If the leaf node has space, insert the new key in order.
Split the Node: If the leaf node is full, split it into two nodes.
Promote the Key: Promote the middle key to the parent node.
Adjust the Tree: If necessary, repeat the splitting and promotion process to maintain balance.
Example: Consider inserting a record with ID 120. Locate the correct leaf node. If it has space, insert the key directly. If the node is full, split it into two nodes and promote the middle key to the parent node. This ensures the tree remains balanced.
Deleting Records from B+ Trees
Deleting a record from a B+ Tree in DBMS is more complex than insertion. The process involves removing the key and ensuring the tree remains balanced.
Locate the Key: Find the leaf node containing the key to be deleted.
Remove the Key: Delete the key from the leaf node.
Rebalance the Tree: If the deletion was imbalanced, proceed to balance the tree again by merging nodes or redistributing keys.
Adjust Pointers: Make sure all the branches are correctly set to align with the tree’s body.
Example: To delete a record with ID 95, first locate the leaf node containing ID 95. Remove the key from the node. If this causes an imbalance, merge the node with its sibling or redistribute keys. Adjust the parent node as necessary to maintain balance.
Differences Between B Trees and B+ Trees
Recognising the distinctions between B and B+ trees enables us to recognise their distinct benefits.
Data Storage
B Trees: Store data in both internal and leaf nodes.
B+ Trees: Store data only in leaf nodes. Internal nodes contain keys and pointers.
Operational Efficiency
B Trees: Searching, inserting, and deleting can be slower due to data in internal nodes.
B+ Trees: These operations are faster because only leaf nodes store data, making traversal quicker.
Structural Differences
B Trees: Lack of linked leaf nodes, making sequential access slower.
B+ Trees: Link leaf nodes, allowing efficient sequential access and range queries.
Practical Applications of B+ Trees in DBMS
B+ Trees are essential in various database management tasks due to their efficiency and structure. Let’s explore their practical applications.
Multilevel Indexing
B+ Trees excel at multilevel indexing, which enhances data retrieval speed and efficiency.
Efficient Data Access: Multilevel indexing allows quick access to large datasets.
Reduced Disk I/O: The structure minimises disk input/output operations, speeding up data retrieval.
Example: In a large e-commerce database, B+ Trees can index product IDs. This allows rapid searches for specific products, improving user experience and reducing server load.
Database Indexing and Range Queries
B+ Trees are ideal for database indexing, especially for range queries.
Indexing: B+ Trees provide efficient indexing for large databases. They maintain a balanced height, ensuring consistent performance.
Range Queries: The linked leaf nodes make range queries efficient. We can traverse linked nodes to gather data within a specific range quickly.
Example: Consider a financial database where we need to retrieve transactions between two dates. B+ Trees enable quick retrieval of all relevant transactions by following the linked leaf nodes, enhancing performance.
Advantages and Disadvantages of Using B+ Trees
The following advantages make B+ Tree in DBMS highly applicable, hence its widespread use in database systems. However, it also has some limitations and drawbacks. Knowledge of these strengths and weaknesses assists us in making wise decisions about deploying B+ Trees.
Advantages of B+ Trees
Balanced Height: In B+ Trees, all the leaf Nodes are at the same level; thus, the File Height of the B+ tree is always equal to the height of the tree. This balance makes it easy to operate the search, insertion, and deletion actions without much difficulty.
Sequential and Direct Access: B+ Trees’ linked leaf nodes allow sequential and direct access to data with any indexes or pointers and can search numbers or characters numerically or alphabetically. This feature is useful where the dimension of the range is applied in the context of search; it is helpful in enabling a quick search of data.
Predictable Performance: B+ Trees provide consistent performance for various operations. This predictability is, however, desirable in applications that demand a reliable response time, mainly due to database indexing and query processing.
Redundant Search Keys: B+ Trees have auxiliary search keys that help increase search speed by storing extra keys in internal nodes. These additional keys help in directing or pointing users towards areas of interest within the shortest time possible.
Efficient Disk Usage: B+ Trees reduce the number of disk I/O operations, which makes efficiency in the utilisation of disks. Designed this way, it can always facilitate direct access to the data, even storing them on disk and having to work with massive data.
Disadvantages of B+ Trees
Complexity: B+ Trees can be challenging to apply because of the balanced tree requirement and the management of the linked-leaf nodes. This complicates the problem and requires proper planning and personnel to understand this field well enough.
Memory Usage: However, this is useful since using B+ Trees can be complicated due to the need to maintain balance and linked leaf nodes. This is not a plus point because it causes increased memory usage, which can be a problem, especially in a memory-limited environment.
Code Implementation Example of B+ Trees
Let’s look at a basic Java implementation of B+ Tree in DBMS:
class BPlusTreeNode {
int[] keys;
BPlusTreeNode[] children;
boolean isLeaf;
int numKeys;
int order;
BPlusTreeNode(int order, boolean isLeaf) {
this.order = order;
this.isLeaf = isLeaf;
this.keys = new int[order - 1];
this.children = new BPlusTreeNode[order];
this.numKeys = 0;
}
}
class BPlusTree {
private BPlusTreeNode root;
private int order;
public BPlusTree(int order) {
this.order = order;
this.root = new BPlusTreeNode(order, true);
}
public void insert(int key) {
BPlusTreeNode root = this.root;
if (root.numKeys == order - 1) {
BPlusTreeNode newRoot = new BPlusTreeNode(order, false);
newRoot.children[0] = root;
splitChild(newRoot, 0, root);
this.root = newRoot;
}
insertNonFull(this.root, key);
}
private void insertNonFull(BPlusTreeNode node, int key) {
int i = node.numKeys - 1;
if (node.isLeaf) {
while (i >= 0 && key < node.keys[i]) { node.keys[i + 1] = node.keys[i]; i--; } node.keys[i + 1] = key; node.numKeys++; } else { while (i >= 0 && key < node.keys[i]) { i--; } i++; if (node.children[i].numKeys == node.order - 1) { splitChild(node, i, node.children[i]); if (key > node.keys[i]) {
i++;
}
}
insertNonFull(node.children[i], key);
}
}
private void splitChild(BPlusTreeNode parent, int index, BPlusTreeNode node) {
int order = node.order;
BPlusTreeNode newNode = new BPlusTreeNode(order, node.isLeaf);
newNode.numKeys = order / 2;
for (int j = 0; j < order / 2; j++) {
newNode.keys[j] = node.keys[j + order / 2];
}
if (!node.isLeaf) {
for (int j = 0; j <= order / 2; j++) { newNode.children[j] = node.children[j + order / 2]; } } node.numKeys = order / 2 - 1; for (int j = parent.numKeys; j >= index + 1; j--) {
parent.children[j + 1] = parent.children[j];
}
parent.children[index + 1] = newNode;
for (int j = parent.numKeys - 1; j >= index; j--) {
parent.keys[j + 1] = parent.keys[j];
}
parent.keys[index] = node.keys[order / 2 - 1];
parent.numKeys++;
}
public void delete(int key) {
delete(this.root, key);
if (this.root.numKeys == 0) {
if (!this.root.isLeaf) {
this.root = this.root.children[0];
} else {
this.root = null;
}
}
}
private void delete(BPlusTreeNode node, int key) {
int index = findKey(node, key);
if (index < node.numKeys && node.keys[index] == key) {
if (node.isLeaf) {
removeFromLeaf(node, index);
} else {
removeFromNonLeaf(node, index);
}
} else {
if (node.isLeaf) {
return;
}
boolean flag = (index == node.numKeys);
if (node.children[index].numKeys < node.order / 2) { fill(node, index); } if (flag && index > node.numKeys) {
delete(node.children[index - 1], key);
} else {
delete(node.children[index], key);
}
}
}
private int findKey(BPlusTreeNode node, int key) {
int idx = 0;
while (idx < node.numKeys && node.keys[idx] < key) {
idx++;
}
return idx;
}
private void removeFromLeaf(BPlusTreeNode node, int index) {
for (int i = index + 1; i < node.numKeys; ++i) { node.keys[i - 1] = node.keys[i]; } node.numKeys--; } private void removeFromNonLeaf(BPlusTreeNode node, int index) { int key = node.keys[index]; if (node.children[index].numKeys >= node.order / 2) {
int pred = getPredecessor(node, index);
node.keys[index] = pred;
delete(node.children[index], pred);
} else if (node.children[index + 1].numKeys >= node.order / 2) {
int succ = getSuccessor(node, index);
node.keys[index] = succ;
delete(node.children[index + 1], succ);
} else {
merge(node, index);
delete(node.children[index], key);
}
}
private int getPredecessor(BPlusTreeNode node, int index) {
BPlusTreeNode current = node.children[index];
while (!current.isLeaf) {
current = current.children[current.numKeys];
}
return current.keys[current.numKeys - 1];
}
private int getSuccessor(BPlusTreeNode node, int index) {
BPlusTreeNode current = node.children[index + 1];
while (!current.isLeaf) {
current = current.children[0];
}
return current.keys[0];
}
private void fill(BPlusTreeNode node, int index) {
if (index != 0 && node.children[index - 1].numKeys >= node.order / 2) {
borrowFromPrev(node, index);
} else if (index != node.numKeys && node.children[index + 1].numKeys >= node.order / 2) {
borrowFromNext(node, index);
} else {
if (index != node.numKeys) {
merge(node, index);
} else {
merge(node, index - 1);
}
}
}
private void borrowFromPrev(BPlusTreeNode node, int index) {
BPlusTreeNode child = node.children[index];
BPlusTreeNode sibling = node.children[index - 1];
for (int i = child.numKeys - 1; i >= 0; --i) {
child.keys[i + 1] = child.keys[i];
}
if (!child.isLeaf) {
for (int i = child.numKeys; i >= 0; --i) {
child.children[i + 1] = child.children[i];
}
}
child.keys[0] = node.keys[index - 1];
if (!node.isLeaf) {
child.children[0] = sibling.children[sibling.numKeys];
}
node.keys[index - 1] = sibling.keys[sibling.numKeys - 1];
child.numKeys += 1;
sibling.numKeys -= 1;
}
private void borrowFromNext(BPlusTreeNode node, int index) {
BPlusTreeNode child = node.children[index];
BPlusTreeNode sibling = node.children[index + 1];
child.keys[child.numKeys] = node.keys[index];
if (!child.isLeaf) {
child.children[child.numKeys + 1] = sibling.children[0];
}
node.keys[index] = sibling.keys[0];
for (int i = 1; i < sibling.numKeys; ++i) {
sibling.keys[i - 1] = sibling.keys[i];
}
if (!sibling.isLeaf) {
for (int i = 1; i <= sibling.numKeys; ++i) {
sibling.children[i - 1] = sibling.children[i];
}
}
child.numKeys += 1;
sibling.numKeys -= 1;
}
private void merge(BPlusTreeNode node, int index) {
BPlusTreeNode child = node.children[index];
BPlusTreeNode sibling = node.children[index + 1];
child.keys[node.order / 2 - 1] = node.keys[index];
for (int i = 0; i < sibling.numKeys; ++i) {
child.keys[i + node.order / 2] = sibling.keys[i];
}
if (!child.isLeaf) {
for (int i = 0; i <= sibling.numKeys; ++i) {
child.children[i + node.order / 2] = sibling.children[i];
}
}
for (int i = index + 1; i < node.numKeys; ++i) {
node.keys[i - 1] = node.keys[i];
node.children[i] = node.children[i + 1];
}
child.numKeys += sibling.numKeys + 1;
node.numKeys--;
}
public void traverse() {
traverse(this.root);
}
private void traverse(BPlusTreeNode node) {
int i;
for (i = 0; i < node.numKeys; i++) {
if (!node.isLeaf) {
traverse(node.children[i]);
}
System.out.print(" " + node.keys[i]);
}
if (!node.isLeaf) {
traverse(node.children[i]);
}
}
}
public class Main {
public static void main(String[] args) {
BPlusTree tree = new BPlusTree(3);
tree.insert(10);
tree.insert(20);
tree.insert(5);
tree.insert(6);
tree.insert(12);
tree.insert(30);
tree.insert(7);
tree.insert(17);
System.out.println("Traversal of the B+ tree is:");
tree.traverse();
tree.delete(6);
System.out.println("nTraversal of the B+ tree after deletion of 6:");
tree.traverse();
}
}
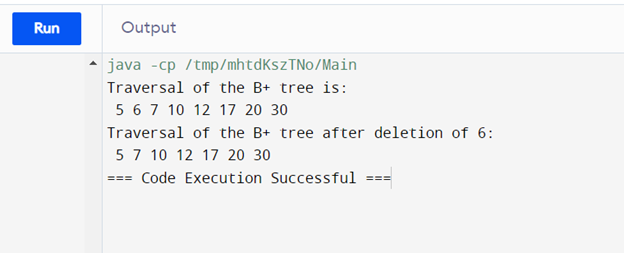
Output:
Conclusion
This blog post went into great detail about B+ Trees and their importance to database management systems. We discussed the balance factor of a tree, the difference between the internal and leaf nodes, and the use of links to connect the many linked leaf nodes. We also explained the searching, insertion, and deletion operations on the B+ Tree in DBMS, pointing out their functionality and balance.
When we compared B+ Trees to B Trees, we gained a perspective of what made them different and quite useful. This demonstrated their applicability in different areas, such as multi-level indexing and queries based on a range. Finally, we included working Java programs for each component to help our readers get a real-world sense of how the concepts covered in this tutorial apply in practice. Owing to versatility, B+ Trees are crucial when it comes to organising data and retrieving info or keeping the performance high in cases with large data sets.
FAQs
What is a B+ Tree in DBMS?
A B+ Tree in DBMS is a balanced binary search tree that stores data pointers only at the leaf nodes, ensuring all leaves are at the same height.
How do B+ Trees improve database performance?
B+ Trees optimise search, insertion, and deletion operations through balanced height and linked leaf nodes, making them efficient for large datasets and range queries.
What are the main differences between B Trees and B+ Trees?
B Trees store data in internal and leaf nodes, while B+ Trees only store data in leaf nodes. B+ Trees also have linked leaf nodes for sequential access.
Can you explain the insertion process in B+ Trees?
Insertion involves adding the key to the appropriate leaf node. If the node is full, it is split, and the middle key is promoted to the parent node, maintaining balance.
What are some practical applications of B+ Trees?
B+ Trees are used in database indexing, file systems, and applications requiring efficient range queries and large data management.