The internal data structures and algorithms that the operating system uses to implement a file system, as well as the architecture of the secondary storage that houses the file systems, are all included in the design of a file system. This includes the interface that programmers and users have with the system. In this module, we will concentrate on the file system’s secondary storage. We will also study and assess disk scheduling algorithms as well as the physical architecture of secondary storage devices. Let’s get started!
The Need for Disk Scheduling Algorithm
Because multiple processes can run concurrently and make multiple I/O requests, disk scheduling algorithms are required. A process’s requests might be found at various sectors on various tracks. The seek time may rise further as a result. By arranging the requests that the processes make, these algorithms contribute to a reduction in the seek time.

Get curriculum highlights, career paths, industry insights and accelerate your technology journey.
Download brochure
The Importance of Disk Scheduling Algorithm in Operating System
Several requests are being made to the disk at once in our system, creating a queue of requests. The backlog of requests will cause a delay in request processing times. The requests hold off until the request that is under processing completes. ‘Disk Scheduling’ is crucial in our operating system to prevent this queuing and control the timing of these requests.
It’s possible that the two distinct requests are not very close to one another. Disk scheduling algorithms assist in reducing the disk arm moment when one request is made at a location close to the disk arm and another request is made at a different location on the drive away from the disk arm.
Requests that are near the disk arm will be handled promptly, and requests that are farther away will require the disk arm to relocate. The portion of the hard drive known as the “Disk Arm” travels through various regions of the disk, approaches requests, and fulfills them. Disk Scheduling makes it possible to retrieve data quickly and easily.
Different Types of Disk Scheduling Algorithms
There are several Disk Algorithms which have been categorized into three sections that are as follows:
Traditional Disk Scheduling Algorithms:
These algorithms, which take into account the disk arm’s actual movement, are made to reduce seek times and increase productivity.
Seek Time = Distance Moved by the disk arm
First-Come, First-Serve (FCFS)
The requests are fulfilled by this algorithm in the order that they are received. First to arrive, first to be served. The most basic algorithm is this one.
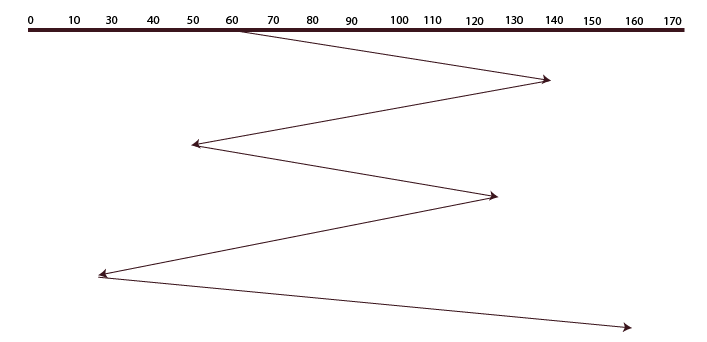
Shortest Seek Time First (SSTF)
The requests with the shortest seek times are fulfilled first in this algorithm, which checks the shortest seek time from the current position. To put it another way, the disk arm’s closest request is fulfilled first.

SCAN
The disk arm in this algorithm travels in a certain direction until it reaches its destination and fulfills every request in its path. After that, it turns around and travels in the opposite direction until the final request in that direction is located and fulfills every request.

SCAN (C-SCAN)
The SCAN algorithm and this algorithm are identical. The fact that it travels in a specific direction until the very end and fulfills requests along the way is the sole distinction between SCAN and C-SCAN. After that, it keeps going in the wrong direction until the very end, refusing to fulfill the request. then turns around once more and fulfills the requests that are located along the path. It travels in a circle.
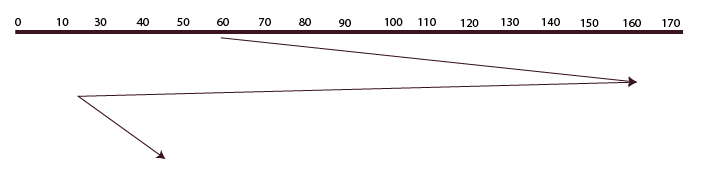
LOOK
The disk arm in this algorithm moves in a certain direction until the last request is located there and serves every request found in the path. It then reverses course and serves every request found in the path up until the last request found. The only distinction between SCAN and LOOK is that the former only advances to the request’s location; the latter does not.

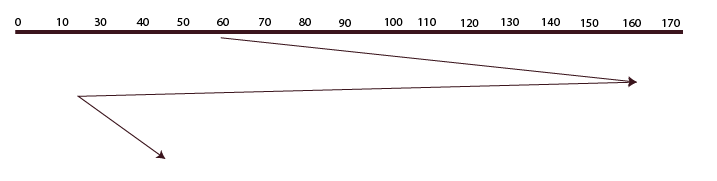
C-LOOK
The LOOK algorithm and this algorithm are identical. The fact that it travels in a specific direction until the last request is located and fulfills the requests in its path is the only distinction between LOOK and C-LOOK. After that, it goes back in the other direction until the last request is located there, failing to fulfill the request in the process. then turns around once more and fulfills the requests that are located along the path. It travels in a circle as well.
Modified SCAN-based Algorithms:
SCAN algorithm that aims to further optimize performance for some specific scenarios.
N-Step SCAN
It goes by the name N-STEP LOOK algorithm as well. This creates a buffer for N requests. Each request that is part of a buffer will be handled all at once. Additionally, new requests are routed to another buffer and are not retained in this one once it is full. As soon as these N requests are fulfilled, another top N request is made, and so on, until all requests are fulfilled with a guarantee of service.
Advantages
- It eliminates the lacking requests completely.
FSCAN
There are two sub-queues in this algorithm. All of the requests in the first queue are fulfilled during the scan, and any new ones that arrive are added to the second queue. Until the requests in the first queue are fulfilled, no new requests are processed.
Advantages
- The I/O scheduling phenomenon known as “arm stickiness,” in which the scheduling algorithm keeps processing requests at or close to the current sector, preventing any seeking, is avoided by combining F-SCAN and N-Step-SCAN.
Special Scheduling Algorithms:
They do not optimize anything but are used only for specific purposes or scenarios.
Random Scheduling (RSS)
Its name, Random Scheduling, is a natural fit for the acronym. This algorithm fits in perfectly when scheduling involves random elements like random processing times, random due dates, random weights, and stochastic machine failures. It is typically used for analysis and simulation because of this.
Last-In First-Out (LIFO)
The newest jobs are completed before the ones that are already completed, or, to put it another way, the job that is most recent or last entered is completed first, and the remaining jobs are completed in the same order. This is known as the LIFO (Last In, First Out) algorithm.
Advantages
- Maximizes the locality and utilization of resources.
- can appear a little unfair to other requests, and if new requests are received incessantly, the older and more established ones will eventually starve to death.
Key Terms in Disk Scheduling
Understanding Disk Scheduling better requires an understanding of a wide range of terms. We’ll take a quick look at each of them individually:
- Seek Time: As far as we are aware, the data might be kept on different disk blocks. The disk arm moves and locates the necessary block in order to access these data in accordance with the request. Seek Time is the amount of time the arm needs to complete this search.
- Rotational Latency: The necessary data block must move to a specific location so that the data can be retrieved by the read/write head. Thus, “Rotational Latency” refers to the amount of time required for this movement. The algorithm that rotates in the shortest amount of time will be deemed superior because this rotational time should be as small as feasible.
- Transfer Time:It takes some time to retrieve these data and deliver them as output when a user makes a request. It is called “Transfer Time” how long it takes.
- Starvation: Starvation is defined as the situation in which a low-priority job keeps waiting for a long time to be executed. The system keeps sending high-priority jobs to the disk scheduler to execute first.
- Disk Access Time: It is defined as the total time taken by all the above processes.
Disk Access Time = Seek Time + Rotational Latency + Transfer Time
Total Seek Time = Total head Movement * Seek Time

- Disk Response Time: One request is handled by the disk at a time. As a result, the remaining requests wait in a queue to be processed. “Disk Response Time” is the mean of these waiting times.
Also Read: Classification of Operating System
Aim of Disk Scheduling Algorithms
Disk scheduling algorithms are designed to optimize the amount of efficiency by controlling the way data is read and stored on the disk. Let’s learn more about each of them individually:
- Minimize Seek Time: Reduce the time it takes for the disk’s read/write head to move to the correct track.
- Maximize Throughput: Ensure that as many requests as possible are processed in a given time, improving overall system performance.
- Minimize Latency: Decrease the delay between making a request and the disk starting to process it.
- Fairness: Ensure that all requests are handled in a balanced way, preventing any one process from being starved of access.
- Efficiency in Resource Utilization: Optimize how the disk’s resources (like the read/write head movement) are used, minimizing wasted effort and power.
This helps ensure the disk operates smoothly and quickly in handling data requests.
Also Read: Functions of Operating Systems
Conclusion
Disk scheduling algorithms play a crucial role in optimizing the performance of an operating system by efficiently managing the order in which disk I/O requests are serviced. These algorithms help reduce seek time, improve throughput, and minimize latency, ensuring that the disk operates smoothly even when multiple requests are being processed simultaneously.
Each algorithm offers unique advantages depending on the system’s workload, from basic approaches like FCFS to more advanced ones like SCAN and its variations. The choice of a disk scheduling algorithm can have a significant impact on system efficiency, responsiveness, and fairness, making it a key consideration in OS design.
By selecting the most appropriate algorithm, systems can ensure quicker data access, better resource utilization, and an overall improvement in performance for users and applications alike.
FAQs
The operating system receives I/O requests from processes in order to access the disk. These requests are managed by the disk scheduling algorithm, which also determines which requests receive disk access in what order.
Seek time and rotational latency are the two main components of access time. The time it takes the disk to advance its head to the cylinder holding the desired sector is known as the seek time. The extra time it takes the disk to rotate the desired sector toward the disk head is known as rotational latency.
Large 1-dimensional arrays of logical blocks—logical blocks being the smallest unit of transfer—are used to describe disk drives. The sectors of the disk are sequentially mapped into the 1-dimensional array of logical blocks.
There are numerous circular tracks on a disk. The amount of time the read/write head needs to go from one track to another is known as the seek time.
Updated on September 30, 2024