
In this day and age data is important to make decisions and to innovate with new ideas. With more people relying on data analysis, we can tell that raw data isn’t always ready to use! Data transformation is the process of converting the data that has come from a raw form and then cleaning that data in its standard format to be used for analysis.
As the amount of data we have collected grows over the past few decades, our teams now have more information than they’ve ever had before. All this is kind of helpful but at the same time poses challenges, as you will have to filter and organize the data. The problem is not really in how to collect data, but how to decide what to keep and use. Data needs to be transformed into usable form and to work in different systems so that it could be accessible to businesses.
What is Data Transformation?
Data transformation is the process of converting raw data into data that can be analytically manipulated and modeled. It’s to get the data ready to extract some useful insights from it. This process involves several steps: Basically, data cleaning, data integration, data normalization, data reduction, data discretization and data aggregation. Data transformation eliminates erroneous data and stale data, thereby achieving a result that can be used by data mining algorithms.

POSTGRADUATE PROGRAM IN
Data Science & AIML
Learn Data Science, AI & ML to turn raw data into powerful, predictive insights.
Data Transformation Techniques
A few of the most common Data Transformation techniques include as following :
Data Smoothing
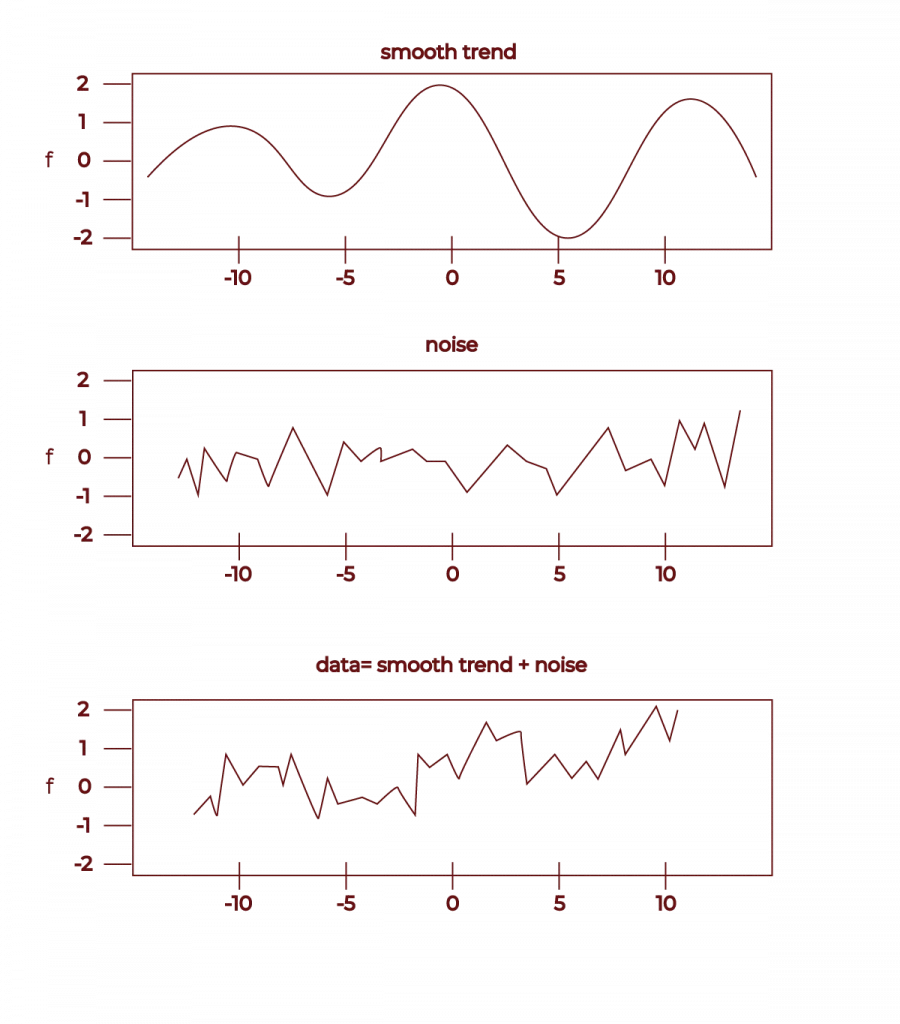
Data Smoothing is used to remove the noise in the data, it helps the innate patterns out. Data Smoothing can therefore be used to predict future trends or events. For instance, the diagram below shows how smoothing helps us to discard noise present in input data, which can in turn help us in identifying implicit seasonality and growth trends. One of the ways to Data Smoothing is moving average, exponential average, random walk, regression, binning, etc.
Attribute Construction
In this method, new features or attributes are made out of their existing features. The data is made simple in this way making data mining easier to track. For instance, if we have height and weight features of our data, we could add a new attribute like BMI which is made up of these two features.
Data Aggregation
Data Aggregation is the process of bringing together enormous quantities of data and condensing it down into a particular and summarized format that remains consumable and comprehensive. Data Aggregation provides a means for future forecasting and predictive analysis. So for example, a company could take monthly sales numbers of a product and then look it up in order to get a better view of its performance to make more informed predictions for sales in the future.
Discretization
It is a process of transforming continuous data into a set of small intervals. Most Data Mining activities in the real world require continuous attributes. Yet many of the existing data mining frameworks are unable to handle these attributes. Also, even if a data mining task can manage a continuous attribute, it can significantly improve its efficiency by replacing a constant quality attribute with its discrete values.
Benefits of Data Transformation in Data Mining
Before we cover the data transformation methods, let’s first understand some of the benefits of data transformation:
- Improved data quality: Data transformation is a process which identifies and corrects inconsistencies, errors, and missing values to provide cleaner, more accurate data for analysis.
- Enhanced data integration: Data transformation converts data into a manageable format, and then allows integration of data from multiple sources to share data among multiple systems and foster collaboration.
- Better decision making and business intelligence: Organizations can make more decisions with clean, integrated data and more informed insight for more people, which means more efficiency, more competitiveness.
- Scalability: Data transformation techniques enable a team to handle the inflated volume of data and keep an organization’s data processing and analytics capabilities at acceptable levels.
- Data privacy: Utilization of techniques such as anonymization, pseudonymization, or encryption, will help you to protect data privacy and fulfill data protection regulation.
- Improved data visualization: But data is often in the wrong format and needs to be transformed, or it’s too much and needs to be aggregated so you can create engaging, insightful data visualizations.
- Easier machine learning: Data transformation helps to get data ready for machine learning algorithms by making data manageable by machine learning algorithms so missing values or class imbalance doesn’t harm the model efficiency.
Advantages of Data Transformation in Data Mining
- Improves Data Quality: Data transformation makes data better quality by deleting errors and inconsistencies, removing missing values.
- Facilitates Data Integration: Data transformation can integrate the data from many sources, thus improving the accuracy and completeness of the data.
- Improves Data Analysis: Data transformation is used to make the data analysis and modeling ready by normalizing the data, reducing the dimensionality of the data and the data by discretization.
- Increases Data Security: Information masking and information removal can be achieved through data transformation, to protect the data.
- Enhances Data Mining Algorithm Performance: Data transformation can reduce dimensionality of data and scale the data to a scale that is common to all data points by data transformation.

82.9%
of professionals don't believe their degree can help them get ahead at work.
Disadvantages of Data Transformation in Data Mining
- Time-consuming: The data transformation can be very time consuming especially when we have a large dataset to manage.
- Complexity: Data transformation can be a complex process that takes expertise with the data processing tools as well as knowledge of the data itself to execute and interpret the output.
- Data Loss: Data transformation typically leads to data loss such as discretized continuous data loss or when removing attributes or features from the data.
- Biased transformation: Bias can occur when data are transformed because the data are not understood or utilized correctly.
- High cost: Transformations of data are expensive and involve many investments in hardware, software, and personnel.
- Overfitting: Problems of overfitting are often encountered in machine learning when data is transformed, training data obtained, due to which the model learns the detail and noise associated with training data to the extent to affect the performance of the trained model in unseen new data.
Why Do Businesses Need Data Transformation?
Every day, organizations generate a great deal of data. But it’s only valuable if you get some insights out of it and can use that to drive business forward. Data transformation is a process in which the data is converted to the formats to be used in various processes by the organizations. Some reasons for organizations to transform their data are below.
- This helps to aggregate data so you can do a thorough analysis, by transformation making disparate sets of data compatible with each other.
- This makes migration for data easier as the source format can be converted to the target.
- Data transformation aids in bringing in data structured and unstructured.
- It additionally exploits the process of transformation and enriches the data quality.
Conclusion
In this article it can be seen that data transformation is an important step during data mining where raw data needs to be transformed to enable the analysis of data. Data smoothing, aggregation, discretization, normalization, are a few techniques which can help us to have the quality, structure and usability of data. It makes sure more precise and more efficient data analysis so you get more insights and better decisions. In essence, when mastered businesses and analysts can pull back the curtains on the full power of their data and take us closer to informed strategies and ultimately innovation. If you want to learn about this in more detail and get a professional certificate consider pursuing Hero Vired’s Accelerator Program in Business Analytics and Data Science, offered in collaboration with edX and Harvard University.
What is data transformation in data mining?
Why data transformation?
What are the 2 types of data transformation?
What is the data transform rule?
Updated on February 22, 2025