
What happens when the data on which your business depends turns out wrong? How can we be sure that the data used in major decisions is well accurate, complete, and safe?
More often than we might think, these are the questions presented, especially by databases.
Data is all around us, and so are the risks. For businesses, this is no longer a question of choice but a must for maintaining the reliability of that data.
Data integrity in DBMS refers to guaranteeing that our data is true, consistent, and dependable while we use it. Whether it is a simple customer order or some complex financial transaction, we need that data to remain true from when it is entered to when it is being processed and later, at times of its usage.
Let’s dig deep into how data integrity works and why it is so fundamentally critical for databases.
Let’s dive into how data integrity works and why it’s critical for databases.
Also read: What is a Database Management System
Why Data Integrity is Crucial in Today’s Database-Driven World
The database is the heart of nearly every organisation in use today.
From a small company tracking a few customer orders to giant banks processing millions of transactions, databases store it all.
But this is where it falls apart- the data being stored is erroneous.
What does an online retailer do when it sends out shipments that are wrong because of bad data? Or, even worse, a hospital prescribing the wrong medication because of mistakes in the patient’s records.
So, how do we ensure that this information is safe, reliable, and correct? We maintain data integrity.
Data integrity ensures that when we enter data into a system, it remains the same as we expect. That is accurate, complete, and consistent. It’s about preventing undesirable problems like duplicate entries, missing records, or invalid data formats.
Why does that matter? Here’s why:
- Bad data equals bad decisions.
- If the input data we have is incorrect, our decisions on that data are going to be wrong, too.
- Trust is on the line.
- Customers, patients, and partners will rely on our data to be correct. When it isn’t, we break trust.
- Compliance is key.
- Regulations from GDPR state that businesses must maintain the accuracy as well as security of data.
Data integrity failures come at a huge price. Without strong data integrity, we may be making costly errors in our businesses.

POSTGRADUATE PROGRAM IN
Multi Cloud Architecture & DevOps
Master cloud architecture, DevOps practices, and automation to build scalable, resilient systems.
The Major Types of Data Integrity in Database Management Systems
Now that we know why data integrity in DBMS is crucial, let us further explore the types of data integrity that help us maintain it. Each type of data integrity performs a specific role in ensuring that our data will be accurate, consistent, and usable.
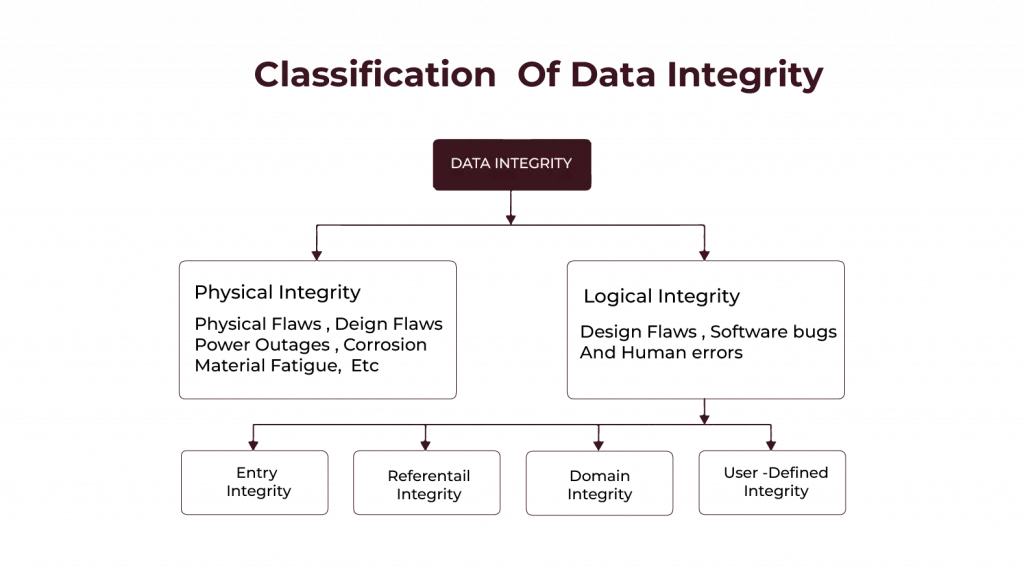
Physical Integrity: How Databases Protect Data from Physical Risks
Physical integrity protects information against possible attacks created by hardware failure, environmental flaws, or a loss of power.
Assume you are in the middle of a transaction when the power suddenly goes out. If we don’t have good defensive measures, our information will be corrupted or missing.
But we don’t have to panic.
We can protect our information by having backup systems and redundant storage like RAID-Redundant Array of Independent Disks. This arrangement spreads the data across a group of disks such that, in the event of one of them failing, the data remains safe on the rest.
This is a simple example to try to think about:
A small local grocery store uses a database to keep track of its inventory. If a power outage causes its server to crash, RAID will ensure that inventory records are not lost. It can still recover the database, and operations go on like normal.
Entity Integrity: Ensuring Unique Identification of Database Entries
Entity integrity ensures that each piece of data in a table is unique. We enforce this by using primary keys that are unique identifiers for each row in a table.
The keys thus prevent duplication and confusion.
Suppose we have a school that stores information about students. Each student must have a unique ID. If two students share the same ID, the database won’t know which record is which. This brings us to entity integrity, which guarantees that every student has a unique identifier.
Referential Integrity: Maintaining Consistency Between Related Tables
When we have multiple tables in a database, referential integrity ties all of these tables together and maintains consistency. In this way, foreign keys ensure that the intertable relationships remain intact.
Let’s assume we are running an e-commerce platform.
We will use two tables: one to store the customer details and another for the orders. Each order will reference a valid customer in the customers table.
What would happen to their orders if a customer was deleted from the customers table?
If we do not have referential integrity, then we are likely to be leaving behind orphaned records, which are incomplete records with no valid reference.
In the following example, we have a table called customers in the retail store database and then a separate table for their purchases.
Every purchase has to have a reference link back to a customer, so we never have a record of a purchase without a valid customer. When a customer is deleted, then the related purchases are either not permitted to be deleted or updated based on those defined rules.
Domain Integrity: Ensuring Data Values Follow Defined Constraints
Domain integrity helps us ensure the data we input to a table falls within predetermined limits.
Consider a column for dates. A column for dates would have domain integrity, so make sure the valid date formats alone are accepted.
It also makes sure data conforms to some constraints — like an age column allowing only between 0 and 120.
A banking system has a column on opening dates on an account.
Domain integrity ensures only valid date formats like “DD-MM-YYYY” are accepted. No incorrect and nonsensical dates like “35-02-2023.”
User-Defined Integrity: Tailoring Data Integrity Rules to Business Needs
There are times when the built-in integrity rules just won’t cut it for our particular business requirements.
That’s where user-defined integrity comes in.
We develop user-defined rules for data integrity as each business has unique requirements.
As an example, a firm may mandate that employee IDs must begin with “EMP” and comprise precisely five digits. That’s not a standard integrity rule, but it can be enforced by a user-defined constraint.
For example, in a logistics company, every shipment might have to be assigned a weight value between 1 kg and 100 kg. User-defined integrity ensures values outside the above range are rejected and not to enter incorrect values.
Also read: Integrity Constraints in DBMS
Common Threats and Challenges to Maintaining Data Integrity in DBMS
So, what are the possible causes of data not staying reliable?
We all know that even the best systems face challenges. Let’s jump into the general threats and issues that could go wrong with data integrity in DBMS.
Human Errors: The Effect of Incorrect Data Input and Processing
No matter how advanced our system is, people make mistakes. Typing errors, incorrect deletion, or incorrect formats of data can cause corrupted or wrong data.
For example, we enter one customer’s name as “Rahul Kumar” in one record and “R. Kumar” in other record. And there you go with duplicate data.
Simple mistakes will cause problems in large databases. Repairing them later is a headache and consumes time.
To reduce these chances, proper training, strict rules of validation, and automated checks of the inputs must be provided.
Cybersecurity Threats: Attacks Compromise Integrity of Data
Cyberattacks get smarter every day.
Hackers are no longer stealing data; they corrupt the data, too. Breach of data, malware, and ransomware attacks can all alter or destroy key information.
For instance, consider a financial database that has been attacked by ransomware. The attacker steals information but sometimes even corrupts records, which messes up transactions.
Such accurate data becomes hard to recover in such cases.
We cannot afford to ignore this threat. Reducing risks includes implementing strong encryption, firewalls, and real-time monitoring.
Also read: The Importance of Cyber Security
Hardware Failures and Environmental Risks to Physical Data Integrity
Our data is only as good as the hardware that holds it. Hardware failures—like crashing hard drives or faulty servers—can wipe out years of work instantly. Not to mention, natural disasters like floods, fires, and earthquakes can destroy servers.
If we haven’t backed up our data, this could lead to a massive loss.
Suppose a school loses an entire student records system because a server crashes. Without a backup, they would be in significant trouble.
This is one of the main reasons we use physical integrity measures like redundant storage, off-site backups, and disaster recovery plans, so we don’t lose files or any other type of data to begin with.
Data Transfer Errors: Preserving Integrity Across System Boundary
We transfer data between systems constantly. What happens when something goes wrong in that transfer?
Data migration or integration errors can corrupt some records.
Consider moving customer details from an old CRM system to a new one. However, the addresses come out jumbled or missing. We’ve now lost valuable data.
To avoid these errors, data validation protocols must be implemented both before and after the transfer. Data integrity checks prevent data from getting lost or corrupted during migrations.
Real-World Applications of Data Integrity Across Industries
Data integrity is always a core activity of every industry, whether in banking or health. Without it, systems can’t perform what they are supposed to do. The impact is disastrous.
Let’s take a look at how data integrity is utilized in different fields.
Healthcare: Maintaining Accuracy and Security of Patient Records
Hospitals and clinics operate on patient data. Everything depends on accuracy-information-from diagnosis to prescriptions.
If a patient’s data is wrong, it could lead to serious consequences.
If the EHR (electronic health record ) system places an incorrect allergy against a patient, the entire system might come to suggest inappropriate treatment.
That is where data integrity comes in.
Accuracy in a medical record means that care providers can always deliver the best results to their patients. Data checks, audit trails, and secure systems keep such records reliable and secure.
Finance: Protecting Transaction Data and Risk of Fraud
For instance, in a banking scenario, any small mistake or wrong input of data can be huge. To eliminate the risk of fraud and errors in transactions, it is of utmost importance that transaction data in financial institutions is clean and secure.
A bank’s credit card processing system revolves around the credibility of all the details about the customers.
If the details get tampered with or are compromised, then it could be a fraud which would leave both the customer as well as the bank in a big mess.
Data integrity in finance ensures that all transactions are authenticated, secure, and compliant with regulations like GDPR. It also helps to detect anomalies that may indicate fraudulent activity.
Education: Maintaining Consistency in Student Records and Institutional Data
Higher learning institutions contain a large amount of student data-grades, attendance, and personal information.
All of it needs to be consistent and updated.
Think of an institution or university, for instance, dealing with thousands of student records. For example, one wrong record could make a mess at registration time or result in incorrect exam schedules for one student.
Therefore, by ensuring data integrity, schools can monitor the progress of every student without any issues. Audits and regular updates will ensure that such data stay accurate over the course of time students spend in an institution.

82.9%
of professionals don't believe their degree can help them get ahead at work.
Best Practices for Protecting and Maintaining Data Integrity in DBMS
How do we ensure our data is accurate and secure? It’s all about the best practice, which doesn’t cause problems and catches them early on.
Let’s break it down.
Implementing Referential Integrity Constraints and Validation Rules
First off, introduce some rules that keep data consistent. We can enforce referential integrity constraints such that relationships between tables aren’t going anywhere.
We prevent bad data from coming in by placing limits on what data should be entered. For example, an email form only accepts valid data. Therefore, errors are not allowed.
Using Redundant Storage Systems and Regular Backup Strategies
We can store data in more than one place, which is a smart move. The use of redundant storage systems such as RAID will ensure our data is saved if one server fails while others are still safe.
Along with that, regular backups should be done.
We shall set up scheduled backups and put the files off-site so that in case of disaster, we recover quickly.
Ensuring Proper Access Control and Encryption for Sensitive Data
Data integrity deals greatly with protection. It, therefore, deals with who grants the access rights to sensitive information and related view/edit access.
This means that we must have systems using access control, for which permission is well-controlled. We can allow varying degrees of access depending on the job function of employees.
Encryption also ensures that in the event some unauthorised access is obtained, they cannot read or misuse any information.
Encryption keeps our data intact, whether it is resting or being transferred.
Regular Audits, Error Checking, and Monitoring for Data Integrity
We don’t want problems to arise.
Through running periodic audits, we detect prospective errors or anomalies early on. An audit basically entails checking our database for any missing, duplicated, or incorrect data.
Error-checking protocols also catch the problems right when they happen to us. These automated systems flag potential issues so that we can find and fix them before they do any harm.
Lastly, establishing continuous monitoring tools keeps an eye on our data and alerts us towards possible integrity breaches.
Conclusion
Data integrity in DBMS is the basis of robust, reliable, accurate, and consistent data management. In the absence of such integrity, even the most advanced system may well fall prey to errors, breaches, and inconsistencies.
From human errors to cybersecurity threats, data integrity ensures that businesses can trust their data in every situation. At the end of the day, it’s not just about storing data—it’s about storing trustworthy data.
Ultimately, focusing on data integrity goes beyond avoiding errors and becomes the basis of being sure that every decision that is made is founded on data we can trust, which supports the potential for sustainable operations and growth.
What is data integrity in DBMS?
How can we maintain data integrity in databases?
What would be the usual threats against the integrity of data?
Why is data integrity important to business?
Updated on September 23, 2024