Ever wondered why databases always become hard to manage once they grow? Well, the challenge is real, and most of us experience it.
While designing a database, there is one major thing we have to consider: Cardinality in DBMS.
So, what is cardinality? And why should we care about it?
Cardinality is simply the relation between the tables of a database. It defines how rows of one table are linked to rows of another. Without it, we’d end up in data chaos, which translates directly into slow performance, incorrect queries, and quite sore heads.
Imagine running a small business selling orders to customers. If your database doesn’t successfully match the customer’s orders, you’ll be hunting through hours of information that should be a piece of cake.
That is where cardinality in DBMS comes in handy. It lets us specify rules regarding which tables must communicate with each other, making the flow of information smooth and guaranteed.
Exploring the Concept of Cardinality and its Role in Databases
What does cardinality mean in DBMS?
Cardinality is the frequency at which an entity takes part in a relationship. It can be measured as the number of occurrences when a row of a table participates in a relationship.
In the case of databases, this definition informs us as to how one table relates to another.
Let’s decipher this notion further.
Suppose we have a very simple database with two tables: one called “Customers,” and another called “Orders.” Cardinality would tell us how many orders a single customer can have, whether one order could have more than one owner, and so on.
This information enables us to structure our data properly.
Now, think about how useful this is.
Cardinality ensures that when we query the database, the data is accurate, without unnecessary duplicates or gaps. It is the backbone of designing relational databases, ensuring clear and logical relationships between tables.
In other words, cardinality in DBMS gives an order in a database.
It saves you from a dead-end of duplicate data, keeps it efficient, and gives you the required information as fast as possible.
Also Read: What is a Database Management System?

Get curriculum highlights, career paths, industry insights and accelerate your technology journey.
Download brochure
The Four Types of Cardinality Relationships and Their Impact on Database Structure
Let’s have a closer look at some types of cardinalities you will definitely encounter.
There are four main kinds of relationships between tables. One to One, One to Many, Many to One, and Many to Many.
Each of these serves a different purpose in determining how our data is connected.
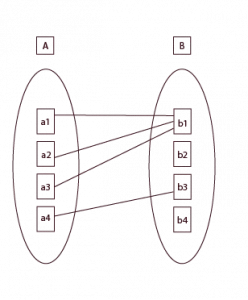
One-to-One Cardinality in DBMS and Its Applications
A one-to-one relationship exists when, for every record in Table A, there is an equivalent record in Table B. This is the rarest of relationships but is very important when applied.
For example, suppose we run a hospital.
Each patient has one medical ID. No other patient can have that same ID; no ID should belong to more than one patient. It is a one-to-one relationship between the “Patients” table and the “Medical IDs” table.
This kind of cardinality rarely occurs in real life. But when it does, it makes items like storing personal or sensitive information within separate tables further enhance security.
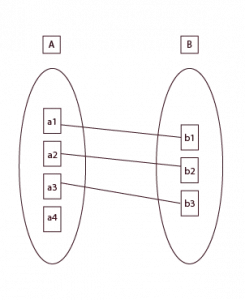
One-to-Many Cardinality: A Common Database Relationship
One-to-many is probably the most common database relationship. That means one record in Table A can be related to many records in Table B.
Consider an example of an online store. Many orders can be placed by a customer in Table A. On the other hand, an order belongs to only one customer.
It’s a classic one-to-many cardinality, which is good if we have multiple entries for one entity, such as customers who shop frequently.
This type of structure keeps everything clean and shows how one customer can have multiple orders. The data does not repeat, and when we make a query for the database, that data will remain clean and will be in its ordered position.
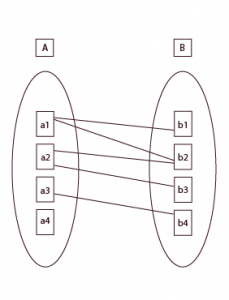
Understanding Many-to-One Cardinality and Its Use Cases
In a many-to-one relationship, several records in Table A relate to one record in Table B. It is basically the flip side of one-to-many.
Consider we have many employees working in one department. Each employee owns a department, but many employees may be working in the same department. In a school, many students may be assigned to one class, but each class is unique.
This shows how the many-to-one cardinality helps maintain items related in a more realistic manner.
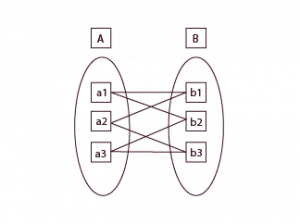
Many-to-Many Cardinality: Complex Relationships in DBMS
The many-to-many relation is the most complex and thus requires a little extra effort to manage. This relation relates many records in Table A with many records in Table B and vice versa.
This will allow us to express many connections between tables without confusion.
Consider a college where students take many courses, and each course has several students as well. We cannot relate them directly, but we need a middle table for this type of relationship.
This kind of relationship helps us trace intricate interactions within systems such as educational websites or project management applications.
High vs. Low Cardinality: How Data Uniqueness Affects Databases
What is high or low cardinality for a database?
It is one of those very common questions that pop up when we are working with databases.
Cardinality in DBMS is not merely the relationships between tables. It is also related to the uniqueness of data in columns.
High cardinality means the column has so many unique values, while low cardinality means there are many duplicate values. Knowing the difference helps us design efficient databases.
Suppose we are maintaining customer data for an online shopping site. If we track customers by their email addresses, the cardinality is high since each email address is unique. However, if we track purchases by product category, perhaps the cardinality is low since many products are in the same category, such as electronics or clothing.
Why does this matter?
High cardinality can be very fast because of unique data that will be easy to index. Low cardinality slows things down, especially the order by and filter clauses about repetitive data.
In the design of databases, we should think of this balance, and they might work correctly and therefore.
Simply stated, high cardinality is good for uniquely valued data, while low cardinality can be helpful in grouping similar data.
Also read: Entity in DBMS
Cardinality in DBMS relies directly on the performance of the query.
And how is it true?
When querying a database, quite often, we are looking for a small particular amount of data. The higher the cardinality of the column (the more different values it contains), the more chances there are to find the desired information quickly and with much greater accuracy. In other words, fewer duplicates to sift through.
In addition, low cardinality is tedious. When many values repeat in the same column, the database has to sift through the same data over and over to find unique values, taking longer.
Here’s a simple example:
Think how long it will take you to search for customer orders with a unique order number (high cardinality) versus searching by product type (low cardinality)
The first search is straightforward and super fast because every order number differs. However, the search by product type may bring thousands of results, which slows down the selection process for viewing that specific order.
To achieve maximum performance:
- Use high cardinality columns to filter and search.
- Order low cardinality in such a way that it minimises redundancy.
- Index high cardinality columns to speed up the search.
- Cardinality Considerations When Building Queries.
We can make sure that the database remains efficient and responsive long after we design it by considering cardinality while building our queries.
Choosing the Right Cardinality for Database Design Based on Business Needs
So, how do we select the appropriate cardinality when designing a database?
Again, selection is strictly dependent on the business requirements. It’s not just about understanding cardinality in a DBMS but also knowing which fits in with the problem we are trying to solve.
When to Use One-to-One Cardinality
We use it when every entity in one table must match exactly one entity in another. It is frequently used in applications for security or private data.
When One-to-Many Makes Sense
It is applicable whenever one entity connects with several entities, such as a customer buying some items or a teacher having a number of students. Most enterprises rely on this type of cardinality when dealing with day-to-day data. This is flexible as well as simple and yet powerful.
Many-to-One for Simplifying Complex Data
This can be used whenever several entities refer to one. This structure simplifies data, ensuring each post is tied back to one conversation thread.
Many-to-Many for Complex Connections
Lastly, many-to-many cardinality addresses what are usually more complicated relationships. This is when two separate types of entities connect in more than one way.
Also read: Data Models in DBMS
Conclusion
Cardinality in DBMS can help determine how intense the relationship is between entities. It helps describe how tables are related and continues to affect everything from performance to data organisation.
Whether you interact with sole units of a single unit or are dealing with the more complex many-to-many relationship, cardinality helps you keep things structured and accessible on your database. The right choice based on your business needs allows your database to scale well, dodging common mistakes such as slow queries or duplicated data.
By understanding and applying cardinality in DBMS correctly, we can create robust, efficient databases that grow along with the system while providing fast and accurate results.
FAQs
Cardinality refers to the relations among the tables in a database. It shows how many times one record in a table relates to a record in another table.
Cardinality determines how fast a database can retrieve data. High cardinality (many unique values) makes queries fast, while low cardinality (many repeated values) slows down the speed.
There are four main types of cardinality:
- One-to-One: Each record in Table A links to one in Table B.
- One-to-Many: A single record in Table A links to multiple records in Table B.
- Many-to-One: Multiple records in Table A link to one in Table B.
- Many-to-Many: Multiple records in Table A relate to multiple records in Table B.
Yes, your relationships might change when your business changes.
A one-to-one relationship may become one-to-many in the case of an enterprise and its growing needs. This is why you should maintain and keep reviewing your database structure.
Updated on January 29, 2025