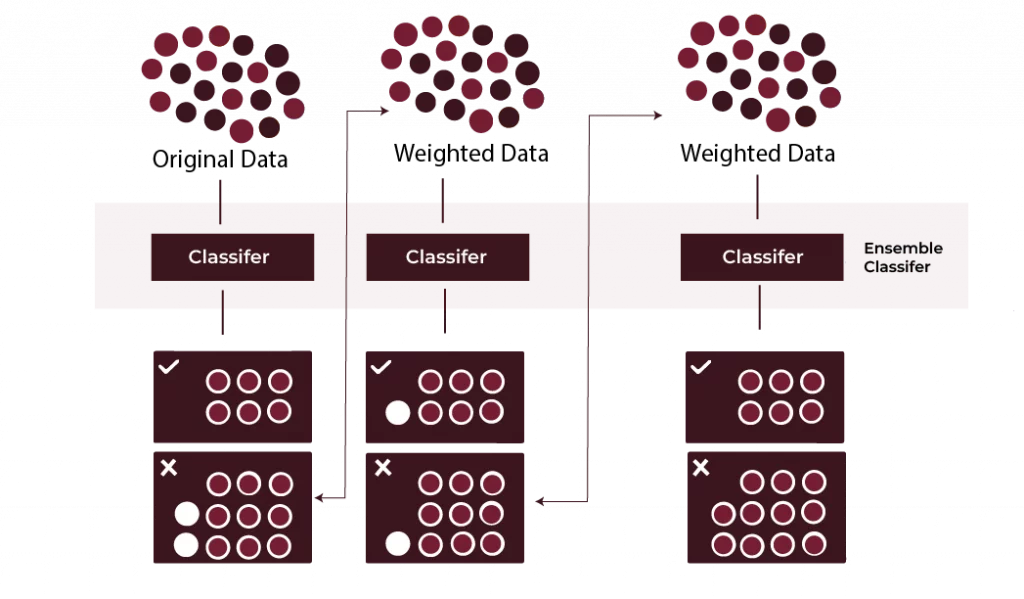
One of the big ensemble learning algorithms in machine learning is AdaBoost. It was first introduced in 1995 by Yoav Freund and Robert Schapire. AdaBoost combines multiple weak classifiers to create one strong classifier. The basic idea behind AdaBoost is that it will improve the accuracy of a weak learning algorithm by combining it with other weak algorithms in a series of iterations. It operates by training a series of weak learners, such as decision stumps (shallow trees), each of which performs only slightly better than random guessing.
In this article, we will deep dive into the details of the AdaBoost algorithm in machine learning. We will cover in-depth about ensemble learning, different types of learners such as weak and strong, working of the AdaBoost algorithm, code examples in Python, and much more.
What is Ensemble Learning?
Ensemble learning is a machine learning technique that combines two or more learners (such as neural networks or regression models) to generate more accurate predictions. An ensemble model makes predictions that are more accurate than those of a single model by combining multiple of them. In this machine learning paradigm, problems are solved by combining several models, sometimes referred to as base learners. Using the advantages of each model to create a stronger one is the main goal of ensemble learning.
Ensemble learning methods are mainly of two types:
Bagging: This process involves creating several subsets of the original data, training different models on these subsets, and then averaging the predictions to reach a final output. It is also known as bootstrap aggregating. Random forest is the best example for bagging or bootstrap aggregating.
Boosting: Boosting is an iterative technique that modifies weak learners’ weights to have them focus more on the cases that were previously misclassified. One of the best examples of a boosting approach is AdaBoost, and we will learn its algorithm next.
While both methods seek to reduce mistakes, boosting focuses on strengthening the model’s weak points.
Get curriculum highlights, career paths, industry insights and accelerate your data science journey.
Download brochure
Weak and Strong Learners
Weak and strong learners are two concepts used in ensemble learning. They are known as classifiers in machine learning.
Weak Learner: A weak learner algorithm is considered weak if it can only slightly outperform random guessing, like flipping a coin, on a particular issue. It tends to underfit the data and is usually simple. However, it can be utilised to create a strong learner that produces incredibly accurate predictions by combining it with other weak learners using strategies like boosting.
Strong Learner: A strong learner algorithm can identify complex patterns in the data and produce extremely precise predictions with extremely low error rates. It is usually very complex and, if improperly regularised, can lead to an overfitting of the data.
What is Boosting?
Boosting is an ensemble learning technique that turns a group of weak learners into a strong learner to reduce training errors. It is a process that goes step by step, with each new model trying to fix the mistakes made by the previous one. The preceding model is necessary for the subsequent models to function. The main idea of boosting is:
Give misclassified samples additional weight in subsequent iterations to have the next weak learner pay more attention to them. This increases the importance (weight) of the misclassified occurrences.
Add up all weak learner’s guesses are combined and weighted based on accuracy to produce the final forecast.
When building a new dataset, the methods used by different boosting algorithms to rank incorrectly predicted data instances vary significantly. There are two main boosting algorithms in machine learning:
Adaptive Boosting (AdaBoost): To reduce the training error, this approach iteratively finds misclassified data points and modifies their weights.
Gradient Boosting: The gradient boosting method repeatedly identifies misclassified data items and adjusts their weights to lower the training error. Model training in gradient boosting is sequential and is done by minimising a loss function using gradient descent. Every model aims to correct the residuals (errors) of the previous model.
What is the AdaBoost Algorithm?
The AdaBoost method, known as Adaptive Boosting, is an ensemble learning method used in machine learning that has been developed to enhance the performance of weak learners by consolidating them into a strong model. It is mostly used for tackling classification problems but can be modified to work for regression as well. AdaBoost suggests concentrating training on cases that are harder to classify, thus, enhancing the accuracy of the model in the process. Adaboost does not work well with noisy data and is quite sensitive to other different data.
AdaBoost works by weighting the instances in the training dataset based on the accuracy of previous classifications. Each weak learner is given a weight by the algorithm based on how accurate it is; these learners are then integrated into a final model that uses a weighted sum (for regression) or a weighted majority vote (for classification) to create predictions. In comparison to independent model training methods such as Bagging or Random Forest, AdaBoost sequentially trains models and modifies the data distribution after each cycle.
AdaBoost is widely utilised in applications such as fraud detection, spam filtering, and facial recognition due to its versatility and resilience. However, it may be susceptible to anomalies and noisy data, which could impair its functionality.
How does the AdaBoost Algorithm Work?
The AdaBoost algorithm works simply by training the weak learners for classification and then creating a powerful classification model for the final output. The given below is the simple working of an AdaBoost algorithm in machine learning:
Initial Training: AdaBoost’s first step is to build a weak learner, typically a simple model such as a decision stump, which incorporates strategies from single decision trees. At this stage, all the data points have been assigned an equal weight.
Weight Update: In each round of learning, the weak learner is trained and thereafter held to test with training samples to check how correct decisions have been made. Some of them are 0 representations and incorrectly classified are now to move to the next step and are given much lower weights.
Next Learner: AdaBoost now prepares the next weak learner but this time, it pays close attention to the instances that were previously misclassified. This is the series of soft amigos you watch here again.
Final Model: The final model represents all the previously built weak learners applied in combination with each one giving more attention to the more correct ones. This method allows several less effective learners to be made better and stronger into a single classifier.
Now let’s go through the AdaBoost algorithm step by step:
Step 1: Initialise the weight
Every training instance is given the same weight at the start of the algorithm. In a dataset comprising N instances, the starting weight assigned to each i instance is:
Step 2: Train a Weak Learner
A weak learner (such as a decision stump) is trained on the dataset in each iteration. The instance weights influence the learner’s attempt to categorise the training samples according to their attributes. There must be an accuracy of greater than 0.5 to make sure the algorithm is not making guesses.
Step 3: Evaluate the Weak Learner
The error rate of the weak learner is calculated. The error rate ϵ is the sum of the weights of the misclassified instances:
Where,
𝑦 𝑖 is the true label of instance 𝑖,
ℎ(𝑥𝑖) is the prediction of the weak learner,
𝐼 is an indicator function that is 1 if the instance is misclassified and 0 otherwise.
Step 4: Update Weights of Instances
The algorithm then updates the weights of the misclassified instances, increasing their importance in the next iteration. The new weight , for instance, i in iteration t +1 is:
Where is the weight of the weak learner in the ensemble and is computed as:
= 1/2ln((1-)
Step 5: Normalise Weights
The weights are normalised so that they sum to 1:
Step 6: Repeat
These steps are repeated for a predefined number of iterations or until the error reaches an acceptable threshold.
Step 7: Final Prediction
The final prediction is a weighted majority vote from all weak learners. The prediction of the ensemble is given by:
Where:
is the final strong classifier,
is the prediction from the t-th weak learner,
is the weight of the t-th weak learner.
AdaBoost in Python – Practical Implementation
To implement the AdaBoost algorithm in Python, we will use some datasets from scikit-learn. We will see both the classification and regression examples using two different datasets in Python.
AdaBoost for Classification Task
# import all relevant imports
from sklearn.ensemble import AdaBoostClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_breast_cancer
from sklearn.metrics import accuracy_score
# Load any dataset (like breast cancer for instance)
data = load_breast_cancer()
X = data.data
y = data.target
# Split dataset into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# Initialise a weak learner (i.e., Decision Stump)
weak_learner = DecisionTreeClassifier(max_depth=1)
# Initialize AdaBoost with the weak learner
adaboost = AdaBoostClassifier(base_estimator=weak_learner, n_estimators=50, learning_rate=1.0, random_state=42)
# Train AdaBoost on training data
adaboost.fit(X_train, y_train)
# Make the predictions
y_pred = adaboost.predict(X_test)
# Evaluate algorithm performance
model_accuracy = accuracy_score(y_test, y_pred)
print(f'AdaBoost Accuracy: {model_accuracy * 100:.2f}%')
Output:
AdaBoost Accuracy: 97.66%
For the AdaBoost classification task, we use a decision stump (DecisionTreeClassifier with max_depth=1) as the weak learner in this example. AdaBoostClassifier is applied to the breast cancer dataset. Finally, the accuracy of the model is calculated after training.
AdaBoost for Regression Task
# import all relevant imports
from sklearn.ensemble import AdaBoostRegressor
from sklearn.tree import DecisionTreeRegressor
from sklearn.datasets import load_diabetes
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
# Load any dataset (like diabetes for instance)
diabetes = load_diabetes()
X = diabetes.data
y = diabetes.target
# Split dataset into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Initialize AdaBoost with a DecisionTreeRegressor as the base learner
ada_model = AdaBoostRegressor(
base_estimator=DecisionTreeRegressor(max_depth=4),
n_estimators=50,
learning_rate=1.0,
random_state=42
)
# Train the AdaBoost model
ada_model.fit(X_train, y_train)
# Make predictions
y_pred = ada_model.predict(X_test)
# Calculate mean squared error
mse = mean_squared_error(y_test, y_pred)
print(f'Mean Squared Error: {mse:.2f}')
Output:
Mean Squared Error: 2895.41
For the AdaBoost regression, we use the AdaBoostRegressor instead of the AdaBoostClassifier. A DecisionTreeRegressor is used as the base learner instead of a classifier. Finally, to measure the model’s performance metric of the regression tasks, we use mean_squared_error instead of accuracy.
Advantages and Disadvantages of AdaBoost
There are various advantages and disadvantages of AdaBoost in machine learning. Here are a few of them:
Advantages of AdaBoost
High Accuracy: AdaBoost frequently performs more accurately than other models. Focusing on cases of misclassification, it adjusts to the challenging regions of the records distribution.
No Overfitting: AdaBoost has a lower overfitting tendency than a lot of other models. Therefore, it is said to be the best non-overfitted algorithm in machine learning.
Easy to build: Using weak learners such as decision stumps, the algorithm is simple to implement.
Versatility: AdaBoost is a flexible set of rules that may be applied to a variety of special types of issues because it can be employed with several base newbies.
Disadvantages of AdaBoost
Sensitive to Noisy Data: Because AdaBoost highlights challenging samples, it may perform poorly in situations when there is a lot of noise in the data.
Model Selection: AdaBoost performance is highly dependent on these choices, therefore choosing the right susceptible learner and fine-tuning hyperparameters may be challenging.
Requires Weak Learners: AdaBoost’s effectiveness is significantly reliant on the poor learner. AdaBoost might not function properly if the weak learner is overly strong.
Overfitting: AdaBoost can still overfit if the number of iterations is too high, even though it is far less likely to do so than a few other algorithms.
AdaBoost Variants
Although AdaBoost is a powerful algorithm itself, many modifications have been suggested for various tasks or improvements:
Real AdaBoost: This variant lets weak learners provide weighted outputs in addition to a yes or no answer.
SAMME: In multiclass classification, the SAMME (Stagewise Additive Modelling using a Multi-class Exponential loss) approach is used to boost weak learners (usually decision trees) into a powerful ensemble classifier. A modification that is applied to tackle problems with more than two classes, SAMME extends the capabilities of AdaBoost for multiple classes.
AdaBoost.R2: This variant transforms the application of AdaBoost to Regressional problems rather than Classification problems.
Every variant modifies the basic Adams boost framework in order to accommodate more difficult or specific problems.
Applications of AdaBoost
Applications like text categorization, object recognition, and facial identification frequently use AdaBoost. AdaBoost is best when there are a lot of unimportant features or when the data is noisy. AdaBoost is widely used in various fields, including:
Face Detection: The AdaBoost algorithm is used in face detection technology. The Viola-Jones face identification technique combines numerous weak classifiers with AdaBoost to identify faces in photos.
Text Classification: Text documents can be divided into various groups using the AdaBoost algorithm. AdaBoost algorithm helps in text classification by improving the accuracy of the model combining the predictions of multiple weak learners.
Natural Language Processing (NLP): AdaBoost can enhance sentiment analysis and text content category trends overall.
Customer Churn Prediction: By identifying consumers who are likely to discontinue using a service, AdaBoost is used by businesses to predict customer churn.
Speech Recognition: AdaBoost can be used to enhance the precision of phoneme or word popularity structures in speech recognition.
Fraud Detection: By concentrating on unusual patterns, AdaBoost can assist in locating fraudulent transactions in financial systems.
Conclusion
AdaBoost is a powerful and widely used algorithm in machine learning. The way it works is that it combines multiple weak learners to create a strong model that can solve problems of the sort of complexity entailed by the applications considered here. In practice, although it may be sensitive to noisy data, AdaBoost still cuts an effective technique for many real-world applications from face detection down to fraud detection.
The AdaBoost algorithm is not well understood and its inner operations noted for any person willing to apply boosting in machine learning. Due to its capability to adapt to hard instances while maintaining high accuracy, AdaBoost will be important for years in ensemble learning.
FAQs
What is the difference between AdaBoost and other ensemble methods like Bagging and Random Forest?
AdaBoost is an algorithm that differs from Bagging and Random Forest in how it treats training data and weak learners. While Bagging (including Random Forest) trains multiple models in parallel on independent bootstrapped datasets and then combines their predictions, AdaBoost trains weak learners sequentially. In the case of Random Forest, decision trees are used as weak learners, and the technique brings in randomness by selecting different feature subsets. On the other hand, AdaBoost generally uses decision stumps (i.e., one-level trees) without any random features.
Is AdaBoost deep learning?
No, AdaBoost is not a part of the deep learning algorithm. AdaBoost falls into the category of boosting methods in machine learning and is concerned with enhancing the performance of weak learners by combining them to produce a strong learner.
What is the depth of the tree in AdaBoost?
In AdaBoost, the weak learner used is typically a decision stump - a decision tree of depth 1. This expresses that it has only one level and makes splits based on just one feature. However, the depth of the tree is a parameter.
What is the use case of AdaBoost?
AdaBoost is commonly implemented in different types of classification tasks where the improvement of weak learners can be boosted. It has found successful applications in computer vision for face detection, text classification, spam detection, and even fraud detection within financial systems.
How does the learning rate parameter affect AdaBoost?
The learning rate in AdaBoost determines the weight placed on each classifier when building the final model. If the learning rate is small, then there will be a need for the other parameters (number of iterations) to be large to achieve good performance. In this way, it can not overfit especially in the presence of noise. A large learning rate makes Adaboost more prone to overfitting; it will pay too much attention to noisy points.