
Over the past years, exponential data growth pressure has created a demand for systems leveraging large datasets while keeping processing and storage times low. HBase, part of the Hadoop ecosystem, especially solves this challenge. With a distributed structure and massive scalability, HBase allows data to be easily stored and retrieved in locations with large volumes.
In this article, we will cover the HBase Architecture comprehensively and explore its major pieces and how they facilitate data handling at scale.
What is HBase?
HBase is a distributed, non-relational, and highly scalable database built on top of Hadoop Distributed File System (HDFS). Based on Google’s Big Table, it is designed to use structured data on large clusters of commodity hardware. HBase is a column-oriented storage model-based system with sparse datasets and real-time analytics best suited to traditional relational databases.
Key Features of HBase:
- Scalability: Sends data to spread out nodes in a cluster automatically.
- Consistency: It has strong consistency in the read and write operations.
- Flexibility: Dynamically adds columns to support varying data needs.
- Integration: It works with Hadoop and acts under MapReduce to process.

POSTGRADUATE PROGRAM IN
Data Science & AIML
Learn Data Science, AI & ML to turn raw data into powerful, predictive insights.
Core Architecture of HBase
The architecture of HBase is a master-slave architecture because this makes it easy to scale and fault-tolerant. It’s abstract to handle data across distributed systems.
Master-Slave Topology
The HBase system is a master-slave structure. HBase Master is responsible for system management and system control. It manages tasks such as:
- Worker nodes for storing and retrieving data are assigned to the RegionServers, which have regions assigned to them.
- They looked at the health of region servers and load balancing to balance the load and spread the data evenly among the region servers.
- Each RegionServer manages a region. Parallel RegionServers operate together to distribute data evenly across the system and to support high performance with substantial data.
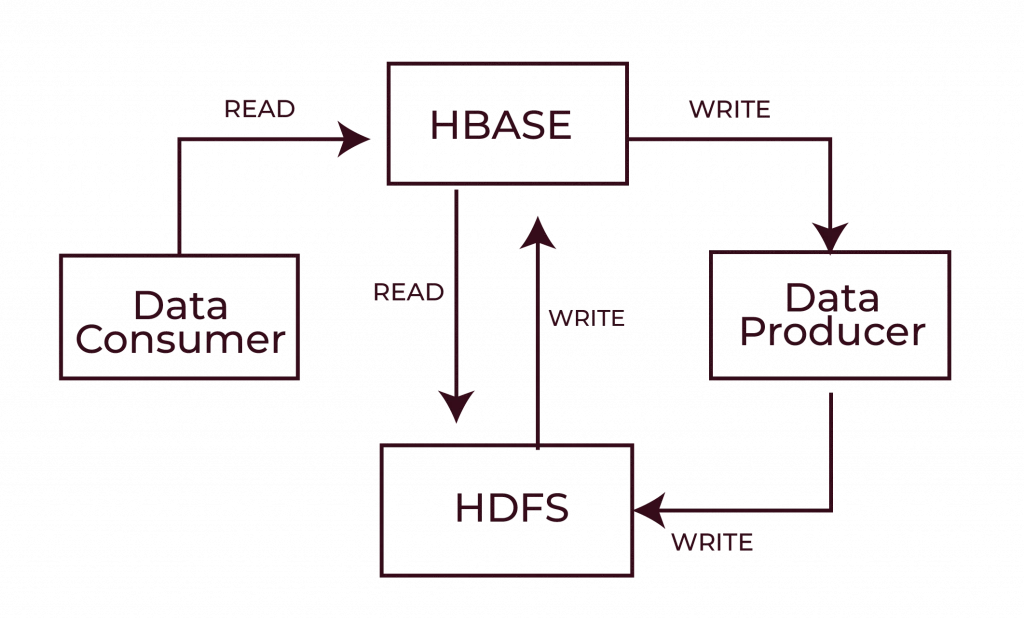
HDFS Integration
HBase relies on the Hadoop Distributed File System for long-term data storage. This integration is instrumental to its capacity to store and manage substantial volumes of data:
- Durability and Scalability: Data is stored in a distributed environment using HDFS such that HBase can grow as the volume of data grows. Replication is a fault tolerance mechanism offered by HDFS, so data will remain available even if one node goes down.
- Data Storage: HBase stores data blocks in HDFS that are smaller than those in HDFS based on the data in HBase. This lets you read and write it to it efficiently and then replicate those blocks to different nodes for reading and writing to protect your data in case one of your nodes fails.
- HBase is built upon this master-slave model and HDFS, allowing it to deal with huge amounts of data with high availability, making data storage and retrieval efficient and reliable.
Also Read: What is Hadoop?
Key Components of HBase
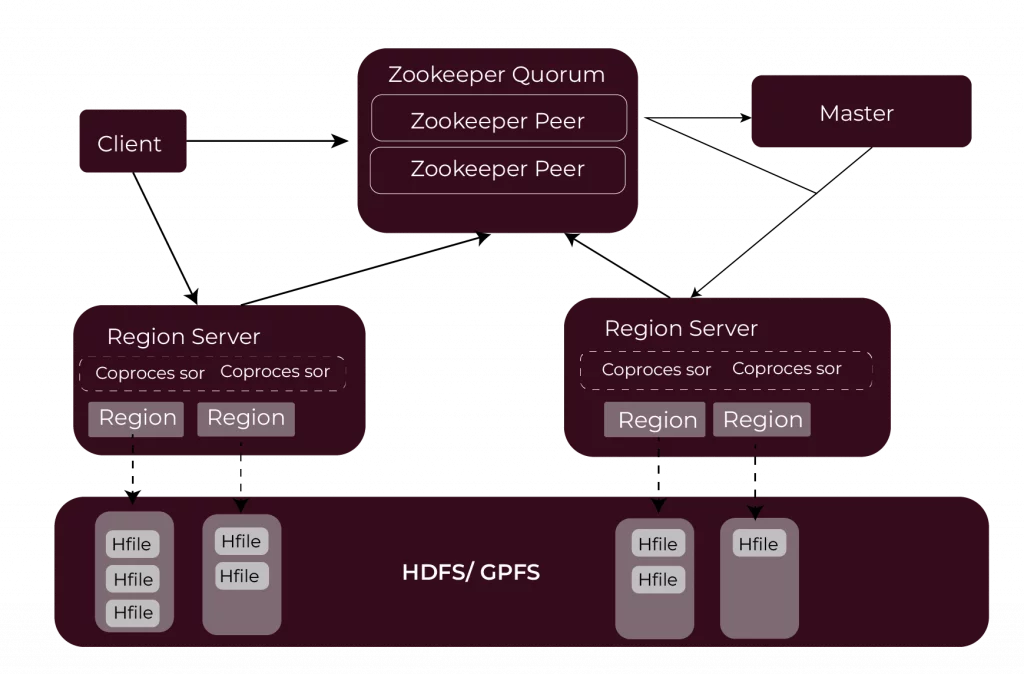
1. HBase Master
Properties of the central controller for the HBase cluster – the HBase Master. It doesn’t directly deal with data storage or systems. Sly deals with the overall management of the system.
Responsibilities:
- Region Assignment: It chooses region servers and ensures they are evenly loaded.
- Monitoring: It looks at how healthy and performing RegionServers are and will redistribute regions if necessary.
- Metadata Management: The Master handles changes in the table structure, but metadata manages who owns what in the table and its contents.
2. RegionServers
HBase functions around RegionServers. It deals with the work of storing and retrieving the data. The HBase data is partitioned into various region subdivisions; each RegionServer manages a set of them.
Functions:
- Data Storage means that in RegionServers, data is out in MemStore (for In Memory Op) and StoreFiles (for Storage on HDFS).
- Data Retrieval: Their responses to client requests are read data off disk or read data off memory.
- Dynamic Region Splitting: RegionServers split regions when data grows so that data is spread evenly across the cluster.
3. Zookeeper
HBase cluster’s distributed coordination service is Zookeeper. This way, all components work together without conflict.
Role:
- Cluster Coordination: Zookeeper is the heartbeat of the cluster, taking care of the cluster’s state by ensuring all nodes are in sync.
- Master Election: The Zookeeper also takes care of that if the HBase Master fails, and it helps elect a new HBase Master.
- RegionServer Tracking: Zookeeper keeps a live list of RegionServers so the system knows which active servers are available.
4. Hadoop Distributed File System
Data is stored in the HBase by relying on HDFS. HBase uses HDFS for its storage layer because HDFS is a distributed file system capable of handling large volumes of data.
Features:
- Data Redundancy: Data durability is guaranteed in HDFS (especially in failed hardware) because it replicates data on multiple nodes.
- Fast Recovery: Writing to replicas makes HDFS provide fast recovery in node failure by reading from replicas.
- Append Operations: In HBase, we support appending data in HDFS to keep incremental writes.
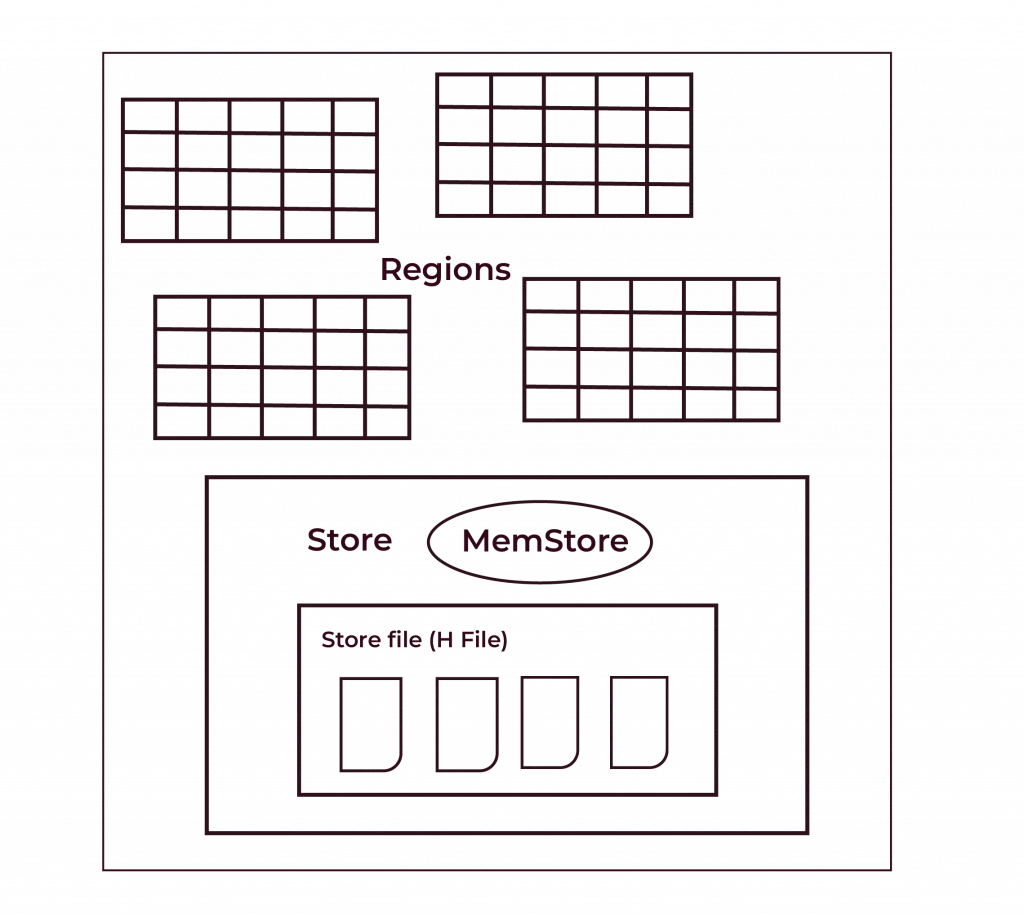
5. MemStore and StoreFiles
These two components are the most important regarding how HBase deals with its RAM and disk data.
- MemStore: This is a temporary store for HBase for holding data in memory and only writing it to disk later. It can write fast, storing its StoreFiles later on disk.
- StoreFiles: The flushed data is stored in HDFS files. HBase checks these files when data is read to retrieve the required information.
Also Read: Top Big Data Analytics Tools
How HBase Ensures Efficient Data Storage and Retrieval
HBase employs several techniques and architectural optimizations to guarantee fast and reliable data handling:
Underneath that, HBase optimizes which data to store and retrieve efficiently with the ability to work with massive datasets.
Log structured merge trees (LSM)
MemStore stores data in memory before writing files to disk, reducing random slow disk I/O. Once MemStore is filled, data is flushed to StoreFiles on HDFS in big chunks. It minimizes random writes and improves writes.
Data Compression
Data is compressed to save storage space and speed up operations to HBase. And as data sizes decrease, so does read and write time, improving overall performance.
Horizontal Scalability
Regions are evenly distributed across the RegionServers that manage them. As data grows, scalability becomes seamless as more servers are added to avoid one-server bottlenecks. It is simpler and cheaper than a closed system with limited servers.
Bloom Filters
By employing bloom filters, store files can store keys for which reading quickly checking to see if it exists in the store file is important. If the key is not found, data is retrieved faster.
Block Cache
Block Cache stores frequently accessed data, reduces disk access, and improves read operation speed by using the data stored in memory.

82.9%
of professionals don't believe their degree can help them get ahead at work.
Advantages of HBase Architecture
HBase is great because it has a good architecture for applications needing very large scale, is highly available, and can deal with large data.
1. Handling Sparse Data
The ability to store sparse data efficiently is one of the major strengths of HBase.
- Traditionally, relational databases impose a constraint that all rows in a dataset must have the same number of columns.
- HBase lets you store data in rows with different columns, so some rows have very few columns while others have many. This is great for any use cases that need a known data schema, e.g., for IoT or sensor data.
2. High Throughput
HBase is built for high throughput workloads and created for workloads that require lots of writing.
- It was optimized for write-heavy operations and is great for applications such as logging or real-time analytics.
- An architecture in HBase helps minimize write latency by using MemStore (in-memory data store) and flush data efficiently to HDFS. It can ingest large quantities of data at great speed and still handle that load so that performance stays high.
3. Fault Tolerance
However, HBase is fault tolerant compared to HDFS (Hadoop Distributed File System).
- Since HDFS replicates its data across multiple nodes, HBase is built on a similar idea that data will not be lost when a fraction of a node fails.
- HBase can quickly recover from a failed RegionServer or HBase Master by reassigning regions to other RegionServers. This ensures the system remains in service, available, and resilient, even with hardware or software failure.
Common Use Cases of HBase
HBase is widely used when high scalability, fast data access, and support for large, distributed datasets are critical. Here are some of the most common use cases:
1. Time-Series Data
Time-series data is well suited for HBase; it consists of large volumes of time-stamped information.
Examples: Sensor logs, stock prices, and weather data. These datasets are continuous, typically recorded over time, and contain data points.
HBase is suitable for handling data streams in real-time, as it can handle datasets with varying columns and has optimized was-heavy capabilities, which makes HB particularly suited to write-heavy applications. It enables the compact storage, retrieval, and analysis of time-based information.
2. Real-Time Analytics
Users often need immediate insight into live data, which HBase often powers real-time analytics platforms.
Examples: Live sensor feeds, current traffic data, social media activity, financial transactions, etc., on the dashboard.
The architecture of data structures enables the management of large volumes of constantly changing data. Therefore, it’s an ideal choice for applications where immediate data updates and speed of queries are expected.
3. IoT Applications
The Internet of Things includes data generated by devices like sensors, machines, and wearables. For the IoT platforms, HBase is a popular backend.
Examples: Smart homes, connected vehicles, health monitoring systems, and industrial IoT.
HBase was designed to store and manage unstructured, semi-semi-structured, inherently streamed IoT devices. Its horizontal scalability lets the number of connected devices and data points grow.
Challenges and Limitations
While HBase offers powerful features, it does come with its own set of challenges that need to be considered:
Latency with Small Writes
HBase functions best on massive bulk operations but occasionally lags on smaller writes. Batches of large amounts of data are optimal to write to HBase. For small writes, the system has to wait for enough data to fill up memory so that they can be pushed to disk, resulting in latency. It’s slower than you’d like for real-time applications processing small, frequent updates.
Complexity in Administration
However, managing an HBase cluster can be complex and requires much knowledge. HBase is an architecture that runs on distributed, and it must be tuned carefully, watching it constantly. Optimizing performance and troubleshooting issues can be manageable for teams with enough expertise to view the ‘big picture’ when monitoring the metrics.
Dependence on HDFS
HBase runs on top of HDFS for storage, and HDFS is reliable but has some performance issues. The storage and retrieval of the data are dependent on HDFS. A bottleneck can occur when HDFS is not configured properly. For example, slow data accessor performance can be tied to poor block replication or inefficient data distribution.
Conclusion
HBase is a great and reliable way to manage the data of huge dimensions in a distributed environment. However, its architecture with a master-slave model enables scaling and resilience, and its key components contribute to providing high performance. Today’s data-driven world comprises hundreds of applications driven around real-time analytics. On top of that, Hbase is indispensable, whether a real-time analytics platform or a backend for IoT applications. Knowing what HBase is, how it works, and what components make it up, organizations can fully leverage it to achieve the full potential of their big data initiatives. Learn more about HBase architecture and data science with the Accelerator Program in Business Analytics and Data Science With Nasscom by Hero Vired.
How is the architecture of HBase done?
What is HBase in NoSQL?
Why use HBase?
What is the structure of the HBase table?
Why is HBase faster?
Updated on December 5, 2024