Hashing is considered to be a fundamental concept in the oeuvre of algorithms and data structure, which offers increased efficiency for programmers in the retrieval and storage of data. To understand the functioning from its core, it is essential to look at some of the basic concepts related to it. In this article, you will find all the information that will help you to get a detailed understanding of hashing in the data structure. Here’s a table of content that will provide you with information on the flow of the content.
What is Hashing?
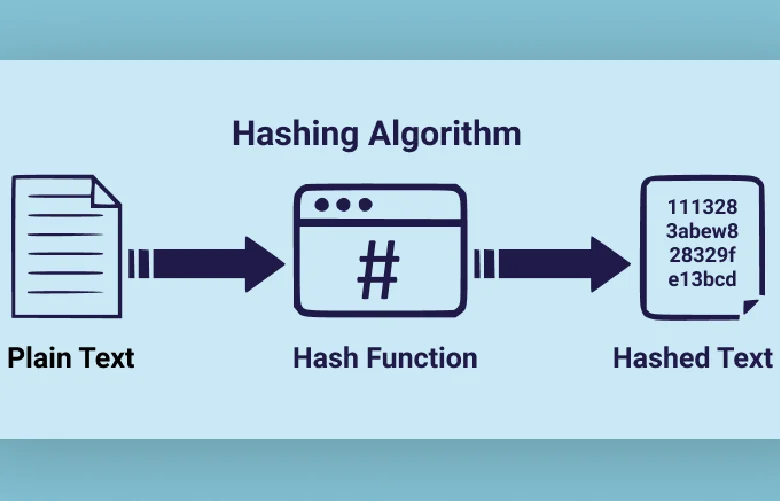
Hashing is considered to be a computer science technique that encompasses the use of a hash function to map an arbitrary data size to a fixed size value. The main purpose behind the designing of the hash function in hashing is to ensure that a unique hash code is generated with each input value. Therefore the aim of hashing in data structure is to offer quick and efficient access to data by cutting down on its searching time. Read thoroughly to know more about what is hashing in data structure, its various uses and types.

Get curriculum highlights, career paths, industry insights and accelerate your technology journey.
Download brochure
What is a Hash Table?
A hash table, also referred to as a hash map, is a data structure that is used for the storage and retrieval of quick data in an efficient manner. The hash table is typically based on the hashing concept, where the function of a hash is the conception of a key or identifier into an index of the array.

The constituent of a hash table is an array of slots, where each slot possesses the capability of storing a key-value pair. With the insertion of a new key-value pair in the hash table, the application of the hash function is completed to the key, which in turn determines the slot’s index in an array where the sorting of the pair should be done.
The use of hash tables can be seen in a plethora of applications involving network routers, caching, compilers, and database indexing. In modern computer science the hash table is an important tool that has greatly impacted the performance of applications and algorithms. Also read about stack in data structures.
Use cases of Hashing
Hashing in data structure entertains numerous uses. Some of the most common uses of hashing in data structure are as follows:
Data Retrieval
The retrieval of data in hashing includes the use of the hash function for the calculation of the hash table’s index where data is stored. For retrieving data, it is essential to obtain the hash code for which the hash function is applied to the key. Then the hash code is used for locating the slot in the hash table. In case data is contained in the slot, it will be retrieved and returned. But if the slot is empty, it represents that there is no key in the hash table.
Digital Signatures
An important application of hashing in cryptography is digital signatures. This is a mathematical technique that ensures the integrity and authenticity of various digital documents or messages.
What is Hashing in Data Structure?
What is hashing in data structure is a fundamental question that people often ask. Hashing in data structure is a technique which is used for the efficient retrieval and storage of data. The use of a hash function is involved here. A hash function is a kind of a mathematical algorithm that assists in mapping a large set of input data to a fixed size set of output data which is referred to as hash value or hash code. As the hash function offers a direct mapping between the hash table’s location and the key, quick and efficient retrieval and access of data can be secured. To know more about what is hashing in data structure, opting for a Business Analytics and Data Science would be beneficial.
How does Hashing in Data Structure Work?
Hashing in data structure works through the use of a hash function for the conversion of a given key to a hash code. This is then used as an index for the storage and retrieval of data in the hash table.
Types of Hashing in Data Structure
There are two types of hashing in data structure which are discussed below in detail:
Open Hashing
Open hashing is a technique where every element of the hash table acts as a pointer to a linked list of elements containing similar hash values. Open hashing in data structure proves efficient in handling an unlimited amount of elements and is simple for the purpose of implementation. However, it often results in a slower lookup time for finding an element]nt it needs to traverse the linked lists.
Closed hashing
This is also referred to as open addressing. In this technique, collisions are resolved by searching for the next available index in the hash table. Since closed hashing in data structure doesn’t require the need for linked lists, it results in quicker lookup times.
Look here to know about the Sorting in Data Structures.
What Is Hash Function?
After knowing what is hashing in data structure, it is essential to know its function. A hash function is actually a mathematical function that intakes a message or input to produce a fixed output, often referred to as digest or hash. The output is a unique representation of the given data, which means that if there is a small change in the input, it will lead to a completely different output.
The common use of hash functions in the oeuvre of computer science involves retrieval and storage of data, password storage, and message authentication, among many more.
Types of Hash functions
Division Method
This technique involves simple hashing, which is done by dividing the input by a prime number and taking the hash value as the remainder.
Mid Square Method
The functioning of this technique involves squaring the input and using the middle digits of the result as the hash value.
Folding Method
Here the input is divided into equal-sized chunks and added together, where the result is used as the hash value.
Multiplication Method
Here the input is multiplied by a constant value between 0 and 1 and then multiplied by the fractional part of the result by a table size for getting the hash value.
Basic Operations of Hashing in data structure?
The three basic operations of hashing in data structure are Insertion, deletion and search. The intersection involves the addition of a new key value to the hash table. The deletion involves the removal of a key-value pair from the hash table, and the search encompasses searching for the value and finding it associated with a given key in the hash table.
Read here to know about the Real-time application of data structures
What is a Hash Collision?
Hash collision takes place when the same hash value is produced by two or more differentiated inputs. This typically happens when the number of possible hash values is smaller than that of the total number of possible input values. This is, however, quite a common scenario.
Examples of Hashing in Data Structure
Some examples of hashing in data structure are:
- Hash table: This is a data structure that makes use of hash functions for the mapping of keys to values.
- Bloom Filter: This is a probabilistic structure of data that uses hashing for efficient testing concerning whether an element is a member of a set.
- Cryptographic hash function: This is a hash function which is developed to ensure high security and resistance to attacks and threats.
- Cuckoo hash table: This makes use of two arrays of buckets and two hash functions, where each element is hashed with both functions and if any bucket is free, it is inserted there. If both of them are occupied, one of the existing elements is taken out and placed with its alternate hash value.
Conclusion:
Hashing in data structure has impacted programmers and computer science users in a positive way and has offered various ways to make the system more efficient and quick.
FAQs
Yes, there are security implications of using hashing in data structure, particularly in the context of password storage or data encryption. For password storage, it is essential to use a strong and secure hash function along with the implementation of additional measures such as stretching and salting.
Some of the key features of hashing in data structure involve:
- Efficient and effective searching
- Fast insertion and deletion
- Resolution of any collision
- Providing enough flexibility
- Providing efficiency of space.
Some best practices for optimizing hashing performance are:
- Choose a suitable hash function
- Avoid hash collisions
- Optimize hash table size
- Use appropriate data structure
- Avoid unnecessary hashing
- Use parallelism
- Consider memory layout
To implement hashing in data structure in your programming projects successfully, you can follow these steps:
- Choose a suitable hash function
- Determine the hash table size
- Determine collision resolution method
- Define data structure
- Implement hash function
- Implement collision resolution
- Implement data structure operations
- Test and optimize
Hashing in data structure proves helpful in successfully storing and retrieving data as compared to other data structure techniques such as arrays or linked lists.
Updated on March 19, 2024







