
Initially, when the operating systems came into use, the input data was given to the CPU, and then the output was produced by the CPU according to the input. This method performed well until the number of processes increased as the next process was executed by the CPU only when the previous process had been completely executed. This led to a condition in which the CPU was held idle for a brief amount of time, which was a problem as the CPU was supposed to provide maximum utilization. To deal with this problem, the concept of Spooling was introduced.
What is Spooling?
The I/O management or buffer management technique known as spooling, also called Simultaneous Peripheral Operations Online (SPOOL), enables the temporary storage of input/output process data in secondary memory for later execution by the CPU, a device, or a program. These will remain in the secondary memory until a program or the system asks to use them for execution. The Spool method uses the FIFO (First In First Out) algorithm and moves forward in ascending order.
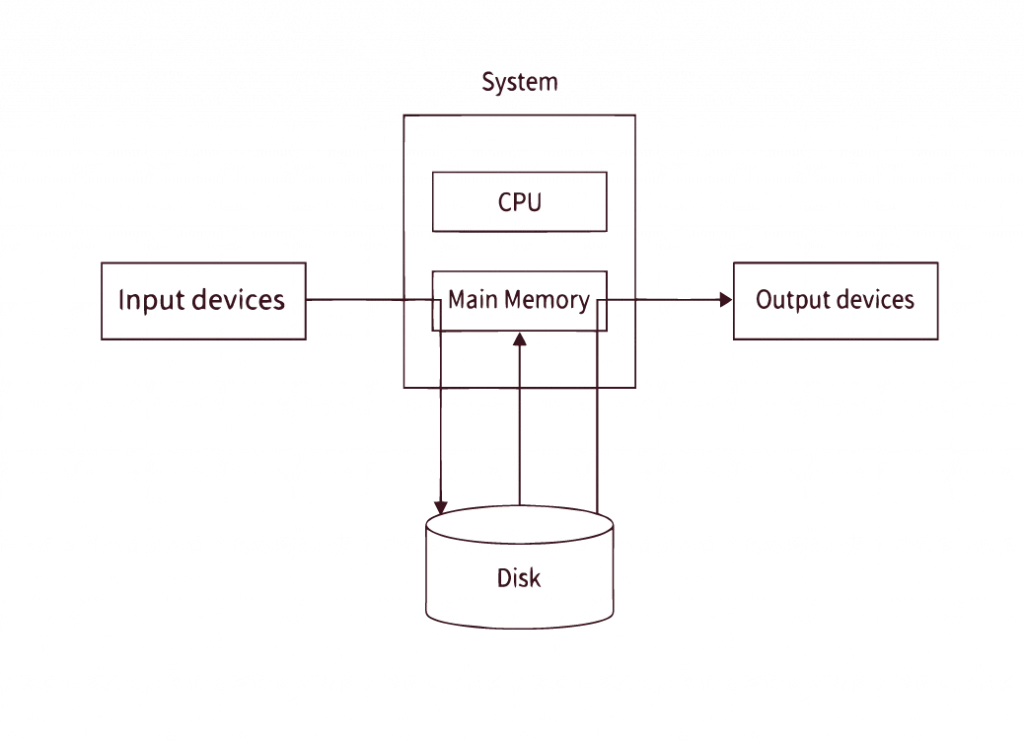
In comparison to the CPU and main memory I/O devices operate slower which means if a peripheral device executes instructions directly from the CPU the overall performance of the system will be affected because the I/O device that is attached to the CPU will take longer than the CPU which ultimately leads to poor CPU utilization.
The process of spooling involves moving data from the buffer or secondary memory to the main memory (RAM). This aids in the efficient use of the CPU since it communicates with main memory directly instead of through I/O devices, which processes data more quickly than a CPU.
Multiple input devices may simultaneously store data on the secondary memory, which is subsequently retrieved by the main memory and processed by the CPU. Because the main memory and CPU are both digital, they are very fast, which also makes fetching and executing data fast, preventing the CPU from being idle.
Also read: CPU Scheduling in Operating System

POSTGRADUATE PROGRAM IN
Multi Cloud Architecture & DevOps
Master cloud architecture, DevOps practices, and automation to build scalable, resilient systems.
Working of Spooling
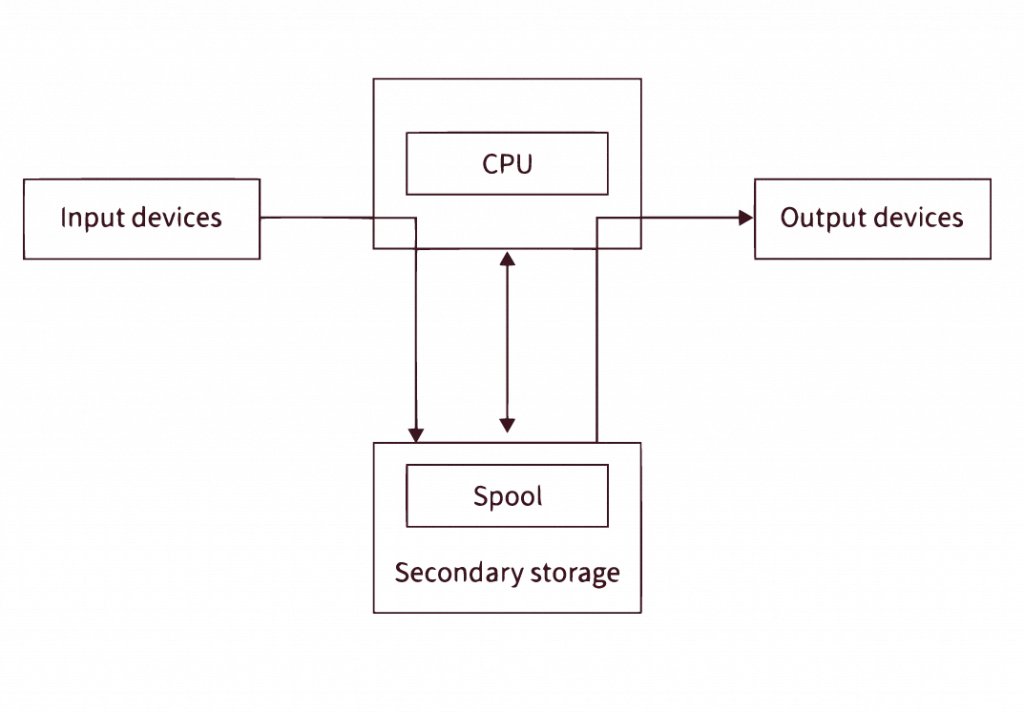
In order to understand the internal mechanism of Spooling let’s dive deep into its working. Spooling follows the following steps:
- Firstly, Spooling involves creating a memory space known as Spool. Then the space is filled with the data and tasks sent by the I/O devices and its work is to hold them until the data and tasks are sent to the CPU to process.
- The CPU then Uses the newly created secondary memory to interact with the main memory i.e the RAM while spooling. Then whenever the data in the I/O devices is ready to be transferred it is sent into the RAM.
- One of the benefits of spooling is that jobs are executed in the First In First Out (FIFO) order within the Spool buffer. Spooling process takes the entire secondary memory as the buffer which stores the jobs and data for the operations.
- In the traditional I/O operations processing we can see there is a higher CPU utilization. The CPU and main memory are digital thus operate quickly while the I/O devices are comparatively slower. In order to create a Spool all input devices send data to the secondary memory. From there, the tasks are moved into the main memory. The CPU then proceeds to execute each of them individually.
- The output produced is then moved into the main memory and then into the secondary memory, following the task execution of the CPU. The relevant output devices receive this output after that.
Advantages and Disadvantages of Spooling
Advantages:
- With the help of Spooling users can work with multiple I/O devices and their operations without hindering each other.
- It breaks the bridge between the CPU and the devices which negates the need of communication which slows down the working speed.
- With the help of spooling the CPU is kept engaged most of the time which reduces the need to become idle and goes into that state when required.
- The programs under spooling function within the CPU’s speed and the devices work at their designated speed.
Disadvantages:
- Spooling requires a certain amount of storage which is determined by the input devices attached to the CPU.
- As we know Spool creates a secondary storage on the disk and on increase of the operations the disk traffic increases and slows down the disk.
Applications of Spooling
There are several different scenarios where the concept of spooling in the operating system is used. Let’s discuss some of the scenarios:
- Usually Operating Systems use the spooling technique to maintain the spool in which the operations are stored and these operations remain in the storage until the system is ready to process them one by one.
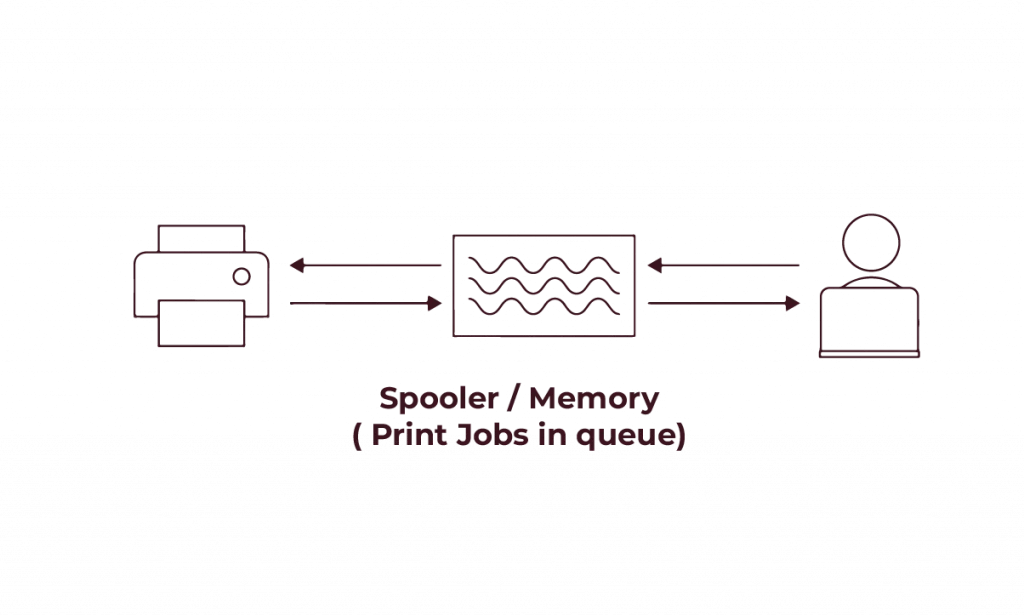
- For example in the device Printer the documents are stored in a spool which is also called the printer spooler. The spooling process then fetches those documents as soon as the printer is ready to print.
- At times overlapping among operations can be seen when multiple operations and devices are running within the CPU, spooling at these times comes in handy and continues to process the tasks accordingly.
- Spooling technique is used at many places for example to deliver Emails. As the mail is delivered by the Mail Transfer Agent (MTA) and stored in a temporary storage area which will be picked up by the Mail User Agent (MA).

82.9%
of professionals don't believe their degree can help them get ahead at work.
Difference Between Spooling and Buffering
| Parameters | Spooling | Buffering |
| Definition | Spooling which stands for Simultaneous Peripheral Operation Online (SPOOL) is a technique that temporarily stores data from input/output processes in secondary memory. This data is placed into a working area where it can be accessed and processed by the CPU when resources are available. | Buffering is a technique that temporarily stores data in a small area of memory called a buffer. This process helps to match the speed of data processing between the sender and receiver, ensuring smooth data flow. |
| Resource requirement | Spooling requires less resource management in the spooling process since multiple resources are used to handle various tasks in a given operation. | Similarly Buffering also requires less resources as one buffer is required for managing one operation. |
| Implementation | Spooling overlaps the input and output of multiple operations with their computation. | Buffering only overlaps the input and output of the same operation with its computation. |
| Efficiency | Spooling is considered more efficient when it comes to handling operations. | While buffering is comparatively less efficient then spooling. |
| Size on Memory | In spooling the complete secondary memory is considered as a large buffer. | While in Buffering a small part of the main memory is taken as a buffer. |
| Processing | Spooling supports remote processing where the spooler notifies the remote site whenever a process has completed its execution. | Buffering fundamentally does not support the remote processing technique. |
Conclusion
In operating systems, spooling is essential for maximizing resource use and improving system performance. Spooling facilitates continuous data transfer between devices and programs, allowing for seamless multitasking and increasing total system throughput by effectively handling input/output activities. Comprehending the principles and uses of spooling is essential to realizing its importance in contemporary computing settings. Spooling is a fundamental idea in the ever-evolving field of technology, greatly enhancing the efficacy and efficiency of operating systems.
What is spooling in printing?
What do you mean by spooling and buffering?
What is a spooler on a computer?
What is a spooling operating system?
Updated on October 10, 2024