
Ever worked with a large amount of data where you needed sorting but didn’t know which sorting method would be quicker? Or perhaps you’re trying to create code that’s more memory-efficient without using too much? That’s where Quick Sort in C comes in.
Quick Sort is one of the fastest sorting algorithms out there, often preferred by developers when speed and efficiency matter. It’s great because it uses a clever divide-and-conquer strategy, allowing us to break down large problems into smaller, manageable parts. The niceness about Quick Sort? It doesn’t require additional memory to sort the array. If anybody works with really limited resources, this is a big plus.
It may prove to be the best tool in your toolbox that you have while C programming, so let’s take a closer look at exactly how Quick Sort works.
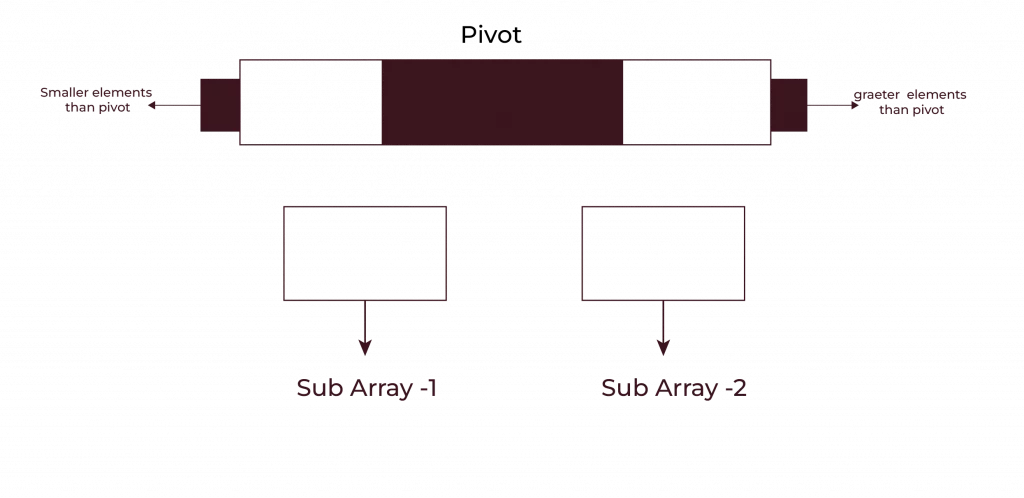
How Quick Sort Algorithm Works: An Overview of the Process
How does the Quick Sort work, exactly?
Picture a stack of books lying scattered on the floor. Some thick, some thin; to arrange them by height, placing the shortest first. Well, instead of comparing each book with all others, let’s select one of them as a “pivot” and then divide the books into two groups—those books shorter than the pivot and those books that are taller than the pivot. This is the basic idea behind Quick Sort.
Here’s how Quick Sort does it:
- Choose a Pivot Element: Visualise picking a book out of the pile. Any book, or for that matter any array element, will do for your pivot.
- Partition of the Array: Everything smaller than the pivot goes to the left, and everything greater goes to the right. Your pivot is now sitting in its sorted position.
- Recursion Time: Quick Sort, then magic its spell on the two smaller-sized arrays, repeating the process until each small chunk is fully sorted.
What seemed to be a pile of chaos only a few steps earlier is now neatly organised.

POSTGRADUATE PROGRAM IN
Multi Cloud Architecture & DevOps
Master cloud architecture, DevOps practices, and automation to build scalable, resilient systems.
Detailed Explanation of the Divide and Conquer Approach in Quick Sort
The divide-and-conquer strategy lies as the secret sauce behind Quick Sort’s speed.
Instead, we break it down into smaller pieces and work on smaller pieces instead of trying to work the whole array at once. With those smaller sections sorted, everything quickly comes back together to form a fully sorted array.
Example: Consider the array:
[34, 7, 23, 32, 5, 62]
We will follow each step of the partitioning process in this array.
Step-by-Step Example of Quick Sort in C
Initial Array:
[34, 7, 23, 32, 5, 62]
The first pivot chosen is the last element, 62.
Step 1: Choose Pivot and Compare
-
- Pivot: 62
- Compare each element with the pivot:
- 34 < 62 (no change)
- 7 < 62 (no change)
- 23 < 62 (no change)
- 32 < 62 (no change)
- 5 < 62 (no change)
Since every element is smaller than 62, no swaps are needed. The array remains:
[34, 7, 23, 32, 5, 62]
The pivot 62 is placed in its correct position, and no changes are made to the rest of the array.
Step 2: Partition Left Subarray
Now, we focus on the left subarray:
[34, 7, 23, 32, 5]
Choose the last element, 5, as the new pivot.
- Step 1: Choose Pivot and Compare
-
- Pivot: 5
- Compare each element with 5:
- 34 > 5
- 7 > 5
- 23 > 5
- 32 > 5
Since all elements are larger than 5, it is moved to the front, and the array becomes:
[5, 7, 23, 32, 34, 62]
Now, 5 is in its correct place.
Step 3: Recursively Sort Right Subarray ([7, 23, 32, 34])
We now move to the right subarray and repeat the process. Choose 34 as the pivot.
- Step 1: Compare with Pivot
-
- Pivot: 34
- Compare each element with 34:
- 7 < 34 (no change)
- 23 < 34 (no change)
- 32 < 34 (no change)
Since all elements are smaller than 34, no swaps are needed. The array remains:
[5, 7, 23, 32, 34, 62]
Step 4: Recursively Sort Left Subarray ([7, 23, 32])
Now, for the subarray [7, 23, 32], we choose 32 as the pivot.
- Step 1: Compare with Pivot
-
- Pivot: 32
- Compare each element:
- 7 < 32 (no change)
- 23 < 32 (no change)
The array remains unchanged:
[5, 7, 23, 32, 34, 62]
Step 5: Recursively Sort Left Subarray ([7, 23])
Finally, the subarray [7, 23] is sorted using 23 as the pivot.
- Step 1: Compare with Pivot
-
- Pivot: 23
- 7 < 23
No swaps are needed. The final sorted array is:
[5, 7, 23, 32, 34, 62]
Summary of Quick Sort Steps
| Step | Array State | Pivot | Left Subarray | Right Subarray |
| Start | [34, 7, 23, 32, 5, 62] | 62 | [34, 7, 23, 32, 5] | [] |
| Step 2 | [5, 7, 23, 32, 34, 62] | 5 | [] | [7, 23, 32, 34] |
| Step 3 | [5, 7, 23, 32, 34, 62] | 34 | [7, 23, 32] | [] |
| Step 4 | [5, 7, 23, 32, 34, 62] | 32 | [7, 23] | [] |
| Step 5 | [5, 7, 23, 32, 34, 62] (sorted) | 23 | [7] | [] |
Understanding the Role of the Pivot Element and Its Impact on Sorting
The pivot forms a core part of how Quick Sort works. The cleverness is that the choice of the pivot makes an enormous difference in performance for the algorithm.
Pick the wrong pivot, and Quick Sort goes off to a crawl, sometimes being no better than O(n²). But with a good choice of a pivot, this algorithm just flies through the process.
So, what makes for a good pivot?
- Random: A random choice from the array guarantees we do not have to worry about the worst case, which is when the chosen pivot is repeatedly the smallest or the largest element.
- Median: Sometimes, we go ahead and use the median element, which balances the array even better.
Consider a dataset like [10, 20, 30, 40, 50]. If we always select our pivot as the first element, then the partitioning turns out to be unbalanced. Every recursive call almost deals with the entire array, hence making the algorithm slower.
Pro tip: You should randomise the choice of pivot- so you’ll never see the worst-case scenario if you suspect that the array may already be sorted.
Example Code: Manual Implementation of Quick Sort in C
Here’s a simple C code for Quick Sort, where we let the user input their own values, making it more interactive:
#include <stdio.h>
// Function to swap two numbers
void swap(int* a, int* b) {
int temp = *a;
*a = *b;
*b = temp;
}
// Partition function to rearrange the array around the pivot
int partition(int arr[], int low, int high) {
int pivot = arr[high]; // Pivot is the last element
int i = (low - 1); // Index of the smaller element
for (int j = low; j <= high - 1; j++) {
// If current element is smaller than the pivot
if (arr[j] < pivot) {
i++; // Increment index of smaller element
swap(&arr[i], &arr[j]);
}
}
swap(&arr[i + 1], &arr[high]);
return (i + 1);
}
// Quick Sort function
void quickSort(int arr[], int low, int high) {
if (low < high) {
// Partition the array and get the pivot index
int pi = partition(arr, low, high);
// Recursively sort elements before and after the pivot
quickSort(arr, low, pi - 1);
quickSort(arr, pi + 1, high);
}
}
// Function to print the array
void printArray(int arr[], int size) {
for (int i = 0; i < size; i++)
printf("%d ", arr[i]);
printf("\n");
}
int main() {
int n;
printf("Enter the number of elements: ");
scanf("%d", &n);
int arr[n];
printf("Enter the elements: ");
for (int i = 0; i < n; i++) {
scanf("%d", &arr[i]);
}
quickSort(arr, 0, n - 1);
printf("Sorted array: ");
printArray(arr, n);
return 0;
}
Output:
Enter the number of elements: 7
Enter the elements: 18
45
10
7
35
80
12
Sorted array: 7 10 12 18 35 45 80
Alternative Approach: Using the C Library Function qsort()
Instead of manually implementing the Quick Sort algorithm, we can use the built-in qsort() function provided by the C standard library.
This function handles the sorting for us, but we need to provide a comparator function to specify
#include <stdio.h>
#include <stdlib.h>
// Comparator function to compare two integers
int compare(const void *a, const void *b) {
return (*(int*)a - *(int*)b);
}
int main() {
int n;
// Taking input for the number of elements in the array
printf("Enter the number of elements: ");
scanf("%d", &n);
int arr[n];
// Taking user input for array elements
printf("Enter the elements: ");
for (int i = 0; i < n; i++) {
scanf("%d", &arr[i]);
}
// Using qsort to sort the array
qsort(arr, n, sizeof(int), compare);
// Printing the sorted array
printf("Sorted array using qsort: ");
for (int i = 0; i < n; i++) {
printf("%d ", arr[i]);
}
return 0;
}
Output:
Enter the number of elements: 5
Enter the elements: 61
7
23
56
35
Sorted array using qsort: 7 23 35 56 61
The Partitioning Process: Rearranging the Array in Quick Sort
The partitioning process is where the real magic of Quick Sort in C happens.
So, let’s break it down.
We first select a pivot; usually, the last element is chosen, but any element will do.
Once we have our pivot, we rearrange the array so that everything smaller than the pivot is on the left of it and everything bigger on the right.
Think of this as sorting a group of friends by height.
The shortest is on the left; the tallest, on the right; and everybody else falls between those.
The pivot in such cases would serve as a reference as to where everybody should be. The partition function does this job of comparing each element with the pivot and swapping them into place.
Let’s take an example.
We have an array: [20, 10, 5, 15, 30] and pick 30 as the pivot.
After partitioning, the array shall look like this: [20, 10, 5, 15] 30 [].
Now, 30 is at its correct position, and we can use the same process for the left and right sub-parts.
Here’s the partition code for Quick Sort in C:
#include <stdio.h>
// Swap function
void swap(int* a, int* b) {
int temp = *a;
*a = *b;
*b = temp;
}
// Partition function
int partition(int arr[], int low, int high) {
int pivot = arr[high];
int i = (low - 1);
for (int j = low; j < high; j++) {
if (arr[j] < pivot) {
i++;
swap(&arr[i], &arr[j]);
}
}
swap(&arr[i + 1], &arr[high]);
return (i + 1);
}
// Quick Sort function
void quickSort(int arr[], int low, int high) {
if (low < high) {
int pi = partition(arr, low, high);
quickSort(arr, low, pi - 1); // Recursively sort left side
quickSort(arr, pi + 1, high); // Recursively sort right side
}
}
// Print function
void printArray(int arr[], int size) {
for (int i = 0; i < size; i++)
printf("%d ", arr[i]);
printf("\n");
}
int main() {
int n;
printf("Enter the number of elements: ");
scanf("%d", &n);
int arr[n];
printf("Enter the elements: ");
for (int i = 0; i < n; i++) {
scanf("%d", &arr[i]);
}
quickSort(arr, 0, n - 1);
printf("Sorted array: ");
printArray(arr, n);
return 0;
}
Output:
Enter the number of elements: 7
Enter the elements: 32
4
67
14
16
45
76
Sorted array: 4 14 16 32 45 67 76

82.9%
of professionals don't believe their degree can help them get ahead at work.
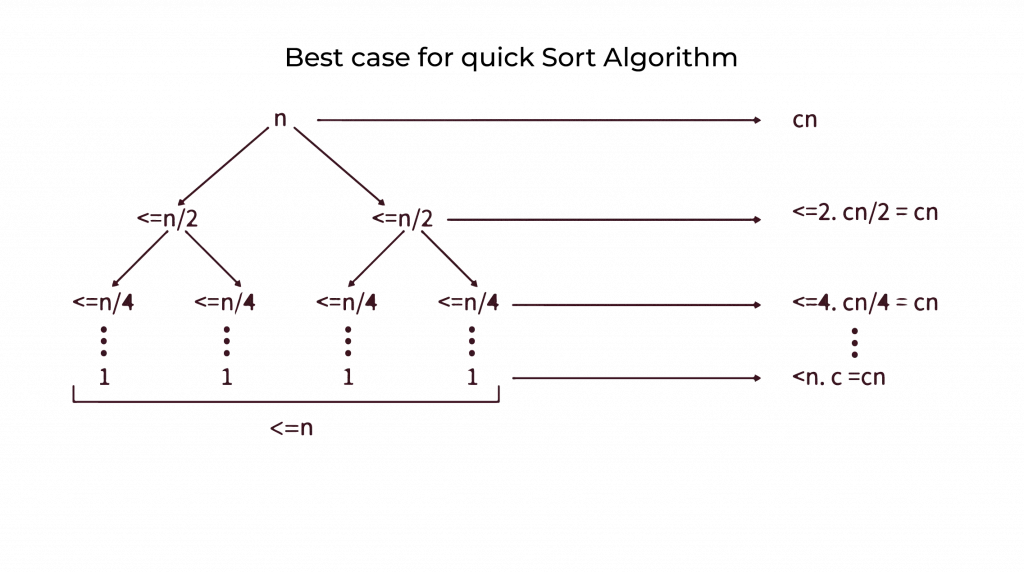
Time Complexity of Quick Sort: Analysing Best, Average, and Worst Cases
Every sorting algorithm has its ups and downs when it comes to time complexity. With Quick Sort in C, we usually get excellent performance, but it can slow down in some cases.
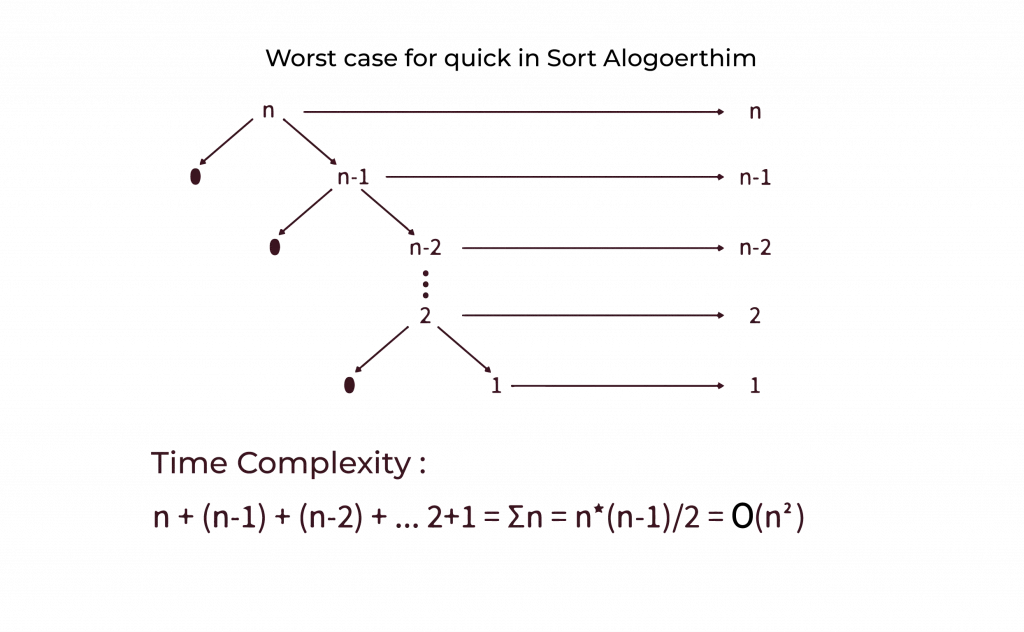
| Case | Time Complexity | Description |
| Best Case | O(n log n) | The pivot divides the array into two nearly equal halves. |
| Average Case | O(n log n) | Occurs with random data, making Quick Sort efficient for most real-world cases. |
| Worst Case | O(n²) | Happens when the pivot is poorly chosen (e.g., already sorted array with first or last element). |
Space Complexity: Memory Usage and Recursion Stack Overhead
Now, let’s talk about memory.
Quick Sort has a pretty good space complexity.
Quick Sort is an in-place sorting algorithm; additional memory is not needed to store a copy of the array. A major advantage of the Quick Sort algorithm over other algorithms, such as Merge Sort, is that it necessitates more memory.
But there’s one caveat: the recursion stack.
| Case | Space Complexity | Description |
| Best Case | O(log n) | The array is split into evenly sized subarrays, resulting in logarithmic recursion depth. |
| Worst Case | O(n) | Unbalanced partitions increase recursion depth to the size of the array. |
Comparing Quick Sort with Other Popular Sorting Algorithms in C
When sorting, Quick Sort is often compared to other algorithms.
But how does it stack up?
Let’s take a deeper look at the key differences where Quick Sort in C excels and where it doesn’t hold up quite as well.
Quick Sort vs Bubble Sort
Bubble Sort is easy to learn, but it is rather slow compared to other sorting algorithms.
This algorithm works by having a step-by-step examination of the array, comparing two neighbouring elements, and then swapping those that are out of order.
The above naive implementation of Bubble Sort has a time complexity of O(n²) in all cases; hence, for large lists, it is very inefficient.
On the contrary, Quick Sort performs much better on average and in the best cases with time complexity O(n log n).
If you have a large array to sort, Quick Sort will get done long before Bubble Sort does.
Quick Sort vs Merge Sort
Like Quick Sort, Merge Sort also follows the paradigm of divide-and-conquer. There is, however, an important difference.
Merge Sort divided the array into two equal parts, sorted, and then merged the two sorted parts. That means the worst-case time complexity is always O(n log n), but here is the catch. Merge Sort requires extra space for the temporary arrays during the merge.
Quick Sort does an in-place sort, requiring no additional memory. As such, Quick Sort has the obvious advantage when the memory is in short supply.
Also Read: goto Statement in C
Quick Sort vs Insertion Sort
Insertion Sort works by creating a sorted section of the array one element at a time.
For the best case, finding small inputs or nearly sorted lists, such as Insertion Sort, can be fairly effective at O(n).
However, when dealing with more average-sized and unsorted inputs, the worst-case time complexity of Insertion Sort is O(n²), which becomes very problematic.
That’s where Quick Sort shines again, with its generally better average-case performance.
Quick Sort vs Selection Sort
Selection Sort searches for the smallest (or largest) element of the array and puts it into its proper place.
It resembles Bubble Sort in its simplicity, but sharing this trait is also its use of O(n²) time complexity.
While this sort works fine for small datasets, Selection Sort stands no chance when working with larger arrays due to the efficiency provided by Quick Sort.
Practical Applications of Quick Sort Algorithm in Real-Life
So, when should we use Quick Sort in C?
Quick Sort is the go-to for scenarios where speed matters and memory use needs to stay low.
Here are some real-world applications:
- Database Sorting:
- Quick Sort is often used to sort large amounts of data in databases.
- Its efficiency and low memory use make it a great choice for this task.
- Search Engines:
- When search engines need to rank results quickly, Quick Sort is one of the algorithms used.
- The divide-and-conquer approach helps handle large datasets quickly.
- Systems with Limited Memory:
- Since Quick Sort works in-place, it’s ideal for systems with limited memory, such as embedded systems or mobile devices.
- Sorting in Web Applications:
- Web apps that rely on fast data sorting, like e-commerce platforms, can benefit from Quick Sort’s speed, especially when dealing with user data or search results.
- Data Visualisation Tools:
- Quick Sort helps in visualising large datasets, offering a way to process data quickly before displaying it in graphs, charts, or dashboards.
Advantages and Drawbacks of Using Quick Sort in C
Advantages of Quick Sort:
- In-place Sorting: Quick Sort doesn’t require extra memory, which makes it perfect for memory-limited environments.
- Fast for Large Datasets: Its O(n log n) average-case performance makes Quick Sort highly efficient for large arrays.
- Divide and Conquer: Breaking down the problem into smaller chunks reduces the time complexity, especially when the data is well-partitioned.
- Widely Used: Due to its efficiency, Quick Sort is the default choice in many programming libraries and systems.
Drawbacks of Quick Sort:
- Worst-case Time Complexity: If the pivot is poorly chosen (like always choosing the first or last element in an already sorted array), the time complexity can degrade to O(n²).
- Not Stable: Quick Sort doesn’t preserve the relative order of equal elements, which could be a deal-breaker for certain applications.
- Recursion Overhead: The recursive nature of Quick Sort can cause stack overflow on very large datasets if not handled properly (though this can be mitigated with the iterative version).
Also Read: Switch Statement in C
Conclusion
In the world of sorting algorithms, Quick Sort in C stands tall for a reason.
Its efficiency, especially for large datasets, makes it a go-to choice when speed and memory usage matter.
Its divide-and-conquer strategy ensures good performance with an average time complexity of O(n log n) and very low memory use because it sorts in place. Although its worst case can degrade to O(n²) performance if the pivot is not optimally chosen, Quick Sort continues to top many such lists for applications.
From sorting the database to processing the results after a search is used, Quick Sort is particularly useful for systems where resources are limited. Its efficiency and low memory usage make it especially valuable in such scenarios.
If done with proper selection of the pivot and mindful implementation, quick sort provides speed and flexibility and hence is one of the essential tools in the programmer’s toolkit.
Why does Quick Sort outperform other algorithms?
Is Quick Sort stable?
Can Quick Sort handle large datasets efficiently?
At what point should I not use Quick Sort?
What is the most considerable difference between recursive and iterative Quick Sort?
Updated on January 15, 2025