
In today’s time, managing the databases has become a great challenge. Concurrent transactions are being processed, which means the simultaneous execution of transactions over a shared database can lead to data integrity and data consistency problems. But what is the solution to this? One such solution is to use lock-based protocols. These protocols are rules that govern and control the access to data items that are being used in different transactions in the databases.
In this blog, we will delve deep into the lock-based protocols in DBMS and provide a practical approach on which lock-based protocol to use, when, and where. Along with this, we will also see different examples leveraging each lock-based protocol in DBMS.
What is a Lock?
A lock is defined as a variable associated with a data item that describes the item’s status concerning the possible operations that can be applied to it. A lock is part of concurrency control in DBMS and is categorised into two types:
- Binary locks- A binary lock is a type of lock having two states. These states are locked and unlocked. For example, if ‘A’ is a data item, we will refer to the current value of the lock associated with item A as a lock.
If lock (A) = 1, then time-A cannot be accessed.
Else If lock (A) = 10 then time-A can be accessed.
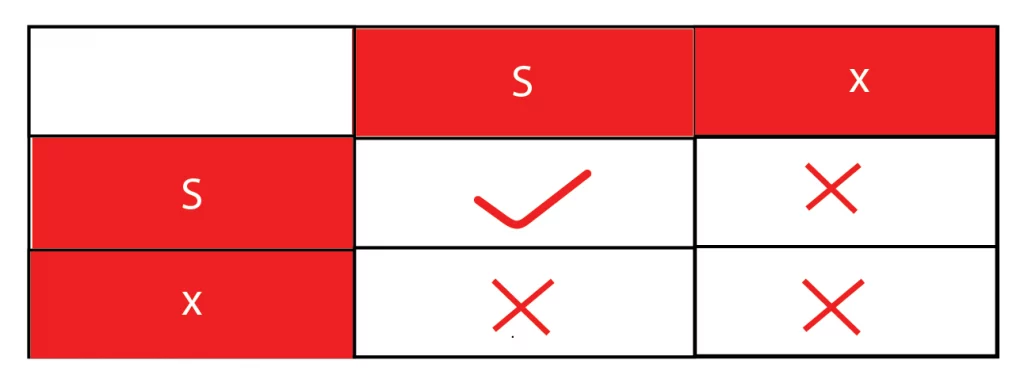
- Share/Exclusive locks- A shared lock is also known as an Exclusive lock or R/W lock. But they both are different. A shared lock (S-lock) can be used by multiple items, allowing them to read only operation whereas the exclusive lock (X-lock) can be held by one transaction at a time, allowing one to read and write the item.
Lock Compatibility Matrix:

POSTGRADUATE PROGRAM IN
Multi Cloud Architecture & DevOps
Master cloud architecture, DevOps practices, and automation to build scalable, resilient systems.
What is a Transaction?
A transaction is a set of changes that must all be made together. Transactions in DBMS are the sequence of operations performed as a single unit of work. Note that a transaction that changes the contents of the database must alter the database from one consistent database state to another. Transactions in DBMS must hold the four main key properties known as ACID properties:
- Atomicity (A)- A transaction is said to be atomic if a translation always executes its actions in one step or does not execute any actions at all.
- Consistency (C)- This means that a transaction must preserve the consistency of a database after its execution. The prior stable state or a new stable state must be preserved.
- Isolation (I)- This means that the data used during the execution of a translation cannot be used by a second transaction until the first execution is completed.
- Durability (D)- This means that if a transaction is committed, the changes are permanent.
What is Concurrency Control?
Concurrency control in DBMS is the management of concurrent operations running in the database without any interference. To allow multiple transactions to be run simultaneously without conflict, ensure that you are using the protocols so that you can ensure data integrity and data consistency in your database. Concurrency control can be managed using lock-based protocols.
Concurrency Control Algorithms
To achieve concurrency control, we have two algorithms that can help achieve concurrency control in the database transactions. These algorithms are:
- Pessimistic Approach
A pessimistic approach is one in which the transaction is delayed if they conflict with each other at some point of time during the transaction process.
A pessimistic approach commonly has two locking protocols:
- Two-phase locking protocol
- Timestamp ordering protocol
- Optimistic Approach
An optimistic approach is one that is based on an assumption that conflicts with the operation of reading and writing on a database. It is better to run the transactions to completion and to check for conflict only before they commit.
So, as we have the complete prerequisite for learning the lock-based protocols, we can now proceed further.
What are Lock-Based protocols?
The lock-based protocol is a mechanism in which there is a use of locks for controlling the access to data items in transactions. These protocols ensure the read/write or access to data items is restricted and is allowed to unlock to those having proper access. The lock-based protocol prevents conflicting operations from occurring simultaneously. It leads to data integrity and consistency in the database transactions.
Let’s now understand the different types of lock-based protocols in concurrency control and see how they differ from each other.

82.9%
of professionals don't believe their degree can help them get ahead at work.
Types of Lock-based protocols?
In concurrency, there are various locking protocols to ensure concurrency control in transactions in DBMS. Let’s discuss each of them one by one:
1. Simplistic Lock Protocol
A Simplistic lock protocol is one in which the transactions must obtain a lock. This is to ensure that transactions do not read or write on the data items before acquiring the lock. Once the transaction is completed, all locks are then released.
2. Pre-claiming Lock Protocol
A pre-claiming lock protocol is a protocol in which the transactions must pre-declare the list of data items that they are going to access in the future or need currently. Here, all locks on the data items are acquired before the transaction begins in its operation. However, this protocol has some limitations that will lead to inefficiency and low utilisation of resources.
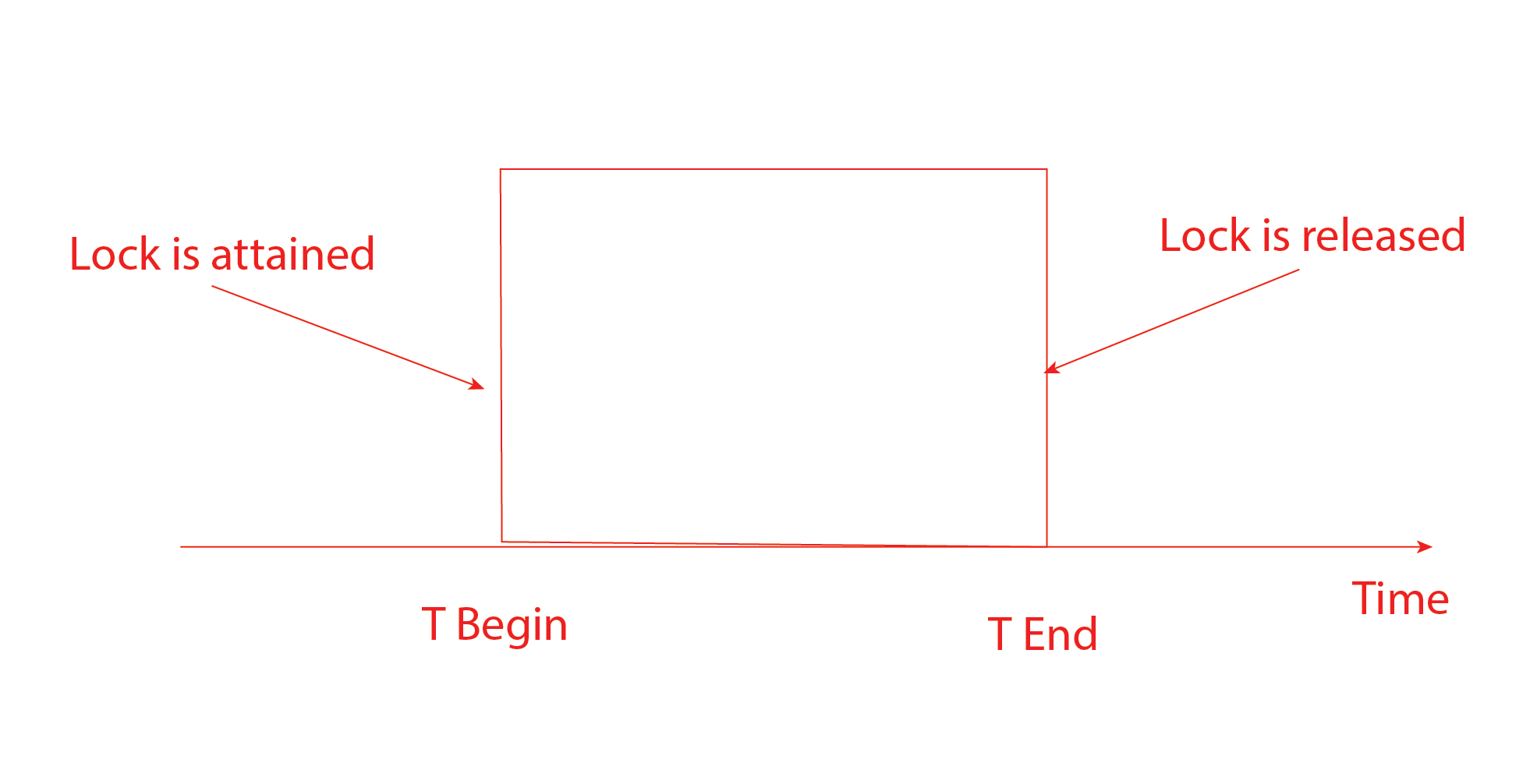
3. Two-phase locking (2PL) protocol
A two-phase locking protocol uses the two types of phases. The two phases are the Growing phase and the Shrinking phase. Using 2PL also ensures serializability in the transactions, which means the transactions are executed in a serial order. For example, say if their multiple locking operations precede the first unlock operation in the transaction the transaction follows the two-phase locking protocol.
Phase 1: Growing Phase, which is the phase in which all the locks are requested.
Phase 2: Shrinking Phase, which is one in which all locks are released.
Example:
Let’s see an example of a two-phase locking protocol. Let’s consider three transactions: T1, T2, and T3. We have two data items, A and B. Consider the following table for more understanding:
| T1 | T2 | T3 |
| Lock A | – | Lock A |
| Read A | Lock B | – |
| Lock B | – | Write A |
| Read B | Write B | – |
| Unlock A | Unlock B | – |
| Unlock B | – | – |
| – | – | Unlock A |
In the above example, you can see that the T1 transaction locks the data items A and B in the first call. T2 transaction locks the data B, and T3 transaction locks the data item A.
- Transaction T1 first proceeds by locking data item A, then reading data item A, followed by locking B, reading B, and finally unlocking both A and B data items.
- Transaction T2 locks data item B, writes to B, and then unlocks B.
- Transaction T3 locks data item A writes to A and then unlocks A.
As per the 2PL, If T1 locks the data items A and B, T2 and T3 must wait until T1 releases the locks. T1 enters the growing phase while obtaining locks and the shrinking phase while releasing them. Doing all of this will make sure that T1’s operations are isolated and consistent with T2 and T3’s operations.
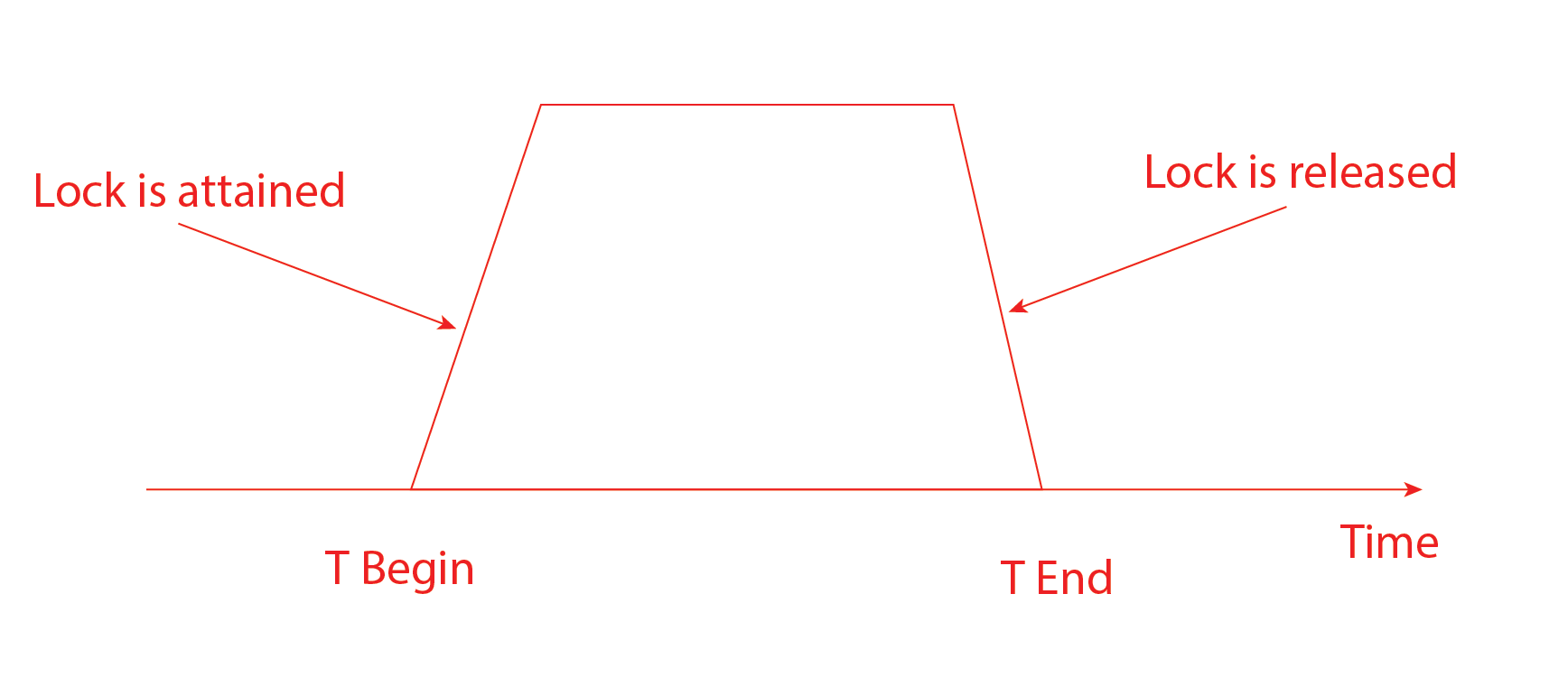
Rules for Two-Phase locking:
- No two transactions can have conflicting locks.
- No unlock operation can precede a lock operation in the same transaction.
- No data is affected until all locks are obtained.
Limitations of 2PL:
Deadlock, Cascading rollback, and locking overhead are the three major limitations of 2PL. Let’s see them in detail:
- Deadlock- It is a situation where transactions (T1, T2, etc) are waiting indefinitely for locks held by each other. A circular dependency will be created in a situation where the transactions hold locks on resources and wait for other resources that are held by different transactions, so this needs to be avoided.
- Cascading rollback- It is a phenomenon in which a single transaction failure leads to a series of transaction rollbacks.
- Locking overhead- The overhead associated with acquiring and releasing locks can impact the overall system performance in times when there is a need for high conflict for resources in the transaction.
4. Strict Two-Phase Locking (Strict 2PL) Protocol
A strict two-phase locking (Strict 2PL) is a protocol that requires not only the locking being in two phases but also all exclusive mode locks taken by a transaction must be held until that transaction commits. This will ensure that any data written by an uncommitted transaction is locked in exclusive mode until the transaction is committed, which will prevent any other transaction from reading the data items.
Limitations of Strict 2PL:
- Increased lock hold time
- Lead to Deadlock
- Improper resource utilisation
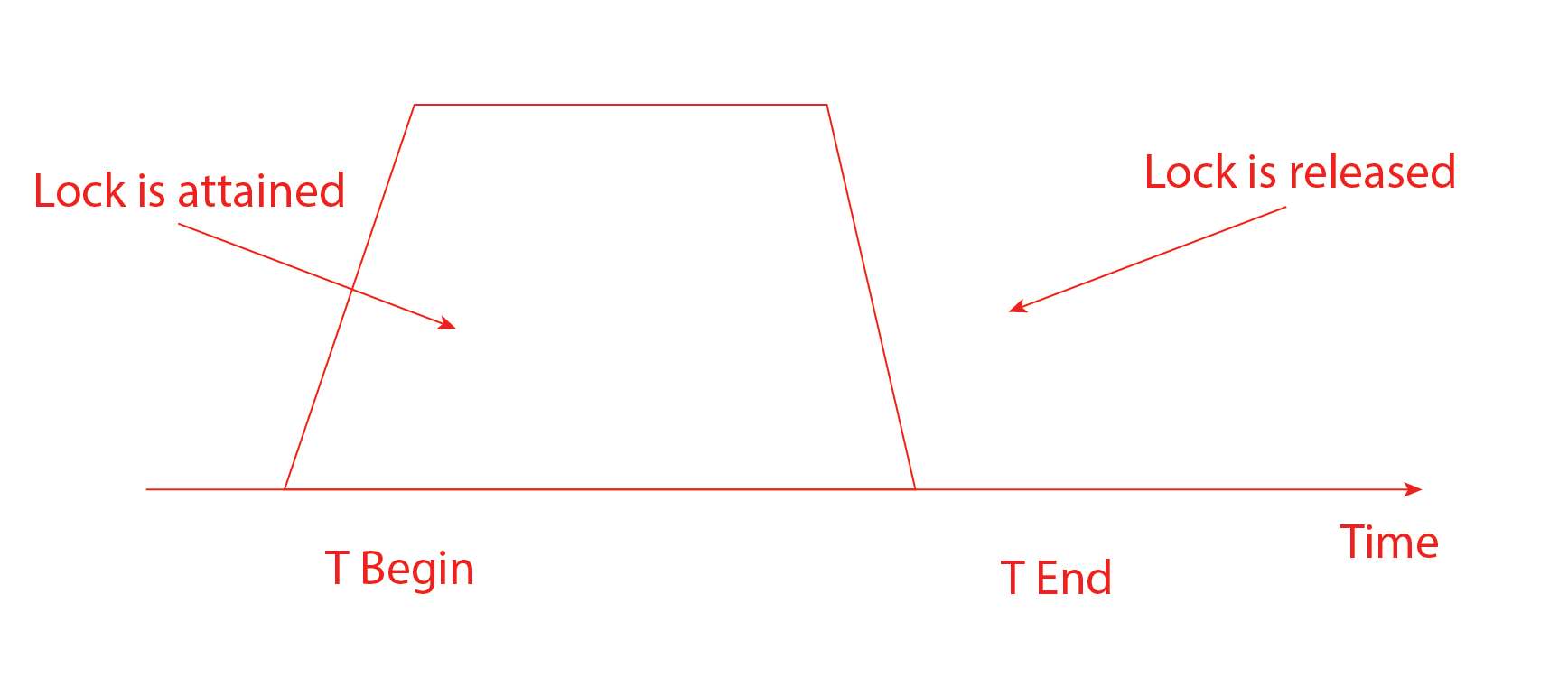
5. Rigorous Two-Phase Locking Protocol
A rigorous two-phase locking protocol is one in which all locks, including shared and exclusive, are held until the transaction is committed. It can be easily verified with this protocol about the serializability of transactions to check their order of commit.
Limitations of Rigorous 2PL:
- Less scalability
- Over conservative protocol
Deadlock and Starvation handling
A deadlock is a situation where two or more transactions are waiting for an indefinite period to acquire locks that are being held by another. As we know, the solution to inconsistency can lead to deadlocks. If we do not use the locking or unlocking of data items as soon as after reading/writing them, we may get inconsistent states.
For example, in a transaction T1, let’s say we have:
- Lock A
- Lock B (waiting for T2 to release lock B)
Another transaction T2 has:
- Lock B
- Lock A (waiting for T1 to release lock A)
Here, you see that the T1 and T2 are waiting for each other to release locks and will wait for an indefinite time, which will result in a deadlock.
Starvation is a situation when a transaction is unable to continue for an extended length of time due to persistent denials of essential resources such as locks by other transactions. Systems that assign priorities may experience this, with higher-priority transactions continuously delaying lower-priority ones. Many methods, such as the First-Come, First-Served (FCFS), SCFS, or ageing mechanisms that gradually enhance the priority of waiting transactions are used to prevent starvation in the databases.
Pros and Cons of Lock-based Protocols
While Lock-based protocols solve the problem of concurrency control and have other pros, they also give you some cons. Let’s discuss the pros and cons of lock-based protocols.
Pros:
- Consistency and Isolation: These protocols ensure that transactions run in isolation, limiting concurrent improvements and preserving data consistency by controlling access to common resources through locks.
- Deadlock Prevention: To prevent or address deadlock situations, a lot of lock-based protocols include deadlock prevention techniques like timeout mechanisms or deadlock detection algorithms.
- Compatibility Issues: Lock-based protocols are a sensible option for many applications since they are extensively used and compatible with the majority of DBMS implementations currently in use.
Cons:
- Deadlocks: Deadlocks can still happen despite anti-deadlock measures, which could result in transaction aborts and inconsistent data.
- Performance Overhead: When there is a lot of concurrency and competition for shared resources, acquiring and releasing locks may result in overhead.
- Inequity: Certain lock-based procedures might not ensure impartiality, hence causing transactions to stagnate or encounter infinite waiting time or delay.
Performance Considerations
Lock-based protocols can affect the performance of the database systems even though they give you the advantages of data consistency and isolation. Let’s see some performance consideration factors:
- Lock Granularity: Granules here means the size of the data items being locked. Although they need greater complexity, fine-grained locks like locking individual rows can increase concurrency. Coarse-grained locks, such as locking entire tables, minimise costs but reduce concurrency.
- Lock Overhead: Lock overhead means the computational and memory resources needed to manage the locks. The usage of lock management algorithms and data structures can effectively reduce the lock overhead.
- Transaction Throughput: They are the number of transactions processed per unit of time. As the throughput is increased, the effective usage of the lock contention and deadlocks can reduce throughput.
Conclusion
To ensure data consistency, data integrity, and concurrency control, the lock-based protocol is a great mechanism to achieve all of these things. In this blog, we learned about the lock-based protocol in DBMS. This guide has explored every detail you need to know for applying the lock-based protocols in your next transaction in DBMS, including what is a lock, a transaction, concurrency control, etc. Apart from this, it also explored the types of lock-based protocols, the situation of deadlock and starvation, and much more. We have learned about the Two-phase protocol (2PL) and its other types, including strict 2PL and rigorous 2PL, with examples.
In conclusion, lock-based protocols are a great mechanism to ensure data integrity, consistency, and control over concurrent transactions. If used and applied properly in database transactions, it can make your database system robust, scalable, and capable of handling concurrent data transactions.
What is a Two-Phase locking (2PL) protocol and its phases?
How can the lock-based protocols handle the deadlock?
Do we have any alternatives for lock-based protocols?
What is Multiple Granularity Locking in DBMS?
What is the difference between a Deadlock and Starvation in DBMS?
Updated on August 24, 2024