
Minimum Spanning Tree or MST is an important concept used in various designs of networks in the form of trees such as roadways, electricity grids, telecommunication, and much more. To design these networks, mainly there are two algorithms used in finding the MST i.e., Prims and Kruskal algorithms.
Although both algorithms have the same objective, they differ in how they go about choosing edges to build the minimum spanning tree. In this article, we will examine the specifics of both algorithms, discover how they differ, their implementation, some code examples, and much more.
What is Minimum Spanning Tree (MST)?
A minimal spanning tree (MST) is a subset of edges in a connected, edge-weighted graph that joins all of the vertices together without any cycles and with the least amount of total edge weight. It is a method for determining the most cost-effective way to join a set of vertices. The total weight of all the edges in the tree equals the cost of the spanning tree. Many spanning trees can exist in a graph. Also, there is no guarantee that a minimum spanning tree is unique.
Characteristics of MST
- MST contains all the vertices of a graph used to determine it.
- MST contains N-1 edges, where N is the number of vertices in a graph.
- There is minimal weight of MST for the sum of all edges.
Properties of Minimum Spanning Tree (MST)
- Uniqueness: With distinct edge weights, a graph has a unique MST. If there are multiple edges of the same weight, the graph may have multiple MSTs (though each is of equal total weight).
- Cut Property: For any cut in the graph, the minimum weight edge that crosses the cut is part of the MST.
- Number of Edges: An MST has N-1 edges, no matter how many edges the original graph has. This is because an MST spans all vertices in the graph, and adding any more edges would create a cycle. The graph would no longer be minimally connected.
- Total Weight: The total weight of the MST is merely the sum of the edge weights that were taken into the spanning tree. This total weight-MST is minimised relative to other spanning trees. It is minimised unexpectedly compared to all other trees.
- Cycle Property: No cycle in the graph can have its maximum weight edge included in the MST. Eliminating this edge will break the cycle by lowering the overall weight while maintaining the graph’s connectivity.
Use Cases for MST
- Network design: It is the process of arranging computer, telecom, and electrical grids in the most efficient way possible.
- Approximation algorithms: These are used to solve issues such as the Travelling Salesman Problem (TSP).
- Clustering: Similar data points are connected using minimal weight edges in data clustering, which makes use of MSTs.

POSTGRADUATE PROGRAM IN
Multi Cloud Architecture & DevOps
Master cloud architecture, DevOps practices, and automation to build scalable, resilient systems.
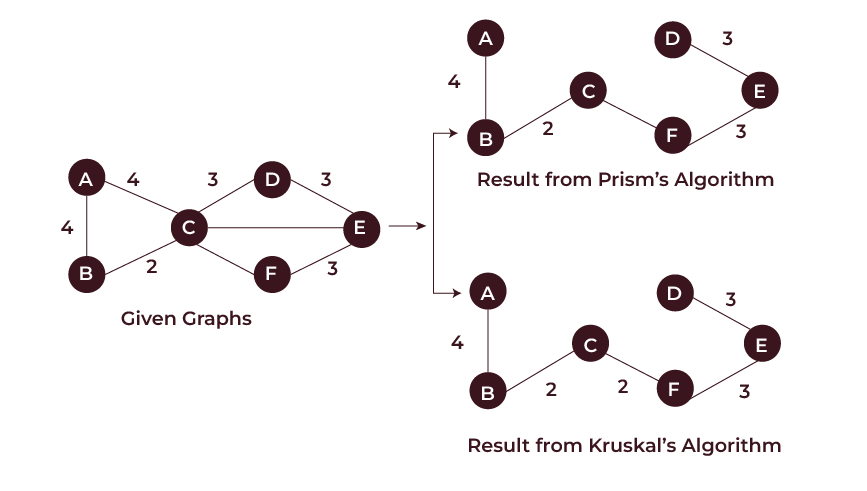
What is Prim’s Algorithm?
Prims Algorithm is a greedy method that begins with a single vertex and expands the spanning tree by adding edges one by one from the beginning, always selecting the lowest edge that results in the addition of a new vertex. Unlike an edge in Kruskal’s, we add a vertex to the growing spanning tree in Prim’s. As it belongs to the category of greedy algorithms, it locates the local optimum to locate a global optimum.
Also Read: Difference Between Algorithm and Flowchart
How Prim’s algorithm works
Prim’s algorithm is a greedy method that begins with a single vertex and grows the spanning tree by adding edges one by one, consistently selecting the lowest edge that results in the addition of a new vertex. Priority Queues are the ones that are mostly used in creating an MST using the prim’s algorithm. The steps for Prim’s algorithm are as follows:
- Initialization: Start at any random vertex.
- Edge Selection: Determine the vertex’s minimal weight edge that joins it to a new vertex.
- Add: add the edge to the MST.
- Repeat: Continue doing this until the MST contains every vertex, and a minimum spanning tree (MST).
Using the steps given above, you will generate a minimum spanning tree (MST). Let’s now look at the pseudocode for the Prim’s algorithm.
Pseudocode of Prim’s Algorithm
- Start with a starting vertex for the MST.
- Create a min-heap priority queue to store the edges according to weight.
- While the MST does not include all vertices:
- Take the priority queue’s least weight edge and extract it.
- Include the edge in the MST if it connects to a vertex that isn’t currently there.
- Add every vertex’s adjacent edge to the priority queue after it has been added.
- Until every vertex is in the MST, the process is repeated to get an MST.
Example
Let’s understand the working of the Prim’s algorithm using the below C++ code:
// imports
#include <iostream>
#include <vector>
#include <queue>
#include <climits>
using namespace std;
// defining Max
#define INF INT_MAX
// Creating a Pair
typedef pair<int, int> pii;
// defining prims function
void primMST(vector<vector<pii>>& graph, int V) {
vector<int> key(V, INF); // To store the minimum weights
vector<int> parent(V, -1); // To store the MST
vector<bool> inMST(V, false); // To track vertices included in MST
priority_queue<pii, vector<pii>, greater<pii>> pq; // Min-heap priority queue
int startVertex = 0;
key[startVertex] = 0;
pq.push({0, startVertex});
// run a while loop
while (!pq.empty()) {
int u = pq.top().second;
pq.pop();
if (inMST[u]) continue;
inMST[u] = true;
for (auto& edge : graph[u]) {
int v = edge.first;
int weight = edge.second;
if (!inMST[v] && key[v] > weight) {
key[v] = weight;
pq.push({key[v], v});
parent[v] = u;
}
}
}
// Printing the edge and weight
cout << "Edge \tWeight\n";
for (int i = 1; i < V; ++i)
cout << parent[i] << " - " << i << "\t" << key[i] << endl;
}
// Main function
int main() {
int V = 5;
vector<vector<pii>> graph(V);
// Add edges to the graph
graph[0].push_back({1, 2});
graph[0].push_back({3, 6});
graph[1].push_back({0, 2});
graph[1].push_back({2, 3});
graph[1].push_back({3, 8});
graph[2].push_back({1, 3});
graph[2].push_back({3, 7});
graph[2].push_back({4, 1});
graph[3].push_back({0, 6});
graph[3].push_back({1, 8});
graph[3].push_back({2, 7});
graph[3].push_back({4, 9});
graph[4].push_back({2, 1});
graph[4].push_back({3, 9});
primMST(graph, V);
return 0;
}
Output:
Edge Weight
0 - 1 2
1 - 2 3
0 - 3 6
2 - 4 1
Explanation:
- Adjacency List: An adjacency list with each element being a pair (neighbor_vertex, weight) is used to represent the graph.
- Priority Queue: A priority queue is used to select the edge with the smallest weight efficiently. The queue stores pairs (key_value, vertex) and sorts by the smallest key value.
- key keeps track of the minimum edge weight that connects each vertex to the MST.
- Key and Parent Arrays: The key array stores the minimum edge weights for each vertex. Initially, all values are set to INF (infinity) except for the first vertex (starting point), which is set to 0. The parent array keeps track of the vertex from which each vertex was added to the MST. This helps to print the MST edges.
- Main Loop: The algorithm extracts the vertex with the minimum key value from the priority queue.
- It checks all adjacent vertices and updates their key values if they can be reached with a smaller weight from the current vertex.
- The process repeats until the MST is constructed.
- Edge Printing: After building the MST, the code prints the edges included in the MST along with their weights.
What is Kruskal’s Algorithm?
Although it takes a different method, Kruskal’s Algorithm is likewise greedy. A linked weighted graph’s smallest spanning tree can be found using Kruskal’s Algorithm. To prevent cycles from forming, it adds edges to the MST and arranges all of the graph’s edges in a non-decreasing order.
It finds the subset of edges that can traverse every vertex in the graph. This method finds an optimal solution at each stage rather than a global optimum.
How Kruskal’s algorithm works
Kruskal’s algorithm is also a greedy algorithm that finds the local optimum for finding a global optimum. The steps for Kruskal’s algorithm are as follows:
- Sort: Sort each edge according to its weight in a non-decreasing order.
- Edge Selection: Start with a blank MST and from the sorted list, select the smallest edge.
- Add: Add the edge in the MST if it joins two distinct trees.
- Repeat: Continue doing this until the MST contains n-1 edges.
Using the steps given above, you will generate a minimum spanning tree (MST) using Kruskal’s algorithm. Let’s now look at the pseudocode for Kruskal’s algorithm.
Pseudocode of Kruskal’s Algorithm
- Based on their weights, arrange all edges in a non-decreasing order.
- Determine the vertex’s minimal weight edge that joins it to a new vertex.
- Iterate Over Sorted Edges:
- In the sorted edge list, for every edge:
- If the edge does not form a cycle (vertices are in different components), add it to the MST.
- Use the union-find algorithm to merge the components.
- Stop when the MST contains the N-1 edges, and repeat until the MST is complete.
Examples
// imports
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
// Edge structure
struct Edge {
int u, v, weight;
};
// compare function
bool compare(Edge a, Edge b) {
return a.weight < b.weight;
}
// Creating a class
class DisjointSet {
vector<int> parent, rank;
public:
DisjointSet(int n) {
parent.resize(n);
rank.resize(n, 0);
for (int i = 0; i < n; i++) parent[i] = i;
}
// Find function
int find(int u) {
if (parent[u] != u) parent[u] = find(parent[u]);
return parent[u];
}
// Union Sets function
void unionSets(int u, int v) {
int rootU = find(u);
int rootV = find(v);
if (rootU != rootV) {
if (rank[rootU] > rank[rootV])
parent[rootV] = rootU;
else if (rank[rootU] < rank[rootV])
parent[rootU] = rootV;
else {
parent[rootV] = rootU;
rank[rootU]++;
}
}
}
};
// Function for Kruskal's algorithm
void kruskalMST(vector<Edge>& edges, int V) {
sort(edges.begin(), edges.end(), compare); // Sort edges by weight
DisjointSet ds(V);
vector<Edge> mst;
for (Edge& edge : edges) {
if (ds.find(edge.u) != ds.find(edge.v)) {
mst.push_back(edge);
ds.unionSets(edge.u, edge.v);
}
}
// Print edge and weights
cout << "Edge \tWeight\n";
for (Edge& e : mst)
cout << e.u << " - " << e.v << "\t" << e.weight << endl;
}
// Main function
int main() {
int V = 5;
vector<Edge> edges = {
{0, 1, 2}, {0, 3, 6}, {1, 2, 3}, {1, 3, 8}, {2, 3, 7}, {2, 4, 1}, {3, 4, 9}
};
kruskalMST(edges, V);
return 0;
}
Output:
Edge Weight
2 - 4 1
0 - 1 2
1 - 2 3
0 - 3 6
Explanation:
- An edge list is used to represent the graph. The two endpoints (u and v) and the weight of each edge characterise it.
- Sorting the Edges: Before starting Kruskal’s algorithm, the edges are sorted in increasing order of weight using the sort function and a custom comparator (compareEdges). This ensures that we start by considering the smallest edge first.
- Disjoint-Set: A disjoint-set (also called union-find) is used to detect cycles efficiently. Each vertex is initially its parent.
- The find function determines the root of a vertex, and the unionSet function merges two sets if they belong to different components.
- Creating the MST:
- Every edge in the sorted list is iterated over by the algorithm.
- It determines if the two edge endpoints for each edge are in different sets or different components. If they do, the sets are combined and the edge is added to the MST.
- Until the MST contains exactly V-1 edges, this operation is repeated.
- Edge Printing: Once the MST is formed, the algorithm prints the edges included in the MST.
Applications of Prim’s and Kruskal’s Algorithms
Prim’s and Kruskal’s algorithms are used commonly in real-world and below are some of the applications of both algorithms:
Kruskal’s algorithm Kruskal is popular in computer science for finding the minimum spanning tree in a graph. The following are some of the applications of Kruskal’s algorithm:
- Network Design: The algorithm of Kruskal can be used to design networks at minimal costs.
- Image Segmentation: This is done by partitioning an image into multiple segments. To break down an image into its constituent parts, Kruskal’s algorithm can be implemented.
- Approximation Algorithms: The Travelling Salesman Problem and other optimization issues employ MST-based Kruskal’s algorithm.
Prim’s algorithm Prim’s is also popular in computer science for finding the minimum spanning tree in a graph. The following are some of the applications of Prim’s algorithm:
- Clustering: To group the related data points, hierarchical clustering algorithms use algorithms such as Prim’s.
- Approximation Algorithms: The Travelling Salesman Problem and other optimization issues employ MST-based Prim’s algorithm.
- Civil engineering: Cost-effective design of pipeline and road networks.

82.9%
of professionals don't believe their degree can help them get ahead at work.
Difference between Prim’s and Kruskal’s Algorithms
| Criteria | Prim’s Algorithm | Kruskal’s Algorithm |
| Approach | The prim’s algorithm grows the MST by expanding the tree to include the closest vertex. | Adds edges with weights increasing in order. |
| Initialization | It starts from a random or arbitrary vertex. | It starts with all vertices as separate trees (forest) |
| Edge Selection | It selects the edge with the least weight among the connected vertices. | It selects among all edges the edge with the least weight. |
| Graph Representation | It works well with priority queues built on heaps of adjacency matrices. | It requires an adjacency list or edge list. |
| Best use | It is best for dense graphs. | It is best used for sparse graphs. |
| Data structure | Here, the priority queue i.e., min-heap is used. | Here, a disjoint set is used to detect the cycle. |
| Cycle Detection | Here, cycle detection is not required. | Here, cycle detection is performed using the union find. |
| Use Case | It is best suitable for connected, undirected graphs. | It is best suitable for connected, undirected graphs. |
| Nature of algorithm | It is a type of greedy algorithm. | It is a type of greedy algorithm. |
| Time Complexity (using Heaps) | The time complexity for the Prim’s algorithm is O((V + E) log V). | The time complexity for Kruskal’s algorithm is O(E log E + E log V). |
| Minimum Weight Edge Selection | Here, always the nearest vertex is picked. | Here, always the smallest edge is picked. |
| Parallelism | It is challenging to parallelize in prim’s. | Parallelizing edge sorting and union procedures is easier in Kruskal’s. |
| Memory usage | There is increased memory for the priority queue. | Less memory is used if edges are externally sorted. |
Time Complexity Analysis
Understanding the time complexity is important as it shows which algorithm is efficient and how much time it takes to work on an input.
Prim’s Algorithm Prim’s Algorithm has a time complexity of O((V + E) log V), where V is the number of vertices and E is the number of edges. It is because each edge is only added to the priority queue once, and adding an edge to the priority queue takes logarithmic time.
Kruskal’s Algorithm Sorting takes up the most time in Kruskal’s method since the algorithm’s total time complexity is equal to the sum of the disjoint-set operations’ complexity. The overall complexity is O(E log E + E log V), which simplifies to O(E log E) as Kruskal’s algorithm time complexity.
Conclusion
Prim’s and Kruskal’s algorithms are two notable algorithms for computing a Minimum Spanning Tree of a given graph. In Prim’s algorithm, the MST is grown stepwise, by including more and more vertices, whereas in Kruskal’s algorithm, the edges are taken in non-descending number order, which makes them suitable for different types of graphs.
In real usage, however, which one should be used is often determined by the density of the graph and the application requirements. Intuiting their differences and knowing when to use each will help optimise the performance of MST-related tasks in some real-life situations.
How Many Edges Does a Minimum Spanning Tree Have?
What is the difference between Prim’s and Kruskal’s algorithms?
Does Prim’s or Kruskal’s algorithm work with negative weights?
Can Prim's algorithm have multiple solutions?
Do Prim and Kruskal give the same MST?
Updated on September 14, 2024