
Are you tired of making changes to your database and having to rewrite your applications each time?
Do you wish there was a way to modify your database without causing a ripple effect across your systems?
Data independence in DBMS addresses these exact concerns.
In a nutshell, data independence allows us to change the database schema at one level without impacting the schema at the next higher level.
This flexibility is crucial in maintaining and scaling our database systems efficiently.
Importance of Data Independence in Modern Database Management Systems
Why is data independence in DBMS so important? Here are some key reasons:
- Flexibility: We can make changes at one level without affecting the entire system.
- Scalability: As our database grows, data independence helps us manage changes smoothly.
- Maintenance: It simplifies the process of updating and maintaining the database.
Data independence is a cornerstone of modern DBMS architecture. It ensures that our databases remain adaptable and easy to manage.
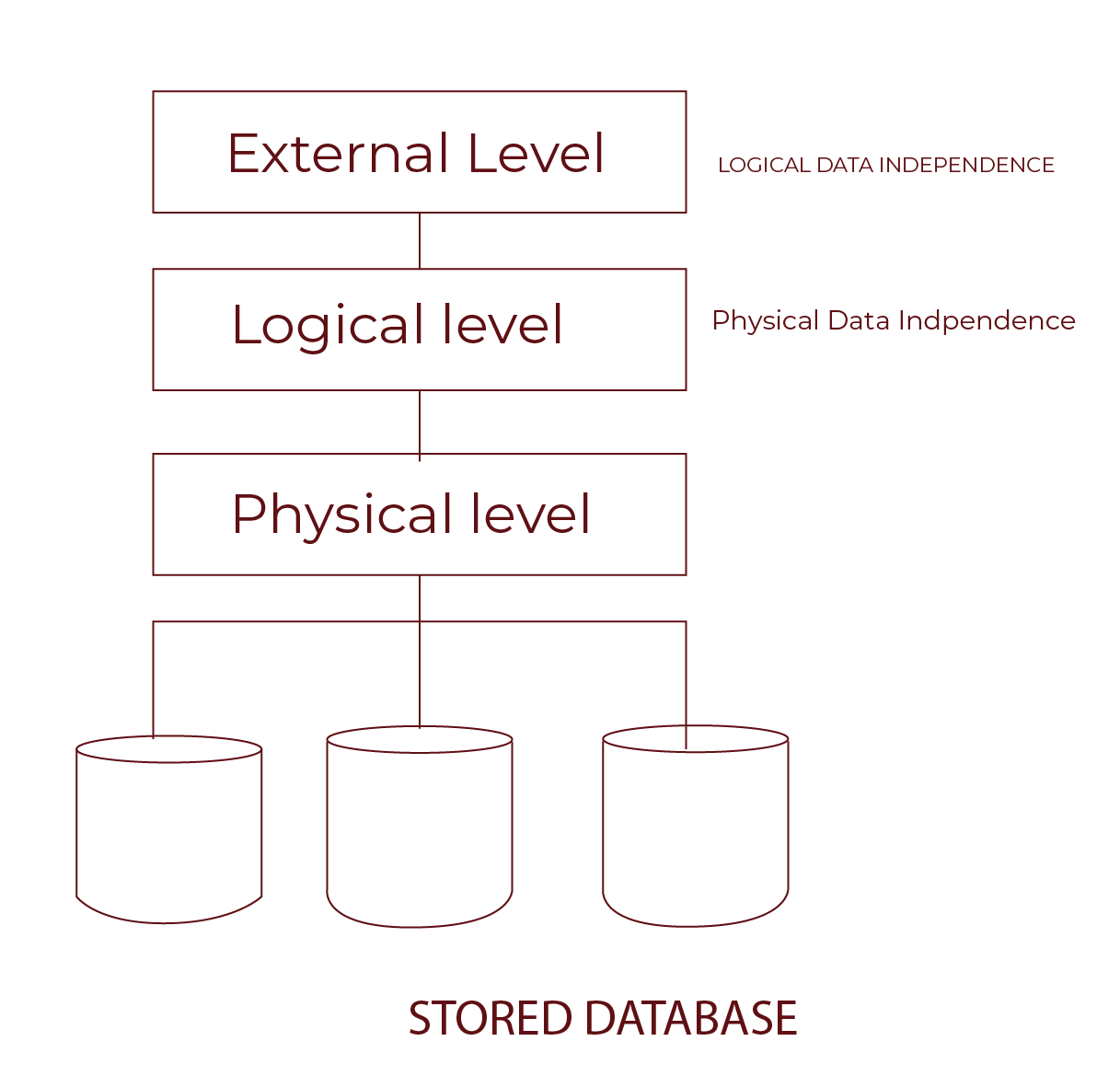
Now that we have understood the importance of data independence in DBMS let’s understand its types. We can divide it into two types:
- Logical Data Independence
- Physical Data Independence

POSTGRADUATE PROGRAM IN
Multi Cloud Architecture & DevOps
Master cloud architecture, DevOps practices, and automation to build scalable, resilient systems.
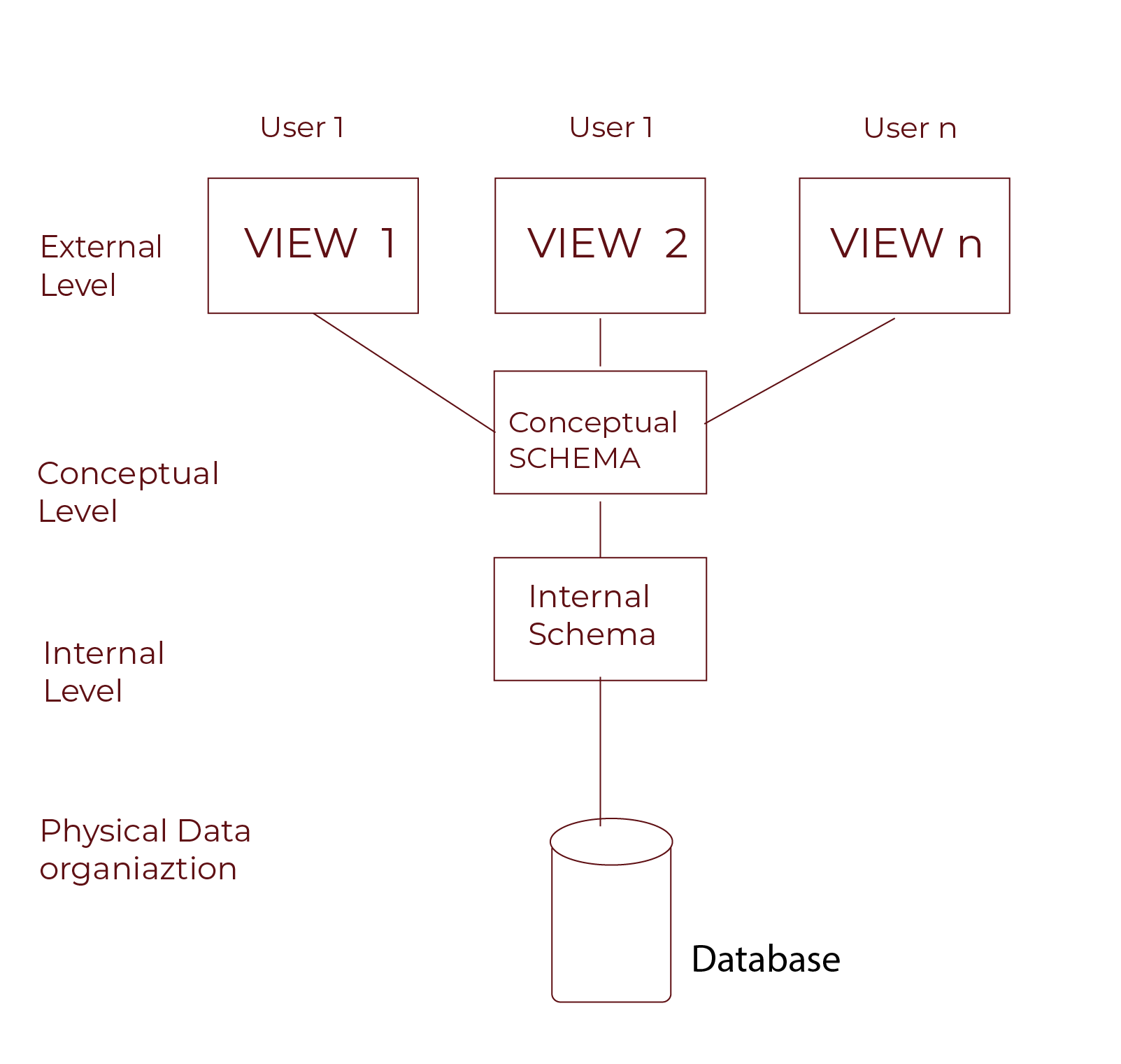
Three-Level Database Architecture and Its Relation to Data Independence
Data independence is part of the three-level database architecture. This architecture separates the database into three levels:
- Internal Level: How data is stored physically.
- Conceptual Level: What data is stored and its relationships.
- External Level: How users interact with the data.
The Internal Level deals with physical storage. Think of it as the basement of a building. Changes here might involve moving from hard drives to SSDs for faster performance.
The Conceptual Level is like the blueprint of a building. It shows what data is stored and how it relates. Changes here might include adding new tables or modifying relationships between data.
The External Level is what users see. It’s like the building’s lobby. Changes here might involve new views or interfaces for users to interact with the data.
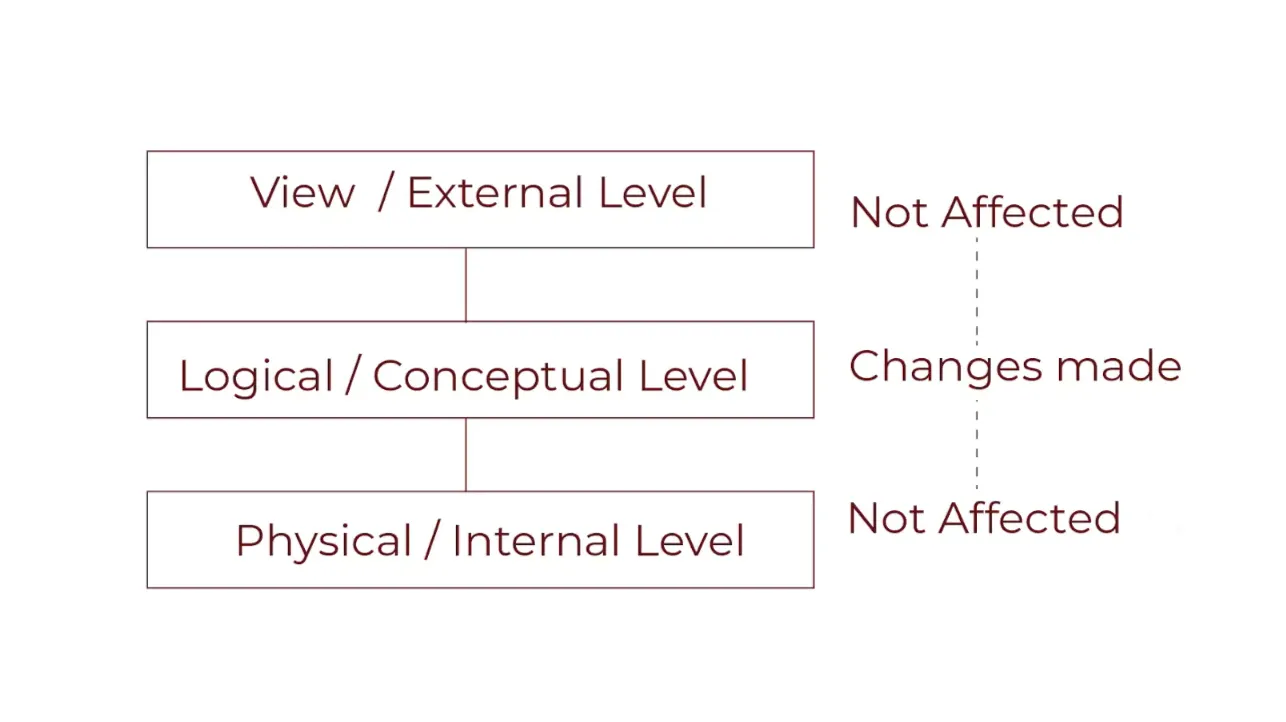
Detailed Explanation of Logical Data Independence in DBMS
Definition and Concept
Logical data independence means we can change the conceptual schema without altering the external schema. In simple terms, changes to how we organise data do not affect how users interact with it.
Practical Examples of Logical Data Independence
Let’s dive into some examples.
1. Adding a New Column to a Table
Suppose we have a Customer table and want to add an “email” column. With logical data independence, this change won’t affect the applications that use this table.
-- Adding a new column to the Customer table
ALTER TABLE Customer ADD email VARCHAR(255);
After adding the column, the applications using the Customer table can continue to function without any modifications.
2. Modifying Relationships Between Entities
Imagine splitting a Customer table into IndividualCustomer and BusinessCustomer tables. This structural change is managed without affecting the application logic.
-- Splitting Customer table into IndividualCustomer and BusinessCustomer
CREATE TABLE IndividualCustomer (
id INT PRIMARY KEY,
name VARCHAR(255),
email VARCHAR(255)
);
CREATE TABLE BusinessCustomer (
id INT PRIMARY KEY,
companyName VARCHAR(255),
contactEmail VARCHAR(255)
);
INSERT INTO IndividualCustomer (id, name, email)
SELECT id, name, email FROM Customer WHERE type = 'Individual';
INSERT INTO BusinessCustomer (id, companyName, contactEmail)
SELECT id, name, email FROM Customer WHERE type = 'Business';
This split does not require changes to the user interfaces that access customer data.
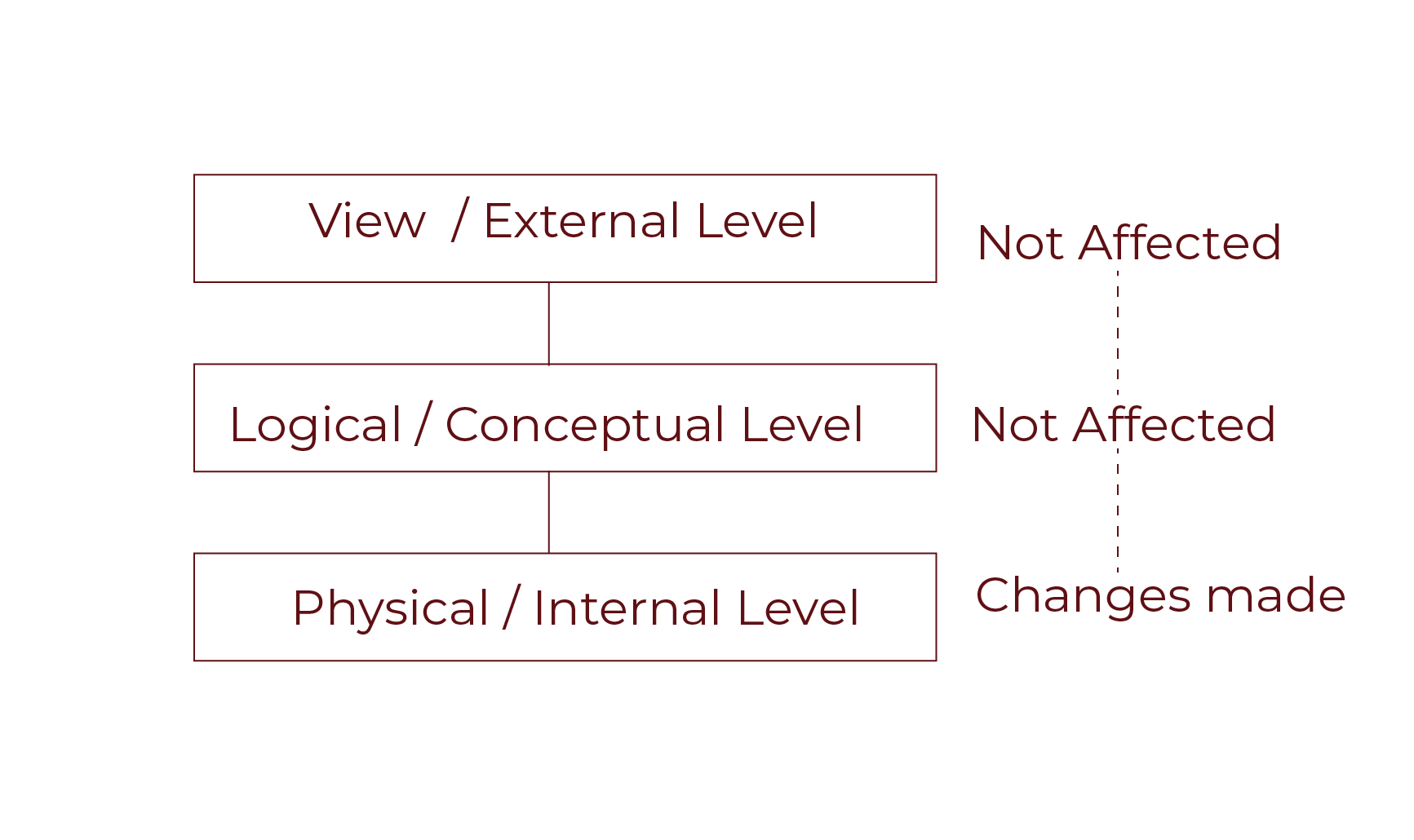
In-depth Look at Physical Data Independence in DBMS
Definition and Concept
Physical data independence allows us to change the internal schema without affecting the conceptual schema. This means modifications to storage structures or hardware do not impact how data is logically organised.
Practical Examples of Physical Data Independence
Here are some practical examples.
1. Changing Storage Location
If we need to move our database from one storage device to another, physical data independence ensures that these changes are seamless.
-- Moving the database files to a new location
ALTER DATABASE MyDatabase
MODIFY FILE (NAME = MyDatabaseData, FILENAME = 'D:\NewLocation\MyDatabase.mdf');
This move does not affect the logical structure of the database.
2. Implementing New Indexing Methods
Switching from B-tree indexing to hash indexing can enhance performance without altering the conceptual schema.
-- Creating a hash index
CREATE INDEX idx_hash ON Customer USING HASH (email);
The way data is stored changes, but the logical view remains the same.
Also Read: What is a Database Management System?

82.9%
of professionals don't believe their degree can help them get ahead at work.
Detailed Comparison Between Physical and Logical Data Independence
| Aspect | Physical Data Independence | Logical Data Independence |
| Definition | Ability to change the physical schema without affecting the logical schema. | Ability to change the conceptual schema without affecting the external schema. |
| Focus | Internal schema and storage mechanisms. | Conceptual schema and data structures. |
| Ease of Implementation | Easier to achieve. | Harder to achieve due to application dependencies. |
| Examples | – Changing storage devices (e.g., from HDD to SSD). | – Adding a new attribute to a table (e.g., adding “email” to “Customer” table). |
| – Upgrading indexing methods (e.g., switching from B-tree to hash indexing). | – Splitting an entity into two separate entities. | |
| Impact on Applications | Minimal impact as applications are not dependent on physical storage. | Significant impact as applications are closely tied to the logical schema. |
| Primary Benefit | Enhances performance and storage management without disrupting the database logic. | Allows structural changes to the data without affecting user interfaces or applications. |
| Challenges | Few challenges as it mainly deals with storage upgrades. | Difficult to implement due to dependency on application programs. |
| Overall Goal | To improve the performance and efficiency of data storage. | To maintain flexibility and adaptability of the database structure. |
Real-World Applications and Use Cases of Data Independence in DBMS
Think about online retailers. They often need to add new product categories or update existing ones.
With Logical Data Independence, they can do this without affecting the user interface. Imagine adding a “Reviews” section to a “Products” table. This change won’t disrupt the shopping experience for customers.
Now, consider Physical Data Independence. An e-commerce site may switch from hard drives to SSDs for faster performance. This upgrade happens without any changes to the database logic or user interface.
These examples show how data independence helps businesses stay agile and responsive.
The Role of Metadata in Achieving Data Independence in DBMS
Metadata is data about data. It helps manage and locate information within a database.
Think of metadata as a librarian. It knows where every book (data) is and how to find it. This organisation makes it easy to change things without losing track of where everything is.
For Physical Data Independence, metadata helps map the physical storage to the logical structure. This way, changes in storage don’t mess with how data is organised logically.
For Logical Data Independence, metadata maps the logical schema to the external schema. This mapping allows changes in data structure without affecting how users interact with it.
In short, metadata is the glue that holds everything together.
Impact of Data Independence on Database Design and Development
Data independence greatly influences how databases are designed and developed.
Design Phase:
- Designers can focus on creating a robust logical schema.
- They don’t worry about physical storage details.
- This separation allows for cleaner, more efficient designs.
Development Phase:
- Developers can write code without worrying about future changes to the database structure.
- Changes at the physical level won’t break the application logic.
- This makes development faster and more reliable.
Maintenance:
- Updating the database becomes easier.
- Changes at one level don’t require a complete overhaul.
- This reduces downtime and improves performance.
Consider a hospital database. Initially, it stores patient records on local servers. Later, it switches to cloud storage for better scalability.
With Physical Data Independence, this switch doesn’t affect the database’s logical structure or the applications accessing it.
Similarly, if the hospital decides to add new fields to the patient records, Logical Data Independence ensures that existing applications and user interfaces remain unaffected.
Benefits and Advantages of Implementing Data Independence in DBMS
Ever wondered why data independence in DBMS is such a big deal? Let’s break it down.
Enhanced Data Quality
Data independence boosts the quality of your data. When we separate data from applications, we avoid data duplication. This means our data remains accurate and consistent.
Cost-Effective Maintenance
Maintaining a database can be expensive. But with data independence, we can make changes at one level without touching other levels. This saves time and reduces costs.
Improved Security
Data independence enhances security. We can enforce security protocols at different levels without affecting the whole system. This layered approach makes our data more secure.
Reduced Data Redundancy
Redundancy wastes space and resources. Data independence in DBMS helps us avoid storing the same data multiple times. This makes our databases more efficient.
Increased Performance
Optimised storage and retrieval processes boost performance. With physical data independence, we can change storage methods to improve speed. Logical data independence ensures applications run smoothly even when data structures change.
Challenges in Achieving Data Independence and How to Overcome Them
Data independence sounds great, but it’s not always easy to achieve. Here are some common challenges and how we can tackle them.
Logical Data Independence Challenges
Logical data independence can be tricky. Applications are often closely tied to the logical schema. Even small changes can require updates to the application code.
How to Overcome It:
- Use Abstraction Layers: Abstraction layers help separate the application from the database structure.
- Modular Design: Design applications in a modular way. This makes it easier to update parts without affecting the whole system.
Physical Data Independence Challenges
Physical data independence is generally easier but still has its hurdles. Changing storage methods or hardware can disrupt operations.
How to Overcome It:
- Plan Ahead: Anticipate changes and plan for them. Regular updates and backups can minimise disruptions.
- Use Flexible Tools: Use DBMS tools that support easy changes to physical storage without affecting the logical schema.
Conclusion
Data independence in DBMS is vital for flexible, scalable, and secure database systems. By separating different levels of the database, we ensure easier maintenance, better performance, and higher data quality.
In this blog, we explored the significance of data independence in DBMS. We learned how logical and physical data independence enhance database flexibility and efficiency. Understanding and implementing data independence can transform how we manage our databases.
By understanding and applying data independence in DBMS, businesses can adapt swiftly to changes, improve performance, and reduce maintenance costs, ultimately leading to a more resilient and efficient database management system.
What is the main difference between logical and physical data independence?
Why is logical data independence harder to achieve than physical data independence?
How does data independence improve database security?
Can you provide an example of physical data independence in action?
How does data independence contribute to cost-effective database maintenance?
Updated on January 28, 2025