
Every business generates data; however, if data comes raw, it is just a lot of numbers until we arrange, examine, and make it useful. That is where the data warehouse comes in.
A data warehouse, therefore, goes beyond being a location for storing data. Instead, it refers to a system where data from diverse origins are collected, cleaned, and rendered ready for analytical use. It mainly helps the organisation make fact-based decision making rather than guesses.
But here’s the twist—it’s not exactly the same for everyone. Data warehouses are fast, scalable, and secure. That’s why the three-tier architecture of data warehouse is preferred – it manages the complexities into layered work and streamlines data flow from storage to analysis.
Let’s unpack it layer by layer and then see how efficiency and insight can be achieved with proper data handling.
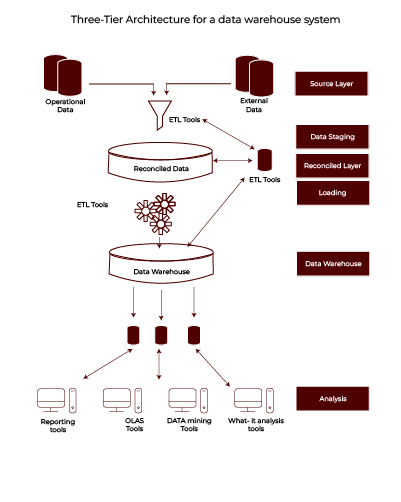
Overview of the Three-Tier Architecture of Data Warehouse
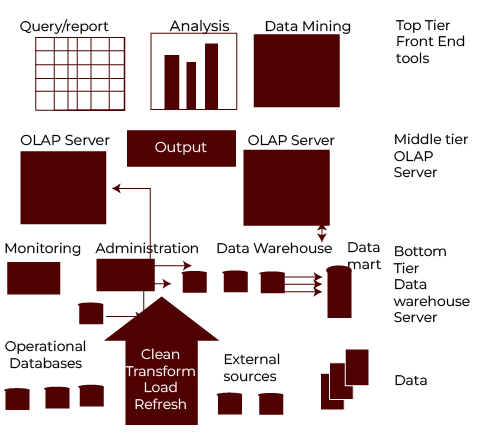
The three-tier architecture is like a well-organised office. Each floor has a specific role, and together, they ensure everything runs smoothly.
- Bottom Tier: This is the foundation where raw data resides. It collects and integrates data from operational systems and external sources.
- Middle Tier: This is the brain, where the data is processed. It uses OLAP (Online Analytical Processing) servers to crunch the numbers and prepare the data for analysis.
- Top Tier: This is the face of the system. It’s where we interact with tools to visualise data, generate reports, and uncover trends.
Each tier has a defined job, and together, they make the data warehouse an efficient powerhouse for decision-making.
Also Read: Architecture of Data Warehouse

POSTGRADUATE PROGRAM IN
Data Science & AIML
Learn Data Science, AI & ML to turn raw data into powerful, predictive insights.
In-Depth Explanation of Each Tier in the Three-Tier Data Warehouse Architecture
The Bottom Tier: Core Data Storage and Integration Processes
Think of the bottom tier as a library’s storage room. It’s where data from multiple sources is gathered and stored systematically.
Here’s what happens at this layer:
- Data Collection: Pull data from internal systems like sales, HR, or inventory and external sources such as market reports.
- Data Integration: Standardise the data. Different systems often store data in varying formats. The bottom tier ensures everything aligns.
- ETL Process:
- Extract: Retrieve data from its original source.
- Transform: Clean, filter, and prepare it. For instance, standardising customer names or fixing incomplete addresses.
- Load: Store the transformed data in the warehouse for further use.
Example: A retail chain integrates data from billing systems across its outlets in India. This layer consolidates sales figures, stock levels, and customer preferences into a central repository.
The bottom tier is the backbone. Without it, the rest of the architecture wouldn’t function effectively.
The Middle Tier: The Role of OLAP Servers in Analytical Processing
This is where the magic of analysis happens. The middle tier processes data and turns it into something meaningful.
Here’s how it works:
OLAP (Online Analytical Processing) Models:
- ROLAP: Works with relational databases to handle large datasets. Ideal for businesses needing detailed reports.
- MOLAP: Uses multidimensional databases for faster query processing. Great for quick summaries or dashboards.
- HOLAP: Combines the best of both. Handles large data volumes efficiently while offering quick insights.
Example: An e-commerce platform analyses customer purchase behaviour using MOLAP. It quickly identifies trends like “demand spikes for smartphones during festive sales in Delhi.”
The middle tier bridges the gap between raw data and actionable insights. It’s the engine driving business intelligence.
The Top Tier: How Front-End Tools Empower Business Insights
The top tier is the visible part of the system. It’s what end users interact with to make sense of the data.
Here’s what happens at this layer:
- Reporting and Dashboards: Users generate custom reports or view visualisations for trends and forecasts.
- Data Mining Tools: Discover hidden patterns, like identifying which product bundles sell well together.
- User-Friendly Access: Non-technical users can explore data without needing advanced skills.
Example: A financial analyst in Bengaluru uses a dashboard to forecast quarterly revenue by analysing past sales data. They can drill down into the details, such as performance by product line or region.
This layer ensures that data isn’t just stored or processed—it’s made actionable and accessible.
Different Data Warehouse Models
Not all data warehouses are the same. They vary in size, purpose, and complexity. Here are three common models:
- Enterprise Warehouse
- A centralised system integrating data from all functions.
- Supports extensive queries and analysis for the entire organisation.
- Example: A large retail chain tracking inventory, sales, and customer trends across all stores.
- Data Mart
- A smaller, department-specific subset of the warehouse.
- Designed for quick access and targeted analysis.
- Example: A finance team analysing quarterly budgets and expenditures.
- Virtual Warehouse
- Provides on-demand views of operational data.
- Focuses on quick access rather than permanent storage.
- Example: An e-commerce company generating real-time reports on daily sales performance.
Principles of Data Warehousing
Building a data warehouse isn’t just about storage. Certain principles ensure it runs smoothly and effectively:

- Load Performance
- The warehouse must handle millions of rows quickly without delays.
- Large-scale data loads shouldn’t limit business operations.
- Load Processing
- Data undergoes multiple steps like filtering, reformatting, and indexing before storage.
- Ensures data is clean and useful.
- Data Quality Management
- Consistency and accuracy are essential, even when dealing with dirty sources.
- A robust warehouse ensures referential integrity and correct relationships between data points.
- Query Performance
- Complex queries should take seconds, not hours or days.
- Faster performance supports real-time decision-making.
- Terabyte Scalability
- Warehouses must grow with business needs.
- From gigabytes to terabytes, scalability ensures no data is left behind.
Also Read: Data Warehousing and Data Mining in Detail

82.9%
of professionals don't believe their degree can help them get ahead at work.
Key Components Supporting the Three-Tier Architecture of Data Warehouse
Wonder how business manages without getting lost in the endless stream of information? The secret lies in the key components of the three-tier architecture of data warehouse. These components work behind the scenes to keep everything running smoothly.
Let’s dive into the backbone of this architecture and see what makes it so reliable.
Metadata Repository and Its Role in Organising Data
Metadata is similar to a table of contents of any book. It basically notifies you about what’s inside without flipping through each page.
In a data warehouse, metadata serves multiple purposes:
- It defines the structure of data in the warehouse.
- It keeps track of data sources, formats, and transformations.
- It ensures everyone speaks the same language when accessing data.
For instance, in a logistics company that manages shipments across India, metadata may store information related to delivery locations, timelines, and payment methods. It ensures the coherency of data even when it comes from different systems.
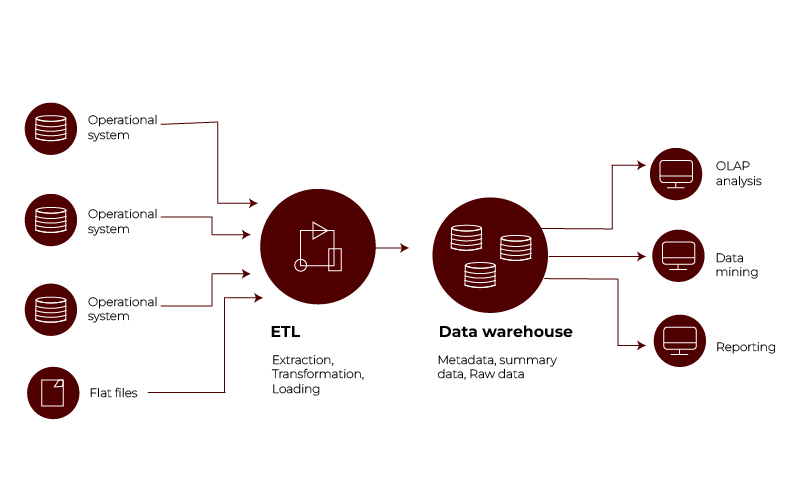
Extract, Transform, Load (ETL) Process: The Backbone of Data Warehousing
Imagine a kitchen where raw ingredients are turned into a finished dish. That’s what ETL does for your data.
Here’s how the process works:
| Extract | Transform | Load |
| Pull raw data from multiple sources, such as databases, APIs, or spreadsheets. | Clean and standardise the data. Remove duplicates, fill in missing values, and convert formats. | Push the refined data into the warehouse, ready for analysis. |
Let’s take an example: A retail company operating in Delhi, Mumbai, and Bengaluru gathers sales data from each city. During the transformation phase, ETL ensures all sales figures use the same currency and time format. This uniformity makes analysis accurate and easy.
ETL is the unsung hero that keeps the data warehouse ready for action.
Staging Areas: Temporary Spaces for Data Processing
Before entering the warehouse, data often passes through a staging area. This is where data is temporarily held for transformation and cleansing.
Benefits of staging areas include:
- Handling data from multiple sources without immediate integration.
- Prevents incomplete or inconsistent data from entering the warehouse.
- Providing a buffer to clean and standardise incoming data.
For instance, an insurance company uses a staging area to process policyholder data from different branches before integrating it into the main warehouse.
Also Read: Exploring Advantages and Disadvantages of Data Warehouse
Benefits of Implementing a Three-Tier Data Warehouse System
What makes the three-tier architecture stand out? It’s not just about structure—it’s about results.
Here are the top benefits:
1. Scalability:
- Handles growing data volumes without breaking a sweat.
- Supports an increasing number of users.
2. Separation of Concerns:
- Keeps transactional and analytical processing distinct.
- Ensures faster analysis without affecting daily operations.
3. Improved Query Performance:
- Prepares data in advance for lightning-fast queries.
- Delivers insights in seconds.
4. Flexibility:
- Adapts to new data sources easily.
- Integrates with modern tools for enhanced analysis.
5. Data Quality Assurance:
- Cleanses and standardises data before storage.
- Reduces errors and ensures reliability.
For instance, a manufacturing company tracking inventory across plants benefits from scalability and quick query performance. This allows them to predict shortages and avoid disruptions.
These benefits make the three-tier architecture a go-to choice for businesses of all sizes.
Challenges and Practical Solutions in Designing Three-Tier Data Warehouse Architecture
No system is without its challenges. While the three-tier architecture is robust, there are hurdles to overcome.
Here’s what businesses face and how they tackle it:
- Managing High Volumes of Diverse Data
- The Challenge: Handling data from various sources like apps, IoT devices, and databases can get overwhelming.
- The Solution: Use scalable ETL tools that process data efficiently. Distributed storage systems like Hadoop can help manage large data sets.
- Ensuring Data Security and Compliance
- The Challenge: Sensitive information needs protection, and regulatory standards must be met.
- The Solution: Implement strict access controls. Encrypt sensitive data and monitor user activities to ensure compliance.
- Balancing Real-Time Analytics with Batch Processing
- The Challenge: Real-time data demands quick analysis, but batch processing remains necessary for historical trends.
- The Solution: Introduce hybrid OLAP models that support both real-time and batch workloads seamlessly.
- Maintaining System Performance
- The Challenge: As user numbers grow, the system can slow down.
- The Solution: Optimise query processes and use caching mechanisms. Regularly update system hardware to match demands.
- Simplifying Data Access for Non-Technical Users
- The Challenge: Complex systems can intimidate users unfamiliar with technical tools.
- The Solution: Invest in user-friendly dashboards and reporting tools. Train employees to make the most of these systems.
For example, a hospital chain managing patient records across cities might face data security concerns. By encrypting patient data and using role-based access controls, they ensure compliance without compromising usability.
Every challenge in the three-tier architecture has a solution, making it a resilient framework for data warehousing.
Conclusion
The three-tier architecture of data warehouse is a well-structured framework that takes scattered data and transforms it into actionable insights. The layered approach ensures a smooth flow from integration to analysis, making it an ideal choice for businesses with requirements for reliable and scalable solutions.
Each tier, from basic storage to advanced analytical processing, contributes to delivering clarity out of complexity.
By utilising components such as metadata, ETL processes, and data marts, this architecture allows informed decision-making. Its benefits can be found across industries, proving to be adaptable. Even though some problems exist, practical solutions ensure that this architecture remains a cornerstone of modern data-driven strategies.
If you want to develop your skills in the application of modern technologies, Hero Vired has a Certificate Program in DevOps and Cloud Engineering for you. That takes you through all the essentials of cloud computing and modern engineering practices to build scalable, secure, and high-performing systems.
What are the three tiers in a data warehouse, and what roles do they serve?
- Bottom Tier: Handles data storage and integration from various sources.
- Middle Tier: Processes the data for analysis using OLAP servers.
- Top Tier: Provides tools for visualisation and reporting.
What is the difference between ROLAP and MOLAP in the middle tier?
- ROLAP uses relational databases for large-scale data analysis.
- MOLAP works with multidimensional databases for faster, summary-based queries.
Why is metadata important in data warehouses?
How does data mart enhance three-tier architecture?
Which industries would benefit the most from three-tier data warehouse architecture?
Updated on November 25, 2024