
Imagine that you get a dataset full of messy numbers, missing values, and hidden patterns. Where do you even start?
That’s where EDA in data science comes in.
Exploratory Data Analysis helps us uncover what the data holds- it provides a glimpse of trends, spotting anomalies, and even setting a stage for meaningful analysis. It’s a prerequisite of any solid data science project.
EDA helps us to have an understanding of raw data, whether it’s cleaning errors, visualising relationships, or determining what might be worth further investigation.
Core Objectives and Essential Benefits of EDA
Raw data hardly ever looks clean. It is messy, incomplete, and sometimes misleading. EDA shows us how to handle this mess and make sense of it.
Why does this matter?
Because every insight we gain during EDA makes our analysis sharper and our predictions stronger.
Here’s what EDA helps us achieve:
- Find patterns and trends
- Catch anomalies and errors
- Understand relationships
- Clean the data
Also Read: The Most Useful Data Science Tools

POSTGRADUATE PROGRAM IN
Multi Cloud Architecture & DevOps
Master cloud architecture, DevOps practices, and automation to build scalable, resilient systems.
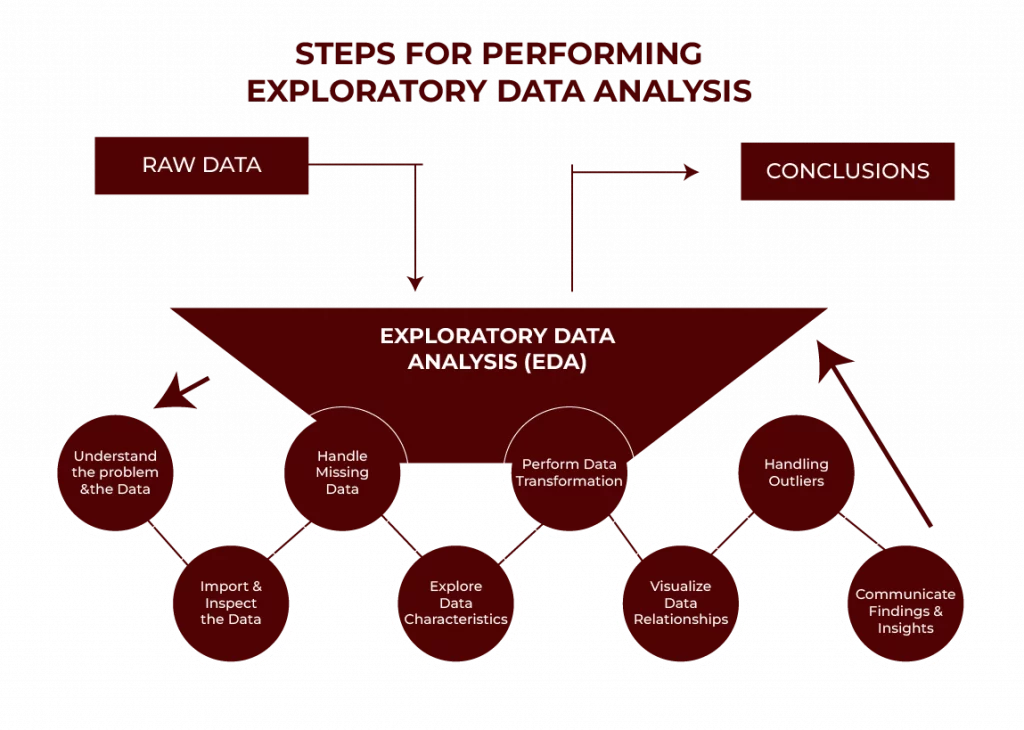
Step-by-Step Guide to Conducting Exploratory Data Analysis
1. Familiarise Yourself with the Data
- Look at the dataset. What do the columns represent? Are the values numerical, categorical, or dates?
- Get a quick overview of the data shape. How many rows and columns are we dealing with?
- Identify key questions the data should answer. For example:
- What’s the range of sales across regions?
- Are there correlations between age and spending habits?
2. Perform Initial Data Exploration
- Start with descriptive statistics:
- What’s the mean, median, and range for each column?
- Which variables have missing values, and how many?
- Use visual tools to spot patterns:
- Bar charts to see frequency distributions.
- Box plots to identify outliers.
3. Handle Missing Values
Data gaps can derail your analysis. Here’s how we can fix them:
- Fill missing values with averages or medians for numerical data.
- For categorical data, use the most frequent value or create a “missing” category.
- If a column has too many blanks, consider dropping it altogether.
4. Detect and Handle Outliers
Outliers can distort the results. For instance, an unusually high transaction value could be an error—or a special case worth exploring.
- Identify outliers:
- Use box plots to spot extreme values.
- Calculate Z-scores to find values far from the mean.
- Decide what to do:
- Remove errors, like typos or incorrect entries.
- Keep valid outliers if they provide valuable insights.
5. Visualise Relationships
- Use scatter plots to explore how two variables interact. For example, do sales increase with higher advertising spend?
- Try heatmaps to see correlations between multiple variables at once.
6. Summarise Findings
- Write down what you discovered, like:
- “Most customers are aged between 25-40.”
- “Sales peak during November and December.”
- “Outliers in revenue are linked to festive promotions.”
Example: Analysing Sales Data
Let’s say we’re looking at a dataset for a retail chain in India. The columns include Product, Region, Month, and Sales.
Here’s how EDA could work:
- Start by calculating the average sales per region.
- Use a heatmap to find correlations between regions and product categories.
- Spot anomalies, like zero sales for a popular product during peak months.
Also Read: Data Science Life Cycle
Unveiling the Types of Analysis Performed During EDA
What if you wanted to look for patterns in your data but were unsure how to start? That is where the knowledge of all analysis types in EDA in data science comes in.
Every data set has a story. Whether it be just a simple variable relationship or inter-relations of complicated kinds, it is important to know how to explore them.
Here are the four main types of analyses we make use of in EDA, along with when and how they are applied:
Univariate Analysis: Exploring One Variable at a Time
Univariate analysis focuses on understanding individual variables. We look at their distributions, central tendencies, and variability.
For instance, to analyse the Monthly Sales of a product, we might use:
- Histograms to see how sales vary over months.
- Box plots to identify outliers in the dataset.
Bivariate Analysis: Relationships Between Two Variables
Bivariate analysis digs into how two variables are connected.
For instance:
- Scatter plots can show the relationship between Marketing Spend and Revenue.
- Correlation matrices help find strong or weak relationships between variables.
Multivariate Analysis: Uncovering Patterns in Multiple Variables
When three or more variables interact, things get complex. Multivariate analysis helps uncover these relationships.
Common tools include:
- Heatmaps for visualising correlations among many variables.
- Principal Component Analysis (PCA) for reducing the number of variables without losing key information.
Time Series Analysis: Studying Data Over Time
Some data is time-sensitive, and trends can vary by day, month, or year. Time series analysis lets us track these patterns.
Key tools include:
- Line charts to view trends over time.
- Lag plots to see how past values affect future trends.
Descriptive Statistics: A Quick Overview of the Data
Descriptive statistics summarise data into digestible numbers. Key measures include:
- Mean, median, and mode to understand central tendencies.
- Variance and standard deviation to assess variability.
- Percentiles and quartiles to identify data spread.
Graphical Analysis: Insights Through Visualisations
Data visualisation is the backbone of EDA. Popular tools include:
- Box plots for variability.
- Scatter plots for relationships.
- Bar charts for categorical data comparisons.
Dimensionality Reduction: Simplifying Complex Data
Large datasets can be overwhelming. Dimensionality reduction simplifies data while preserving its core insights.
Key techniques include:
- Principal Component Analysis (PCA) to combine variables.
- t-SNE to visualise data in fewer dimensions.
Statistical Summaries and Techniques for Handling Data Issues
Data often comes with its fair share of problems. Missing values, outliers, and inconsistencies can throw off our analysis. Tackling these issues is a big part of EDA.
Summarising Data for Quick Insights
Statistical summaries give us a snapshot of the dataset. Some key measures include:
- Mean and median to understand central tendencies.
- Standard deviation to assess data variability.
- Percentiles to identify extremes in data distributions.
Handling Missing Values
Missing data can distort results, so we must address it carefully.
- For numerical data: Use mean or median values to fill gaps.
- For categorical data: Add a “missing” label or use the most frequent value.
- For extreme cases: Drop columns or rows with too many blanks.
Identifying and Managing Outliers
Outliers can skew results but often carry valuable information.
To detect outliers:
- Use box plots to visualise extreme values.
- Calculate Z-scores to measure how far values deviate from the mean.
Deciding what to do depends on the context:
- Remove data-entry errors.
- Retain valid but extreme values for further study.

82.9%
of professionals don't believe their degree can help them get ahead at work.
Visualisation Methods That Simplify Complex Data Insights
Numbers alone can’t always tell the whole story. Visualisations make it easier to spot trends, relationships, and anomalies.
Here are the top visualisation techniques in EDA in data science:
| Category | Visualisation Type | Purpose | Example |
| Simple Yet Powerful Visuals | Histograms | Show how data is distributed. | Display age distribution for a customer base. |
| Box plots | Highlight outliers and variability. | Compare salaries across job roles. | |
| Relationships Between Variables | Scatter plots | Reveal correlations between two variables. | Plotting advertising spend versus sales. |
| Heatmaps | Provide an overview of multiple correlations. | Identify strong relationships in a product sales dataset. | |
| Advanced Visuals for Complex Insights | Pair plots | Combine scatter plots for multiple variables. | Analyse customer demographics like age, income, and spending. |
| Violin plots | Show distributions and variabilities together. | Compare test scores across student groups. | |
| Time-Specific Visuals | Line charts | Perfect for tracking trends over time. | Daily website traffic for a month. |
| Lag plots | Detect patterns in sequential data. | Predicting stock prices based on past performance. |
Essential Tools and Platforms Used for EDA in Data Science
Python Libraries for Efficiency
- Pandas: Handle and manipulate structured data effortlessly.
- Matplotlib and Seaborn: Create stunning, insightful visuals.
- Scipy: Perform advanced statistical calculations.
R Packages for Advanced Users
- ggplot2: Known for its flexibility and beautiful visualisations.
- dplyr: Simplifies data manipulation tasks like filtering and grouping.
- tidyr: Reshapes messy datasets into structured formats.
Interactive Platforms for Non-Coders
- Tableau: Drag-and-drop simplicity for building interactive dashboards.
- Power BI: Connects to various data sources for real-time analysis.
Basic Tools for Small-Scale Analysis
- Excel: Still a go-to for smaller datasets, especially for basic calculations and charts.
Illustrative Examples of Applying EDA in Data Science Projects
Imagine you’re sitting with a dataset in front of you. Where do you start? What if you miss a critical insight? These questions are common, but EDA in data science has the answers.
Here are three practical examples to show how EDA works in real projects.
Example 1: Analysing Sales Data for a Retail Chain
A retail chain in India wants to understand its sales patterns to boost revenue.
Here’s how EDA helps:
- Step 1: Identify Seasonal Trends:
- Use a line chart to visualise monthly sales.
- Spot a sales spike in October and November, likely due to Diwali shopping.
- Step 2: Detect Outliers:
- Box plots reveal unusually low sales in a few stores during peak months.
- Investigate whether it’s due to stock shortages or other issues.
- Step 3: Study Regional Performance:
- Heatmaps show that North India performs better in festive months, while South India sees consistent sales throughout the year.
Outcome: With these insights, the retailer focuses on stocking festive products earlier in high-performing regions.
Example 2: Improving Customer Retention for a Telecom Provider
A telecom company wants to reduce customer churn.
Here’s the EDA process:
- Step 1: Explore Customer Demographics:
- Histograms show the age distribution of customers.
- Young adults (18–30) form the largest group.
- Step 2: Analyse Churn Drivers:
- Scatter plots reveal a correlation between high data usage and churn.
- Customers with low plan benefits are leaving for better offers.
- Step 3: Segment Customer Behaviour:
- Pair plots show that customers with higher monthly bills are less likely to churn if they receive loyalty rewards.
Outcome: The company launches data-heavy plans with loyalty perks for younger users, reducing churn significantly.
Example 3: Enhancing Traffic Flow in Urban Areas
A city’s traffic department wants to optimise road traffic during peak hours.
Here’s how EDA plays out:
- Step 1: Analyse Traffic Volume:
- Line charts reveal peak traffic hours: 8–10 AM and 5–7 PM.
- Step 2: Identify Accident Hotspots:
- Scatter plots map accident-prone areas, highlighting specific junctions.
- Step 3: Study Time-Based Patterns:
- Heatmaps show that accidents increase during rainy days in monsoon months.
Outcome: The city implements traffic signals at high-risk areas and plans alternate routes for peak hours.
Expert Tips and Best Practices for Maximising the Impact of EDA
When you dive into EDA in data science, keep these tips in mind to make your analysis sharp and impactful.
Start with Clear Questions
Before you open a single file, know what you’re looking for.
- What trends do you want to uncover?
- Which variables are likely to matter the most?
Combine Statistics with Visuals
Numbers alone won’t tell the whole story.
- Use summary statistics for quick insights.
- Add visual tools like heatmaps or scatter plots to see relationships clearly.
Don’t Ignore Missing Data
Handle gaps in your dataset carefully.
- Fill them with averages or medians if possible.
- If the missing data skews the results, document it and adjust accordingly.
Iterate as You Learn
EDA isn’t a one-time task.
- Go back and refine your analysis as new insights emerge.
- Try different tools and techniques to dig deeper.
Document Your Findings
Keep a clear record of what you’ve discovered.
- Include charts, key statistics, and notes.
- This ensures your analysis is reproducible and easy to share.
Conclusion
Exploratory Data Analysis is the bridge between raw data and actionable insights.
It sets the basis of data science by uncovering patterns, relationships, and anomalies in a way that ensures that data can be used for deeper analysis. This goes from univariate analysis to advanced multivariate techniques, which tends to provide clarity for decision-making.
Tools like Python, R, or visualization platforms make it efficient and accessible.
And so, through the clear articulation of questions, employing the right tools, and iterating for insight, EDA in data science turns complex data into meaningful narratives that can leverage smarter strategies toward impactful outcomes.
Are you ready to bring your data skills to the next level? Hero Vired’s Accelerator Program in Business Analytics & Data Science is here for you. Designed to arm you with hands-on experience in EDA, data science tools, and advanced analytics techniques for smarter decision-making, this course shall see you through.
What is the purpose of EDA in data science?
How does EDA differ from data cleaning?
Which tools are best for EDA?
- Python libraries: Pandas, Matplotlib, and Seaborn.
- R packages: ggplot2 and dplyr.
- Tableau and Excel for beginners.
How does EDA improve machine learning models?
- Selecting relevant features.
- Identifying outliers.
- Understanding variable relationships, which improves model accuracy.
What are common challenges during EDA?
- Dealing with missing data.
- Interpreting outliers correctly.
- Ensuring visualisations are clear and actionable.
Updated on November 21, 2024