
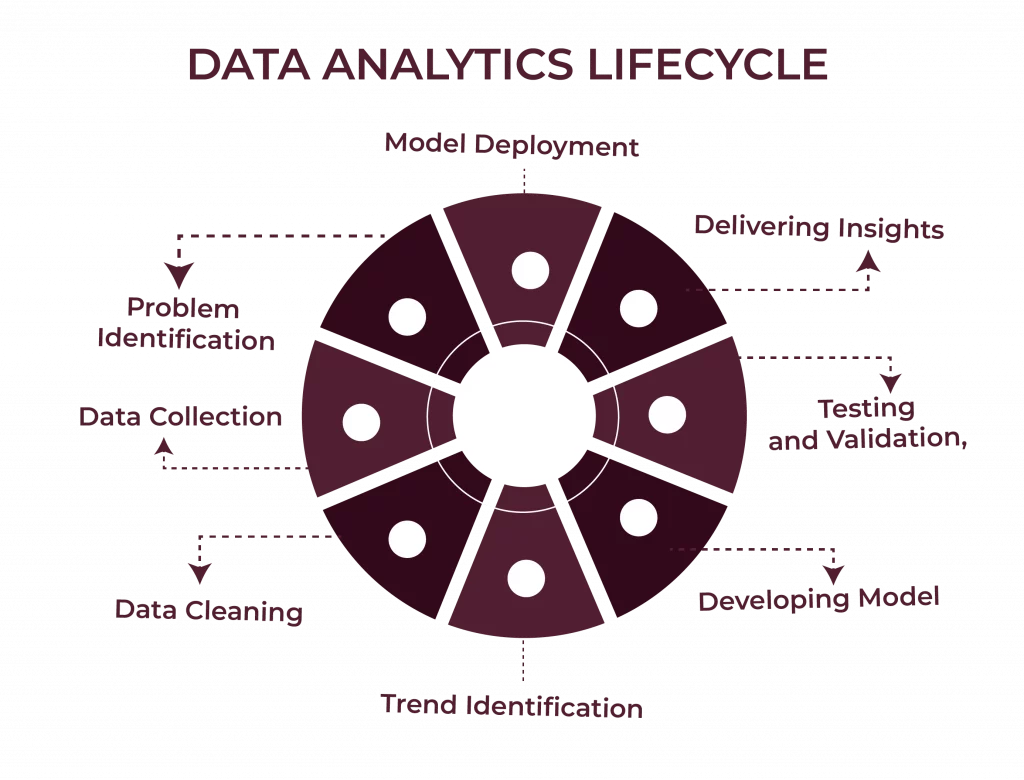
The data analytics lifecycle is a structured set of activities that transforms unrefined data into actionable information, enabling organisations to make informed decisions and attain measurable outcomes. It is the backbone of modern decision-making.
Organisations can address complex challenges, optimise operations, and unlock hidden opportunities by masterminding this lifecycle.
The adoption of data analytics across the whole world is tremendous, particularly in industries such as retail, healthcare, and logistics. For example, Zomato has tailored customer recommendations with data analytics and Flipkart has streamlined inventory management to cater for consumer needs. These applications demonstrate how this framework can be applied to solve particular business problems.
The following article is an analysis of the different stages involved in the data analytics lifecycle and how each stage plays a role in transforming raw data into meaningful solutions. Whether it is to streamline processes, reduce costs, or improve customer experiences, this life cycle provides the fundamental foundation needed.
Setting Clear Business Goals as the Foundation of the Data Analytics Lifecycle
Everything starts with a goal. With a clear target, even the best data can feel meaningful.
- Businesses need to ask questions like:
- What challenges are we solving?
- What does success look like?
- How will this impact our bottom line?
For instance:
- Retailers like D-Mart use data analytics to predict festive shopping trends and stock shelves accordingly.
- Banks analyse customer behaviour to reduce credit card fraud.
Having clear goals ensures that the entire process stays on track. It also helps save time on irrelevant data or unnecessary analysis.
Key Steps to Define Goals:
- Identify the core problem. Is it about retaining customers, cutting costs, or improving service?
- Collaborate with team members to understand different perspectives.
- Translate the problem into a measurable objective, such as “Increase repeat customers by 15%.”
These steps lay the foundation for the data analytics lifecycle and guide every phase that follows.
Also Read: Career in Data Analytics In India

POSTGRADUATE PROGRAM IN
Data Science & AIML
Learn Data Science, AI & ML to turn raw data into powerful, predictive insights.
Phase 1: Defining Specific Problems and Building Actionable Hypotheses
After setting a goal, the next step is to define the problem. This phase involves identifying what’s causing the issue and forming a hypothesis to test.
For example:
- A logistics company might notice delivery delays. The problem could be inefficient routing. A hypothesis could be: “Using real-time traffic data will reduce delays by 25%.”
- A hospital may want to reduce patient wait times. Their hypothesis might be: “Adding an extra nurse during peak hours will lower wait times by 20%.”
Steps in This Phase:
- Investigate root causes. Ask “why” multiple times to get to the heart of the issue.
- Develop a clear hypothesis. This helps focus efforts and ensures everyone understands what’s being tested.
- Define success criteria. For example, “A successful model should reduce fraud detection errors by 15%.”
By the end of this phase, we have a roadmap for solving the problem.
Phase 2: Collecting and Organising Data to Match Business Needs
Now that we know the problem, it’s time to gather the data.
Good data is the backbone of the data analytics lifecycle. Without it, even the smartest algorithms won’t work. However, not all data is useful, so we need to collect and organise it carefully.
Common Sources of Data:
- Retail stores: Sales transactions, customer loyalty programs.
- Healthcare: Patient records, diagnostic data.
- E-commerce platforms: Website traffic, purchase histories.
| Sector | Data Sources | Example Companies |
| Retail | POS systems, customer loyalty programs | Big Bazaar, D-Mart |
| Logistics | IoT devices, GPS trackers | Blue Dart, Delhivery |
| Healthcare | Patient records, wearable devices | Apollo Hospitals, Fortis |
| E-commerce | Website analytics, purchase histories | Flipkart, Amazon India |
| Transportation | Fleet management systems, fuel trackers | Ola, Uber |
For example:
- Big Bazaar collects data from loyalty cards to analyse shopping habits.
- Apollo Hospitals use patient records to identify trends in seasonal illnesses.
Once the data is collected, the next step is to organise it:
- Clean the data: Remove duplicates and errors.
- Structure it: Arrange it in a way that’s easy to analyse.
- Fill gaps: Use averages or predictive methods to handle missing values.
Checklist for Collecting and Organising Data:
- Ensure data is relevant to the problem being solved.
- Verify its accuracy and completeness.
- Store it in a format that’s compatible with analysis tools.
Phase 3: Cleaning and Preparing Data to Ensure Analytical Accuracy
Data can be messy. It can be duplicate entries, missing values, or inconsistent formats.
The data cleaning phase ensures everything is in order before we dive into analysis. Without it, even the best models can give flawed results.
What does cleaning involve?
- Removing duplicates: For instance, if a customer’s purchase is recorded twice, it needs to be fixed.
- Handling missing data: Replace empty fields with averages, medians, or other estimates.
- Standardising formats: Ensure dates, currencies, and categories follow a consistent style.
Let’s take an example. A bank analysing loan applications may find that some records are incomplete. Filling in missing credit scores with the average score ensures the analysis isn’t skewed.
Once cleaned, the data must be prepared for analysis. This involves:
- Feature engineering: Creating new variables that help in better predictions.
- Normalisation: Scaling values so they fit within a specific range.
For example, Flipkart might create a “return rate” metric by dividing returned items by total orders. This feature can predict the likelihood of future returns.
Data preparation is the bridge between raw information and meaningful insights.

82.9%
of professionals don't believe their degree can help them get ahead at work.
Phase 4: Exploring Data to Identify Trends and Key Relationships
Once the data is clean, we can start exploring it to find patterns.
Why is exploration important?
It’s where we uncover trends, relationships, and anomalies. Think of it as digging through a treasure chest to find the gems.
Tools we can use:
- Heatmaps: Great for visualising correlations between variables.
- Scatter plots: Help us understand relationships between two data points.
- Box plots: Highlight outliers and variations in the data.
Let’s take an example. A hospital exploring patient data may discover a trend where seasonal flu cases spike in December. This insight can help them prepare resources in advance.
Key questions to ask during this phase:
- Are there any unexpected trends?
- Do any variables stand out as highly correlated?
- Are there any outliers that need investigation?
This phase often leads to insights that shape how we approach the next steps.
Also Read: Top 20 Data Analytics Projects
Phase 5: Developing Analytical Models Aligned with Business Objectives
Now, it’s time to build models that can answer our business questions. Models are like recipes—they help us combine ingredients (data) to create something meaningful.
What types of models can we use?
- Regression models: Predict continuous outcomes like sales or revenue.
- Classification models: Categorise data, such as predicting whether a customer will churn or not.
- Clustering models: Group similar items, like segmenting customers based on purchasing behaviour.
Take the case of Ola. They use clustering models to group areas with high ride demand, helping drivers position themselves better.
Steps in model development:
- Choose the right model: Match the model to the business goal.
- Train the model: Use historical data to teach the model how to make predictions.
- Validate the model: Test its performance to ensure accuracy.
For example, a telecom company predicting customer churn might use a classification model. Variables like call drop rates, billing complaints, and subscription plans could feed into the model.
Good models are precise and aligned with the goals set in earlier phases.
Phase 6: Testing and Validating Models for Reliable Predictions
Before deploying a model, it must be tested thoroughly. A poorly validated model can lead to costly mistakes.
What does validation involve?
- Split testing: Divide the data into training and testing sets.
- Cross-validation: Test the model’s performance across different data segments.
- Performance metrics: Measures like precision, recall, and F1-score are used to evaluate accuracy.
Let’s look at an example. A fintech company predicting credit card fraud might test their model on recent transaction data. The goal is to ensure it flags fraud accurately without too many false positives.
Key metrics to track:
- Accuracy: How often the model gets it right.
- Precision: The proportion of true positives among predicted positives.
- Recall: The proportion of actual positives correctly identified.
Testing ensures the model is not just accurate but reliable in real-world scenarios.
Phase 7: Delivering Insights Through Visualisations and Reports
The final step is communicating what we’ve learned. A brilliant analysis means little if it can’t be understood by decision-makers.
How do we present insights?
- Dashboards: Interactive tools for tracking metrics in real time.
- Charts and graphs: Visual summaries that simplify complex data.
- Narratives: Written explanations that connect insights to business goals.
Take the case of Apollo Hospitals. They use dashboards to track patient wait times and identify bottlenecks in their processes.
Popular tools for visualisation:
- Tableau: Great for creating interactive dashboards.
- Power BI: Ideal for business-focused reports.
- Google Data Studio: A free tool for simple visualisations.
Tips for effective reporting:
- Keep it simple: Focus on the key metrics that matter.
- Use visuals: A well-designed chart often speaks louder than words.
- Link insights to actions: Explain how the findings solve the problem.
For example, a retail chain might use a heatmap to show sales performance across different regions. This could help them identify where to focus their next marketing campaign.
Providing insights would mean making data understandable, applicable, and easily interpretable.
Also Read: Data Analyst Course Syllabus
Phase 8: Deploying Models and Performance Monitoring in Business Solutions
How can we ensure that the tremendous effort put into creating models pays off? The deployment stage is where theory is put into actual practice.
Deploying a model means putting it into the systems and processes that teams use daily. It’s about making predictions and decisions happen in real time.
Think about Zomato. They use predictive models to personalise food recommendations while monitoring these models to keep suggestions fresh and relevant.
Here’s how deployment works:
- Embed the model into workflows: For example, integrate a pricing model directly into an e-commerce platform’s checkout system.
- Run pilot tests: Start small, validate results, and tweak the model as needed.
- Monitor performance: Track metrics like accuracy and speed to make sure it’s working as expected.
Once deployed, the real work begins—monitoring and maintaining the model. Models can degrade over time, especially as data patterns change.
For instance:
- A telecom provider might deploy a network optimisation model. If usage trends shift, the model may need retraining.
- A retailer using a demand forecasting model might update it with new holiday sales data.
Key actions for monitoring models:
- Measure ongoing performance with metrics like recall and precision.
- Retrain models regularly to keep them up to date.
- Get feedback from users to improve accuracy and usability.
With monitoring, even the best models can maintain their effectiveness.
The Role of Feedback Loops in Continuous Analytics Improvement
How do we keep getting better? Feedback loops make this possible.
A feedback loop uses the results of a model to refine and improve it. It’s like learning from mistakes and doing better each time.
For example:
- Smart home devices like Nest learn user preferences over time, adjusting energy usage patterns for maximum efficiency.
- Logistics companies use route optimisation models, fine-tuning them based on real-world delivery times.
Why are feedback loops important?
- They ensure the model stays relevant as business needs change.
- They allow the system to adapt to new data or scenarios.
- They create a cycle of continuous improvement.
Feedback is collected through monitoring systems, user input, and updated data. This phase is key to building smarter, more effective systems.
Benefits of a Structured Data Analytics Lifecycle for Competitive Advantage
What makes the data analytics lifecycle worth the effort? The benefits are clear and significant.
Here’s what businesses gain by following the lifecycle:
- Better decision-making: Clear insights reduce guesswork.
- Improved efficiency: Streamlined processes save time and resources.
- Enhanced customer experiences: Personalisation keeps customers happy.
Take these examples:
- Flipkart uses analytics to optimise inventory, reducing overstock and shortages.
- Apollo Hospitals leverages data to cut patient wait times.
Let’s break it down further:
- Predictive power: Forecast trends, like a spike in demand during the festive season.
- Operational cost savings: Identify inefficiencies and eliminate them.
- Risk management: Spot potential issues before they escalate.
This structured approach ensures businesses don’t just analyse data—they make the most of it.
Also Read: Top 80+ Data Analytics Interview Questions with Answers
Conclusion
The data analytics lifecycle, therefore, forms an elaborate framework that transforms raw data into actionable insights, thereby helping in more informed business decisions.
Following its structured stages, cleaning and preparation, trend exploration, model building and validation, and solution deployment allow businesses to tackle issues properly. From enhancing customer experience to operations optimisation, this lifecycle ensures that data is being used as a meaningful tool for growth.
Importantly, continuous feedback loops and monitoring ensure that models remain relevant in dynamic environments.
Whether predicting customer behaviour or optimising processes, embracing the data analytics lifecycle enables businesses to sustain competitiveness and change. This methodology applies not only to such a technology powerhouse but to any organisation willing to tap into the full potential of data.
To get hands-on experience, the Certification Program in Data Analytics by Hero Vired can be considered. The curriculum makes you industry-relevant with practical knowledge and tools that will help you navigate the entire cycle confidently. Whether a beginner or an upskilled, it is your gateway to becoming a data-driven decision-maker.
What industries benefit the most from the data analytics lifecycle?
- Retail: Optimising inventory and sales strategies.
- Healthcare: Reducing patient wait times and improving diagnoses.
- Logistics: Streamlining delivery routes.
How do businesses handle outdated models?
What are the common tools used in the data analytics lifecycle?
- Python and R for data analysis.
- Tableau for visualisation.
- Power BI for reporting and dashboards.
How does exploratory data analysis fit into the lifecycle?
What challenges do small businesses face in implementing the lifecycle?
Updated on December 5, 2024